↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
많은 과학적 발견은 가설 제안, 실험 설계, 데이터 수집, 가설 수정이라는 반복적인 과정을 통해 이루어집니다. 최근 대규모 언어 모델(LLM) 기반 과학적 에이전트가 과학적 발견을 가속화할 수 있는 잠재력을 보여주고 있지만, 이들의 능력을 체계적으로 평가하는 벤치마크는 부족했습니다. 이 논문은 이러한 문제를 해결하기 위해 BoxingGym이라는 새로운 벤치마크를 제시합니다.
BoxingGym은 10가지 환경을 제공하여 실험 설계 및 모델 발견 능력을 평가합니다. 각 환경은 생성적 확률 모델로 구현되어, 에이전트가 상호 작용적인 실험을 수행할 수 있도록 합니다. **예상 정보 이득(EIG)**을 사용하여 실험 데이터의 유용성을 정량적으로 평가하고, 설명 기반 평가를 통해 모델 발견 능력을 평가합니다. 실험 결과, 기존 LLM은 실험 설계와 모델 발견에서 어려움을 겪는다는 것을 보여주었습니다. 이는 LLM 기반 과학적 에이전트의 발전 방향을 제시하는 중요한 연구입니다.
Key Takeaways#
Why does it matter?#
본 논문은 자율적 과학적 에이전트의 실험 설계 및 모델 발견 능력을 종합적으로 평가하기 위한 새로운 벤치마크인 BoxingGym을 제시합니다. 이는 LLM 기반 과학적 에이전트의 한계를 보여주고, 향후 연구를 위한 새로운 가능성을 제시합니다. 자율 과학적 에이전트 분야의 연구자들에게 중요한 기여를 할 뿐만 아니라, LLM을 활용한 과학적 발견에 대한 이해를 넓히는 데 기여할 것으로 예상됩니다. 또한, 통합적 과학적 발견 파이프라인 내에서 에이전트의 능력을 평가하는 방법론을 제시하여, 실험 설계와 모델 발견을 통합적으로 연구하는 데 중요한 발판을 마련합니다.
Visual Insights#

🔼 BoxingGym 프레임워크는 과학적 발견 파이프라인에서 과학적 에이전트의 능력을 종합적으로 평가하기 위해 고안되었습니다. 사용자는 과학적 에이전트를 위한 목표를 정의하고, 에이전트는 이론을 제시하고, 시뮬레이션된 환경에서 상호 작용하여 데이터를 수집하고, 새로운 이론을 제시하고 기존 이론을 개선합니다. 반복적인 과정을 거친 후, 과학자 에이전트는 초보자에게 그 결과를 설명하고, 목표 달성 여부는 예측 문제로 평가합니다. 이 프레임워크는 과학적 이론, 실험 설계, 모델 발견에 대한 과학자의 능력을 평가하도록 설계되었습니다.
read the caption
Figure 1: Overview of BoxingGym. The BoxingGym Framework is designed to holistically evaluate experimental design and model discovery capabilities in the spirit of George Box [6]. 1) The process starts with a user defining a goal for the scientist agent. 2) The scientist formulates a theory. 3) This theory guides the experimental design, where the scientist interacts with a simulated world to gather new data. 4) The scientist then analyzes the new and old data to propose and refine theories. This iterative process continues for several iterations. 5) The scientist is then asked to explain the findings to a novice. 6) We evaluate the novice and the scientist by casting the goal as a prediction problem.
| Environment | Goal | Before | After | After |
|---|---|---|---|---|
| Experiments | 10 Experiments | Communication | ||
| Hyperbolic Discounting | Choice | 0.31 | 0.74 | 0.74 |
| Discount | -0.06 | -0.06 | - | |
| Location Finding | Signal | 0.96 | 1.24 | 0.97 |
| Source Location | 1.29 | -0.15 | - | |
| Death Process | Num Infected | 1.19 | 0.46 | 0.75 |
| Infection Rate | 0.13 | 1.64 | - | |
| IRT | Correctness | 0.00 | 0.00 | -0.28 |
| Dugongs | Length | 0.06 | -0.09 | -0.08 |
| Peregrines | Population | 2.29 | -0.65 | -0.63 |
| Mastectomy | Survival | 0.18 | 0.27 | 1.00 |
| Predator-Prey | Population | 0.08 | -0.45 | -0.26 |
| Emotions | Prediction | 0.74 | 0.82 | 0.87 |
| Moral Machines | Judgement | 0.32 | 0.44 | 0.60 |
🔼 표 1은 다양한 과제에 걸쳐 GPT-40의 성능을 보여줍니다. 표에는 표준화된 오차가 표시되며, 각 결과는 5회 실행의 평균입니다. 표준화된 오차는 각 과제에서 GPT-40의 성능을 평가하는 데 사용된 지표의 신뢰도를 보여주는 척도입니다. 표에는 과제의 유형(예: 과제 목표, 실험 전, 실험 후, 의사소통 후)에 따른 GPT-40의 성능이 나와 있습니다. 이 표는 본 논문의 실험 결과를 요약하여 제시합니다.
read the caption
Table 1: Performance of GPT-4o Across Different Tasks. Numbers shown are standardized errors. Errors are averaged across 5 runs.
In-depth insights#
LLM-Based Science#
LLM 기반 과학은 **대규모 언어 모델(LLM)**의 능력을 활용하여 과학적 발견 과정을 가속화하고 자동화하는 새로운 패러다임입니다. 이는 과학적 이론 제안, 실험 설계, 데이터 수집 및 분석, 이론 수정 등 과학적 발견의 핵심 단계들을 LLM의 강력한 추론 및 지식 표현 능력으로 수행하는 것을 의미합니다. 하지만, LLM이 과학적 발견에 적용될 때 발생할 수 있는 한계점도 존재합니다. LLM은 실제 세계의 복잡성을 완벽하게 반영하지 못하며, 편향된 데이터나 잘못된 정보에 기반한 결과를 생성할 수도 있습니다. 또한, LLM의 해석력 및 설명력의 부족은 과학적 발견 과정에서 중요한 통찰력을 놓치거나 오류를 유발할 수 있습니다. 따라서 LLM 기반 과학 시스템의 개발에는 LLM의 강점을 최대한 활용하면서 동시에 이러한 한계점을 최소화하기 위한 철저한 검증 및 보완이 필수적입니다. 신뢰할 수 있는 데이터 소스, 엄격한 검증 절차, 사용자의 상호 작용 및 피드백 메커니즘 등을 포함한 종합적인 접근 방식을 통해 LLM 기반 과학의 잠재력을 실현하고 과학 발전에 기여할 수 있을 것입니다. 궁극적으로, LLM 기반 과학은 인간 과학자와의 협력을 통해 과학적 발견의 효율성을 높이고 새로운 발견을 촉진할 수 있는 강력한 도구가 될 것으로 기대됩니다.
BoxingGym Design#
BoxingGym은 자율 에이전트의 실험 설계 및 모델 발견 능력을 종합적으로 평가하기 위한 유연한 프레임워크입니다. 실제 과학적 모델을 기반으로 한 10가지 환경을 통해 에이전트의 적극적인 실험 참여를 가능하게 하며, 생성 모델로 구현된 각 환경은 추론 가능한 정량적 평가를 지원합니다. 다양한 과학적 이론 표현을 수용하기 위해 유연한 언어 기반 인터페이스를 사용하며, 목표 달성을 위한 에이전트의 전략적 실험 설계를 유도하는 다양한 목표를 설정할 수 있습니다. 예상 정보 이득(EIG) 및 설명 기반 평가를 통해 에이전트의 성능을 정량적으로 평가하여, 실험 설계와 모델 발견의 통합적 평가를 가능하게 합니다. 현존하는 LLM 기반 에이전트의 한계를 드러내고, 향후 연구 방향을 제시하는 벤치마크로서의 역할을 수행합니다.
EIG & Explanations#
본 논문에서 제시된 “EIG & Explanations” 섹션은 과학적 발견 과정에서의 기계 학습 모델 평가 방식에 대한 핵심적인 내용을 담고 있습니다. 특히, **예상 정보 이득(EIG)**을 활용하여 실험 설계의 효율성을 정량적으로 평가하는 방식과, 자연어 설명을 통해 모델 발견의 질적 측면을 평가하는 방식 모두를 다루고 있습니다. 이는 단순히 정확도만을 측정하는 기존의 평가 방식을 넘어, 과학적 추론 과정 전반을 평가하고자 하는 시도로 해석됩니다. EIG는 정보 이론적 관점에서 실험의 정보량을 측정하여, 모델 파라미터에 대한 불확실성을 얼마나 줄이는지 정량화합니다. 자연어 설명은 모델의 해석성과 일반화 능력을 평가하는데, 전문가가 아닌 사람에게도 모델을 이해시킬 수 있는 설명 능력을 중요시한다는 점이 특징입니다. 두 방식의 조합을 통해, 모델의 예측 성능뿐 아니라 과학적 추론 과정의 효율성과 투명성을 종합적으로 평가하는 새로운 프레임워크를 제시합니다. 이는 인공지능 기반 과학적 발견 연구에 있어 중요한 이정표를 제시한다는 점에서 의미가 있으며, 향후 관련 연구의 발전에 크게 기여할 것으로 예상됩니다.
Agent Performance#
본 논문은 두 가지 에이전트, 즉 대규모 언어 모델(LLM) 기반 에이전트와 통계적 모델링 기능을 추가한 에이전트의 성능을 다양한 과학적 과제에서 평가합니다. LLM 기반 에이전트는 실험 설계 및 모델 발견 과제에서 어려움을 겪는 반면, 통계적 모델링 기능을 추가한 에이전트는 일부 과제에서 성능 향상을 보입니다. 하지만, 데이터 부족 시점에서의 모델 과적합 및 단순 기능 형태의 모델 선호 경향이 나타납니다. 자연어 기반 설명을 통한 의사소통 기반 평가는 에이전트의 모델 발견 능력을 평가하는 유용한 방법으로 제시되나, 모든 환경에서 일관적인 성능 향상을 보이지는 않습니다. 전반적으로, 두 에이전트 모두 과학적 문제 해결에 있어 여전히 어려움을 겪고 있으며, 향후 연구를 통해 개선이 필요함을 시사합니다.
Future Research#
미래 연구 방향에 대한 심도있는 고찰은 본 논문의 핵심적인 부분입니다. BoxingGym의 확장성은 다양한 과학 분야로의 적용 가능성을 시사하며, 실제 과학적 탐구의 복잡성을 더욱 잘 반영하는 방향으로의 발전이 필요합니다. 특히, 시간 및 비용 제약, 실험 설계의 자율성, 다양한 과학 분야의 포괄적인 벤치마킹 등은 향후 연구에서 중점적으로 다뤄야 할 과제입니다. 인간의 의사결정 과정을 더욱 정교하게 모방한 환경 구축을 통해 현실적인 과학적 탐구를 더욱 충실히 반영해야 합니다. **다양한 인터페이스 (데이터 시각화, 심층적 시뮬레이션 등)**를 활용한 연구는 인공지능 에이전트의 이해도 및 예측 성능을 향상시킬 수 있습니다. 통계적 모델링과 자연어 처리 기술의 결합은 과학적 발견의 자동화 과정에 혁신을 가져올 수 있으며, 이러한 기술의 발전과 함께 BoxingGym의 벤치마크 기능 또한 지속적인 업데이트가 필요합니다. 마지막으로, 실험 설계와 모델 발견의 통합적 평가 방식을 개선함으로써, 실제 과학적 연구에 더욱 가까운 평가 체계를 구축하는 것이 중요합니다.
More visual insights#
More on figures
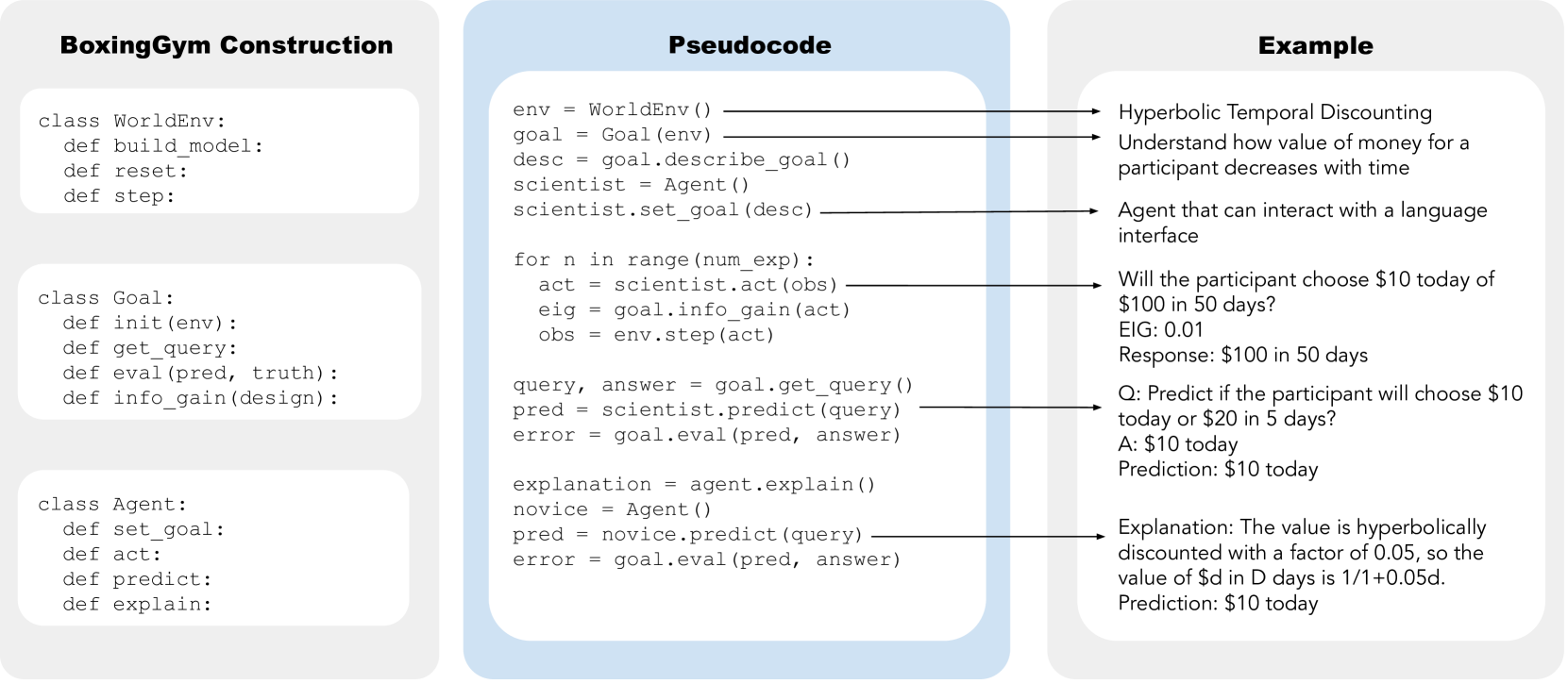
🔼 그림 2는 BoxingGym의 구조와 작동 방식을 보여주는 Python 의사 코드 예시입니다. 왼쪽에는 환경(WorldEnv), 목표(Goal), 그리고 작용자(Agent)를 위한 모듈 클래스와 메서드로 BoxingGym을 인스턴스화하는 방법을 보여줍니다. 가운데는 목표 설정, 실험 수행, 결과 예측, 설명 제공이라는 워크플로를 보여주는 의사 코드가 있습니다. 오른쪽은 과잉 시간 할인이라는 예시로, 작용자가 즉각적인 보상과 지연된 보상 중에서 선택하는 참가자의 선택을 예측하고 그 개념을 초보자에게 설명하는 방법을 보여줍니다.
read the caption
Figure 2: Python pseudocode examples. (left) BoxingGym is instantiated as modular classes and methods for the environment (WorldEnv), goals (Goal), and agents (Agent). (center) Pseudocode illustrating the workflow of setting goals, performing experiments, predicting outcomes, and providing explanations. (right) An example, hyperbolic temporal discounting, where the agent predicts a participant’s choice between immediate and delayed rewards and explains the concept to a novice.

🔼 그림 3은 두 가지 방법(GPT-40와 Box’s Apprentice)으로 과학적 모델 발견 작업을 수행했을 때의 표준화된 오차를 비교한 그래프입니다. 세 가지 과학적 영역(Peregrines, Hyperbolic Discounting, IRT)에 대한 결과가 제시되어 있으며, 각 영역별로 GPT-40(실선)과 Box’s Apprentice(점선)의 성능을 표준화된 오차를 통해 비교하고 있습니다. 오차 막대는 5회 실행에 대한 95% 신뢰구간을 나타냅니다. GPT-40과 Box’s Apprentice 모두 세 가지 도메인에 대해서 실험 전과 실험 후의 표준화된 오차가 제시되어 있습니다. 이를 통해 각 에이전트가 실험을 통해 학습하는 정도와 예측 성능 향상을 확인할 수 있습니다.
read the caption
Figure 3: Standardized errors compared. We plot the standardized errors for the two agents, gpt-4o (solid line) and Box’s Apprentice (dashed line) across three domains: Peregrines (left), Hyperbolic Discounting (center) and IRT (right). Error bars are 95% CIs across 5 runs.
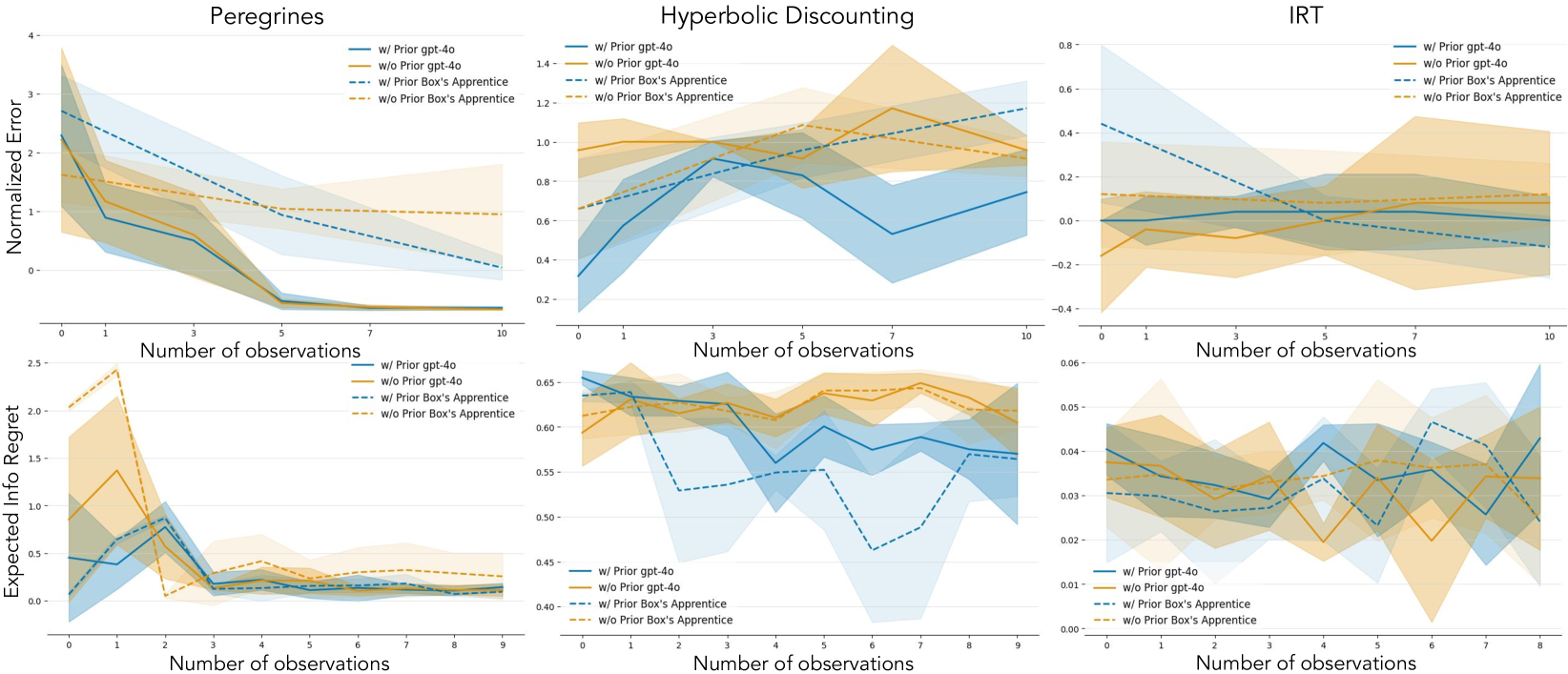
🔼 그림 4는 두 가지 에이전트(GPT-4o와 Box’s Apprentice)의 실험 설계 성능을 보여줍니다. 위쪽에는 세 가지 도메인(Peregrines, Hyperbolic Discounting, IRT)에서 각 에이전트의 표준화된 오차를, 아래쪽에는 예상 정보 이득(EIG) 후회를 나타냅니다. 표준화된 오차는 에이전트가 환경을 예측하는 정확도를, EIG 후회는 에이전트가 얼마나 효율적으로 정보를 얻는지를 나타냅니다. 각 지표는 5번의 실행에 걸쳐 95% 신뢰 구간으로 표시됩니다. 그림은 에이전트가 환경에 대한 지식이 없는 상태(Prior 없음)와 있는 상태(Prior 있음)를 비교합니다. 이를 통해 에이전트의 학습 및 적응 능력을 평가합니다.
read the caption
Figure 4: EIG regrets and standardized errors compared. We plot the standardized errors (top row) and the EIG regrets (bottom row) for the two agents, gpt-4o (solid line) and Box’s Apprentice (dashed line) across three domains: Peregrines (left), Hyperbolic Discounting (center) and IRT (right). Error bars are 95% CIs across 5 runs.
More on tables
| Environment | Goal | Before | After | After |
|---|---|---|---|---|
| Experiments | 10 Experiments | Communication | ||
| Hyperbolic Discounting | Choice | 0.66 | 1.17 | 0.66 |
| Location Finding | Signal | 0.99 | 1.45 | 1.18 |
| Death Process | Num Infected | 3.79 | -1.02 | 0.58 |
| IRT | Correctness | 0.44 | -0.12 | -0.08 |
| Dugongs | Length | 0.26 | -0.08 | -0.09 |
| Peregrines | Population | 2.71 | 0.04 | 0.97 |
| Mastectomy | Survival | 0.14 | 0.55 | 0.91 |
| Moral Machines | Judgement | 0.97 | 0.89 | 0.56 |
🔼 표 2는 Box’s Apprentice라는 에이전트의 다양한 과제에 대한 성능을 보여줍니다. 표에는 과제별 표준 오차와 함께 다양한 과제에 대한 에이전트의 성능 평가 결과가 표시되어 있습니다. 오차는 5번의 실행에 걸쳐 평균된 값입니다. 각 과제에 대해 실험 전, 실험 10회 후, 그리고 설명 후의 에이전트의 성능을 보여주어, 실험과 설명이 모델 발견 능력에 미치는 영향을 비교 분석할 수 있도록 합니다. 즉, 실험 전 예측 성능, 10회의 실험 후 예측 성능, 그리고 설명을 통한 예측 성능을 각 과제에 대해 비교하여 에이전트의 학습 및 적응 능력을 평가합니다.
read the caption
Table 2: Performance of Box’s Apprentice Across Different Tasks. Standardized errors shown here. Errors are averaged across 5 runs.
| Env | Goal | EI Regret (gpt-4o) | EI Regret (box’s apprentice) |
|---|---|---|---|
| Hyperbolic Discounting | Choice | 0.57 / 0.61 | 0.55 / 0.62 |
| Discount | 0.69 / - | - / - | |
| Location Finding | Signal | 15.3 / 11.8 | 12.6 / 15.3 |
| Source Location | 16.8 / - | - / - | |
| Death Process | Num Infected | 0.037 / 0.042 | 0.029 / 0.019 |
| Infection Rate | 0.108 / - | - / - | |
| IRT | Correctness | 0.035 / 0.031 | 0.031 / 0.033 |
| Dugongs | Length | 0.20 / 0.17 | 0.19 / 0.20 |
| Peregrines | Population | 0.26 / 0.38 | 0.25 / 0.66 |
| Mastectomy | Survival | 0.084 / 0.082 | 0.079 / 0.075 |
| Predator-Prey | Population | - / - | - / - |
| Emotions | Prediction | 0.538 / - | - / - |
| Moral Machines | Judgement | 0.046 / - | 0.045 / - |
🔼 이 표는 논문의 실험 설계 평가 부분에서 GPT-40과 Box’s Apprentice 두 가지 에이전트의 성능을 보여줍니다. 각 에이전트는 10가지 과학적 환경에서 실험을 설계하고, 그에 따른 예상 정보 이득(EIG)을 측정합니다. 표에는 각 과제에 대한 두 에이전트의 EIG 값이 제시되어 있는데, 사전 정보가 있는 경우와 없는 경우를 ‘/‘로 구분하여 나타냅니다. 이를 통해 각 에이전트의 실험 설계 능력과 사전 정보 활용 능력을 정량적으로 비교 분석할 수 있습니다.
read the caption
Table 3: EI Regrets for GPT-4o and Box’s Apprentice Across Different Tasks. EI regrets for prior and no prior conditinos are separated by ‘/’.
| Env | Goal | Error@0 | Error@10 | Discovery@10 |
|---|---|---|---|---|
| Hyperbolic Discounting | Choice | 0.31 ± 0.18, 0.96 ± 0.14 | 0.74 ± 0.21, 0.95 ± 0.07 | 0.74 ± 0.14, 1.0 ± 0.00 |
| Hyperbolic Discounting | Discount | -0.06 ± 0.00, - | -0.06 ± 0.00, - | -, - |
| Location Finding | Signal | 0.96 ± 0.58, 1.17 ± 0.60 | 1.24 ± 0.96, 0.5 ± 0.54 | 0.97 ± 0.72, 0.63 ± 0.71 |
| Location Finding | Source Location | 1.29 ± 1.3, - | -0.15 ± 0.4, - | -, - |
| Death Process | Num Infected | 1.19 ± 1.09, 0.19 ± 0.96 | 0.46 ± 0.76, 0.74 ± 1.14 | 0.75 ± 0.75, 1.61 ± 1.60 |
| Death Process | Infection Rate | 0.13 ± 0.37, - | 1.64 ± 1.12, - | -, - |
| IRT | Correctness | 0.00 ± 0.00, -0.16 ± 0.26 | 0 ± 0.11, 0.08 ± 0.32 | -0.28 ± 0.26, -0.16 ± 0.20 |
| Dugongs | Length | 0.06 ± 0.12, -0.02 ± 0.04 | -0.09 ± 0.00, -0.08 ± 0.00 | -0.08 ± 0.01, -0.08 ± 0.01 |
| Peregrines | Population | 2.29 ± 1.20, 2.21 ± 1.57 | -0.65 ± 0.03, -0.67 ± 0.01 | -0.63 ± 0.06, -0.66 ± 0.02 |
| Mastectomy | Survival | 0.18 ± 0.37, 0.00 ± 0.28 | 0.27 ± 0.19, 0.36 ± 0.27 | 1.00 ± 0.27, 0.21 ± 0.16 |
| Predator-Prey | Population | 0.08 ± 0.09, 0.73 ± 0.05 | -0.45 ± 0.02, -0.43 ± 0.02 | -0.26 ± 0.16, -0.40 ± 0.03 |
| Emotions | Prediction | 0.74 ± 0.29, - | 0.82 ± 0.34, - | 0.87 ± 0.35, - |
| Moral Machines | Judgement | 0.32 ± 0.26, - | 0.44 ± 0.16, - | 0.60 ± 0.13, - |
🔼 표 4는 GPT-40 모델이 다양한 과학적 과제를 수행했을 때의 성능을 보여줍니다. 표에는 과제 유형, 사전 정보 유무에 따른 표준화된 오차, 평균 오차가 표시됩니다. 각 과제는 5번 반복하여 평균 오차를 계산했습니다. 상단 행은 사전 정보가 있는 경우, 하단 행은 사전 정보가 없는 경우의 결과입니다.
read the caption
Table 4: Performance of GPT-4o Across Different Tasks. Numbers shown are standardized errors. Errors with prior (top line) and without prior (bottom line) appear on different lines. Errors are averaged across 5 runs.
| Env | Goal | Error@0 | Error@10 | Discovery@10 |
|---|---|---|---|---|
| Hyperbolic Discounting | Choice | 0.66 ± 0.25 0.66 ± 0.25 | 1.17 ± 0.14 0.91 ± 0.09 | 0.66 ± 0.30 0.74 ± 0.42 |
| Location Finding | Signal | 0.99 ± 0.58 1.18 ± 0.64 | 1.45 ± 1.60 0.83 ± 0.600 | 1.18 ± 1.12 -0.01 ± 0.30 |
| Death Process | Num Infected | 3.79 ± 1.68 -0.90 ± 0.05 | -1.02 ± 0.05 -0.61 ± 0.30 | 0.58 ± 0.85 0.50 ± 1.26 |
| IRT | Correctness | 0.44 ± 0.36 0.12 ± 0.24 | -0.12 ± 0.14 0.12 ± 0.14 | -0.08 ± 0.39 0.2 ± 0.40 |
| Dugongs | Length | 0.26 ± 0.12 0.05 ± 0.10 | -0.08 ± 0.02 -0.09 ± 0.004 | -0.09 ± 0.005 -0.08 ± 0.004 |
| Peregrines | Population | 2.71 ± 0.60 1.62 ± 0.47 | 0.04 ± 0.21 0.95 ± 0.86 | 0.97 ± 1.38 -0.19 ± 0.79 |
| Mastectomy | Survival | 0.14 ± 0.41 0.73 ± 0.15 | 0.55 ± 0.24 0.64 ± 0.15 | 0.91 ± 0.28 0.27 ± 0.23 |
| Moral Machines | Judgement | 0.97 ±i 0.33 | 0.89 ± 0.21 | 0.56 ± 0.18 |
🔼 표 5는 Box’s Apprentice 에이전트의 다양한 과제에 대한 성능을 보여줍니다. 표준 오차가 표시되며, 사전 정보가 있는 경우와 없는 경우의 오차가 별도로 표시됩니다. 각 값은 5번의 실행에 걸쳐 평균된 값입니다. 이 표는 에이전트가 과제를 얼마나 잘 수행했는지, 그리고 사전 정보가 에이전트의 성능에 미치는 영향을 정량적으로 보여줍니다.
read the caption
Table 5: Performance of Box’s Apprentice Across Different Tasks. Standardized errors shown here. Errors with prior (top line) and without prior (bottom line) appear on different lines. Errors are averaged across 5 runs.
| Parameter | Description |
|---|---|
| Model | Superposition of K signal sources in d-dim space |
| Setup Parameters | Num signal sources K, dim of space d, base signal b, max signal m, noise σ |
| Observations | Total noisy signal at point of measurement |
| Goals | Predicting signal intensity at new points and source locations |
🔼 표 6은 위치 찾기 환경에 대한 설명입니다. 이 환경에서는 신호를 방출하는 숨겨진 신호원이 있으며, 과학자는 다양한 지점에서 중첩된 신호를 측정할 수 있습니다. 본 실험은 포스터 등의 연구(Foster et al. [14])에서 직접적으로 가져왔습니다. 표에는 입력과 출력이 설명되어 있으며, 신호원의 위치와 신호 강도를 예측하는 것이 목표입니다. 신호 강도는 역제곱 법칙에 따라 감소하며, 배경 신호와 최대 신호 강도를 조절하는 상수가 있습니다. 포스터 등의 연구와 달리, 총 강도를 관찰합니다.
read the caption
Table 6: Location Finding
| Parameter | Description |
|---|---|
| Model | Human decision-making in temporal discounting of rewards |
| Setup Parameters | Params of the discount function (ϵ, mean and std for log k, scale for α) |
| Observations | Choice between immediate iR and delayed reward dR at delay D |
| Goals | Predicting choices and the value of the discount factor |
🔼 표 7은 과학적 발견 과정에서 실험 설계 및 모델 발견 능력을 평가하기 위한 벤치마크인 BoxingGym 프레임워크에 대한 정보를 제공합니다. 특히, 과감한 시간적 할인(Hyperbolic Temporal Discounting) 환경에 대해 설명합니다. 이 환경에서 과학자 에이전트는 참가자의 즉각적인 보상과 지연된 보상 간의 선택을 관찰하여 참가자의 시간적 할인 요소를 이해해야 합니다. 표에는 모델의 매개변수, 관찰값, 목표가 포함되어 있습니다.
read the caption
Table 7: Hyperbolic Discounting
| Parameter | Description |
|---|---|
| Model | The spread of an infection over time |
| Setup Parameters | Pop size , params of the infetion rate (, , upper and lower bounds) |
| Observations | Number of infected individuals at observation time |
| Goals | Predicting the number of infected individuals at a time and the infection rate |
🔼 표 8은 BoxingGym 벤치마크의 환경 중 하나인 ‘Death Process’ 환경에 대한 설명을 담고 있습니다. 이 환경은 시간에 따라 건강한 개체군 내에서 감염이 확산되는 과정을 모델링합니다. 표에는 모델, 설정 매개변수, 관찰값, 목표 등이 포함되어 있어 Death Process 환경을 정의하는 데 필요한 요소들을 종합적으로 보여줍니다. 설정 매개변수에는 감염률, 인구 크기 등의 요소들이 포함되며, 관찰값은 특정 시점의 감염자 수, 목표는 시간에 따른 감염자 수 및 감염률 예측으로 구성됩니다.
read the caption
Table 8: Death Process
| Param | Description |
|---|---|
| Model | Student performance on multi-question exams |
| Setup Parameters | Number of students , number of questions , student-question pair to predict |
| Observations | Outcomes of various student-question pairs |
| Goals | Predicting the correctness of student responses to questions |
🔼 표 9는 Item Response Theory(IRT) 모델에 대한 설명을 제공합니다. IRT 모델은 학생의 능력과 질문의 난이도를 고려하여 학생의 질문에 대한 정답률을 예측하는 통계적 모델입니다. 표에서는 IRT 모델의 매개변수, 설정 매개변수, 관측값, 목표 등에 대한 설명을 보여줍니다. IRT 모델의 세 가지 변형(1PL, 2PL, 3PL) 중 2PL 모델에 대한 자세한 내용도 포함하고 있습니다.
read the caption
Table 9: IRT Model
| Parameter | Description |
|---|---|
| Model | Bayesian hierarchical model |
| Setup Parameters | alpha, beta, lambda, lower limit, upper limit |
| Observations | Length of dugong at a given age |
| Goals | Predicting the length of dugongs at different ages |
🔼 표 10은 논문의 Dugongs 환경에 대한 설명입니다. 이 표는 Bayesian 계층적 모델을 사용하여 dugong의 길이를 예측하는 실험 환경을 자세히 설명합니다. 모델 매개변수, 관측값, 목표 등의 정보를 포함하고 있습니다. 본질적으로는 dugong의 나이와 길이 사이의 관계를 모델링하고 예측하는 데 사용되는 통계적 모델에 대한 세부 정보를 제공합니다.
read the caption
Table 10: Dugongs Environment
| Parameter | Description |
|---|---|
| Model | Poisson regression model |
| Setup Parameters | Regression params: α, β1, β2, and β3 |
| Observations | Population count of peregrine falcons at a given time |
| Goals | Predicting the population of peregrines at different times |
🔼 이 표는 논문의 3.4절 도메인 섹션에 있는 표 11입니다. 이 표는 Peregrine 환경에 대한 설명을 제공합니다. Peregrine 환경은 시간에 따른 Peregrine Falcon 개체 수 변화를 모델링하는 환경입니다. 이 표는 환경에 사용된 모델, 설정 매개변수, 관측값, 목표 등을 보여줍니다.
read the caption
Table 11: Peregrine Environment
| Parameter | Description |
|---|---|
| Model | Survival analysis using a Bayesian approach |
| Setup Parameters | num_patients, time_upper_bound, lambda, beta |
| Observations | Whether a selected patient is alive or dead |
| Goals | Predict survival based on time since surgery and if the cancer had metastasized |
🔼 표 12는 유방암 환자의 생존율을 모델링하는 생존 분석 환경에 대한 설명입니다. 이 환경에서는 수술 후 시간과 전이 여부를 기반으로 환자의 생존 여부를 예측합니다. 표에는 환경에 대한 매개변수, 모델, 설정 매개변수, 관찰값 및 목표 등의 정보가 포함되어 있습니다. 자세한 내용은 본문을 참조하세요.
read the caption
Table 12: Survival Analysis Environment
| Parameter | Description |
|---|---|
| Model | Lotka-Volterra equations |
| Setup Parameters | Initial prey population, initial predator population, α, β, γ, and δ |
| Observations | Populations of prey and predators at a given time |
| Goals | Predicting populations |
🔼 표 13은 논문의 ‘3.4 도메인’ 섹션에 있는 포식자-피식자 환경에 대한 설명입니다. 이 표는 시뮬레이션된 포식자와 피식자 개체군의 상호 작용을 모델링하는 Lotka-Volterra 방정식에 기반한 환경을 보여줍니다. 여기에는 모델(Lotka-Volterra 방정식), 설정 매개변수(초기 포식자 및 피식자 개체군 크기, α, β, γ, δ), 관측값(주어진 시간에 포식자 및 피식자 개체군), 목표(개체군 예측) 등이 포함됩니다.
read the caption
Table 13: Predator-Prey Environment
| Parameter | Description |
|---|---|
| Model | Forward regression model with priors for emotional response |
| Setup Parameters | Prize values, probabilities, outcome, LLM |
| Observations | Prediction in natural language of how a player feels and why |
| Goals | Predicting what a participant thinks a player feels on a likert scale of 8 emotions. |
🔼 이 표는 논문의 ‘3.4 도메인’ 섹션에 있는 감정 예측 환경에 대한 설명입니다. 참가자가 돈이 걸린 게임에서 룰렛을 돌린 후 플레이어의 감정을 예측하는 시나리오를 보여줍니다. 표에는 모델의 매개변수, 관측값, 목표 등이 포함되어 더 자세한 내용을 이해하는 데 도움이 됩니다. 본질적으로 플레이어의 감정 반응을 예측하기 위해 사용되는 예측 모델의 구성 요소를 설명합니다.
read the caption
Table 14: Emotions From Outcomes Environment
| Parameter | Description |
|---|---|
| Model | Logistic regression model with priors for moral decision-making |
| Setup Parameters | Character attributes, intervention type, LLM |
| Observations | Prediction in natural language of which group to save and why |
| Goals | Predicting which group participants choose to save |
🔼 표 15는 도덕적 기계 환경에 대한 설명입니다. 자율 주행 자동차가 도덕적 딜레마 상황에서 어떤 그룹을 구할지 결정해야 하는 시나리오를 제시합니다. 각 그룹의 등장인물은 유모차, 소년, 소녀, 임산부, 남성 의사, 여성 의사, 여성 운동선수, 남성 운동선수, 여성 임원, 남성 임원, 큰 여성, 큰 남성, 노숙자, 노인 남성, 노인 여성, 범죄자, 개, 고양이 중 하나일 수 있습니다. 모델은 등장인물의 속성(성별, 나이, 사회적 지위, 체력, 종)과 개입 유형을 고려하여 그룹을 선택합니다. 표는 이러한 요소의 영향을 보여주는 회귀 계수를 포함합니다.
read the caption
Table 15: Moral Machines Environment
Full paper#



















