TL;DR#
대규모 언어 모델(LLM)은 코드 생성에서 첫 시도만으로 정확한 솔루션을 제시하는 데 어려움을 겪습니다. 기존 연구는 여러 후보 솔루션을 생성하고 LLM 생성 단위 테스트로 검증하여 정확한 솔루션을 식별하는 방식을 사용하지만, LLM의 오류로 인해 단위 테스트의 신뢰성이 떨어지는 문제가 있습니다.
본 논문에서는 단위 테스트의 수를 늘리면 보상 신호의 질이 향상된다는 것을 실험적으로 보여줍니다. 더 나아가, 문제의 난이도에 따라 단위 테스트 수를 동적으로 조절하는 CodeRM-8B라는 경량화된 단위 테스트 생성기를 제안합니다. CodeRM-8B는 다양한 LLM과 벤치마크에서 성능 향상을 보이며, 특히 어려운 문제에서 효과적임을 보였습니다.
Key Takeaways#
Why does it matter?#
본 논문은 코드 생성 모델의 성능 향상에 중요한 영향을 미치는 연구로, 단위 테스트 확장을 통해 보상 신호의 질을 개선하는 효과적인 방법을 제시합니다. 이는 코드 생성 분야의 현존하는 문제점을 해결하고, 향후 연구를 위한 새로운 방향을 제시하여 연구자들에게 큰 영향을 미칠 것입니다. 특히, 다양한 모델 크기와 문제 난이도에 대해 실험을 수행하여 일반화 성능을 검증하였으며, 동적 단위 테스트 확장 기법을 제시하여 효율성을 높였습니다. 이러한 결과는 코드 생성 모델의 성능 향상과 관련된 연구에 중요한 시사점을 제공할 것입니다.
Visual Insights#

🔼 그림 1은 다수결 투표를 위한 단위 테스트의 수량을 늘리면 정책 모델과 보상 모델 모두에서 성능이 향상됨을 보여줍니다. 여러 정책 모델과 보상 모델에 걸쳐 단위 테스트 수를 늘리면 성능이 향상되는 것을 보여줍니다. 정책 모델은 코드 솔루션을 생성하는 모델을 가리키고, 보상 모델은 단위 테스트를 생성하는 모델을 가리킵니다. 이 그림은 단위 테스트의 수가 증가함에 따라 다수결 투표의 정확성이 향상되는 것을 보여주는 주요 실험 결과를 시각적으로 나타냅니다. 특히, 더 많은 코드 솔루션을 생성할 때 효과가 더 크게 나타납니다.
read the caption
Figure 1: Scaling the quantities of unit tests for majority voting leads to improvements in performance across different policy models and reward models. Policy refers to the model that produces code solutions, while reward denotes the model that generates unit tests.
| Method | Llama3-8B | Llama3-70B | GPT-3.5 | GPT-4o-m |
|---|---|---|---|---|
| HumanEval Plus | ||||
| Vanilla | 53.58 | 73.74 | 67.83 | 82.96 |
| Grading RM | 62.20 +8.62 | 75.00 +1.26 | 70.12 +2.29 | 83.50 +0.54 |
| MBR-Exec | 60.30 +6.72 | 75.80 +2.06 | 70.60 +2.77 | 85.20 +2.24 |
| CodeT | 65.30 +11.72 | 76.20 +2.46 | 73.89 +6.06 | 85.30 +2.34 |
| MPSC | 59.72 +6.14 | 75.51 +1.77 | 72.76 +4.93 | 84.82 +1.86 |
| Llama3.1-70B | 72.04 +18.46 | 78.54 +4.80 | 79.76 +11.93 | 85.45 +2.49 |
| CodeRM-8B | 72.01 +18.43 | 78.69 +4.95 | 78.01 +10.18 | 86.38 +3.42 |
| MBPP Plus | ||||
| Vanilla | 49.20 | 69.33 | 70.53 | 71.59 |
| Grading RM | 48.40 -0.80 | 70.60 +1.27 | 66.67 -3.86 | 69.00 -2.59 |
| MBR-Exec | 50.00 +0.80 | 69.80 +0.47 | 70.53 +0.00 | 72.30 +0.71 |
| CodeT | 59.20 +10.00 | 69.90 +0.57 | 69.92 -0.61 | 73.40 +1.81 |
| MPSC | 53.32 +4.12 | 70.91 +1.58 | 71.59 +1.06 | 73.20 +1.61 |
| Llama3.1-70B | 65.26 +16.06 | 71.85 +2.52 | 75.72 +5.19 | 74.96 +3.37 |
| CodeRM-8B | 66.71 +17.51 | 72.44 +3.11 | 75.96 +5.43 | 75.20 +3.61 |
| LiveCodeBench | ||||
| Vanilla | 11.98 | 25.30 | 20.55 | 34.83 |
| Grading RM | 13.10 +1.12 | 26.19 +0.89 | 20.83 +0.28 | 36.31 +1.48 |
| MBR-Exec | 12.04 +0.06 | 25.37 +0.07 | 20.52 -0.03 | 34.83 +0.00 |
| CodeT | 12.61 +0.63 | 25.89 +0.59 | 20.58 +0.03 | 35.13 +0.30 |
| MPSC | 11.98 +0.00 | 25.30 +0.00 | 20.55 +0.00 | 34.83 +0.00 |
| Llama3.1-70B | 13.28 +1.30 | 28.46 +3.16 | 22.80 +2.25 | 38.60 +3.77 |
| CodeRM-8B | 15.21 +3.23 | 27.73 +2.43 | 21.76 +1.21 | 39.20 +4.37 |
🔼 본 표는 세 가지 코드 생성 벤치마크(HumanEval Plus, MBPP Plus, LiveCodeBench)에서 제안된 방법과 다른 기준 방법들의 주요 결과를 보여줍니다. GPT-4o-m은 GPT-4o-mini를 의미합니다. 개선율은 기준 방법(Vanilla)과의 비교를 통해 계산되었으며, 각 데이터셋과 정책 모델에 대해 상위 두 개의 성능이 굵은 글씨와 밑줄로 표시되어 있습니다.
read the caption
Table 1: The main result of our approach and other baselines over three code generation benchmarks. GPT-4o-m stands for GPT-4o-mini. The improvements are calculated between methods and vanilla. The top two performances for each dataset and policy model are marked in bold and underlined.
In-depth insights#
Unit Test Scaling#
본 논문에서 제시된 단위 테스트 스케일링(Unit Test Scaling)은 코드 생성 과정에서 정확성을 높이기 위한 핵심 전략입니다. 기존의 여러 후보 코드를 생성하고 LLM 기반 단위 테스트를 통해 검증하는 방식에서 나아가, 단위 테스트 수를 늘림으로써 보다 정확하고 신뢰도 높은 보상 신호(reward signal)를 얻고자 합니다. 이는 LLM이 자신감 있게 실수하는 경향을 고려했을 때 매우 중요합니다. 실험 결과는 단위 테스트 수 증가가 다양한 모델과 문제 난이도에서 성능 향상으로 이어짐을 보여주며, 특히 어려운 문제일수록 그 효과가 더욱 큽니다. CodeRM-8B와 같은 효율적인 단위 테스트 생성기와 문제 난이도에 따른 동적 스케일링 기법을 통해 실용성을 높였습니다. 단위 테스트의 양적 확장뿐 아니라 질적 향상에도 초점을 맞춰, 보다 효과적이고 효율적인 코드 생성 및 평가 시스템을 구축하는 데 기여합니다. 결론적으로 단위 테스트 스케일링은 LLM 기반 코드 생성 모델의 신뢰성과 정확성을 향상시키는 강력한 방법임을 시사합니다.
CodeRM-8B#
논문에서 제시된 CodeRM-8B는 효율적이고 고품질의 단위 테스트 확장을 가능하게 하는 경량화된 단위 테스트 생성기입니다. 기존의 LLM 기반 단위 테스트 생성 방식의 신뢰성 문제를 해결하기 위해, CodeRM-8B는 대규모 언어 모델을 활용하여 단위 테스트를 생성하고, 이를 통해 생성된 코드의 정확성을 평가하는 데 사용됩니다. 단위 테스트의 수를 늘리면 보상 신호의 질이 향상된다는 중요한 사실을 발견하여, 문제의 난이도에 따라 단위 테스트의 수를 동적으로 조정하는 메커니즘을 구현했습니다. CodeRM-8B는 다양한 규모의 LLM과 세 가지 벤치마크에서 성능 향상을 보였으며, 특히 작은 모델에서 상당한 개선을 보였습니다. 이는 문제 해결의 효율성을 높이고, 더욱 정확한 결과를 얻을 수 있게 합니다. 또한, 문제의 난이도를 분류하는 경량화된 분류기를 훈련하여, 계산 자원을 더 어려운 문제에 우선적으로 할당하는 방식으로 효율성을 극대화했습니다. 결론적으로 CodeRM-8B는 단위 테스트 생성 및 확장에 있어 효율성과 정확성을 모두 개선하는 혁신적인 모델로서, 향후 코드 생성 및 평가 분야에서 널리 활용될 가능성을 보여줍니다.
Dynamic Scaling#
본 논문에서 제시된 “동적 스케일링” 개념은 단순히 단위 테스트의 수를 늘리는 것 이상의 의미를 지닙니다. 문제의 난이도에 따라 단위 테스트의 수를 동적으로 조절함으로써, 제한된 계산 자원을 효율적으로 사용하고 성능 향상을 극대화하는 전략입니다. 어려운 문제일수록 더 많은 단위 테스트가 필요하다는 실험적 관찰을 바탕으로, 문제 난이도를 분류하는 모델을 훈련하고 그 결과에 따라 단위 테스트의 수를 조정합니다. 이는 단순히 모든 문제에 일괄적으로 단위 테스트를 늘리는 것보다 훨씬 효율적인 방법이며, 계산 비용 대비 성능 향상이라는 측면에서 중요한 의미를 가집니다. 동적 스케일링은 모델의 크기와 상관없이 성능 향상을 가져오며, 특히 더 작은 모델에서 그 효과가 두드러집니다. 이를 통해 제한된 자원으로도 높은 성능을 달성할 수 있는 실용적인 방법론임을 시사합니다.
Reward Signal#
본 논문에서 다루는 코드 보상 모델링에서 ‘보상 신호(Reward Signal)‘는 코드 생성 모델의 성능을 평가하고 개선하는 데 핵심적인 역할을 합니다. LLM(Large Language Model)이 생성한 코드의 정확성을 판단하는 데 사용되는 핵심 지표이기 때문입니다. 단순히 코드의 실행 결과만을 보는 것이 아니라, LLM이 생성한 단위 테스트(Unit Test)의 실행 결과를 보상 신호로 활용합니다. 즉, 단위 테스트 통과 여부가 코드의 정확성을 나타내는 신호가 되는 것입니다. 하지만 LLM이 자신감 있게 잘못된 코드를 생성하는 경우가 많으므로, 단위 테스트의 신뢰도가 떨어져 보상 신호의 질이 저하될 수 있습니다. 따라서 논문에서는 단위 테스트의 수를 늘려 보상 신호의 질을 높이는 방법을 제안하고 있습니다. 이는 단순히 양적인 증가가 아니라, 문제의 난이도에 따라 단위 테스트의 수를 동적으로 조절하는 동적 스케일링 기법을 통해 효율성을 높이는 전략을 포함합니다. 문제의 난이도에 따른 보상 신호의 질 변화를 분석하여, 어려운 문제일수록 단위 테스트의 스케일링 효과가 더 크다는 점을 실험적으로 보여줍니다. 결론적으로, 본 논문의 ‘보상 신호’에 대한 논의는 LLM 기반 코드 생성 모델의 신뢰성과 효율성을 높이는 데 중요한 시사점을 제공합니다.
Future Work#
본 논문은 코드 보상 모델링을 위한 단위 테스트의 동적 스케일링에 대해 다루고 있으며, 단위 테스트 수의 증가가 보상 신호의 질적 향상으로 이어진다는 것을 실험적으로 보여줍니다. 하지만, 모델의 성능 향상은 문제의 난이도에 따라 달라지는데, 어려운 문제일수록 더 큰 성능 향상을 보였습니다. 미래 연구 방향으로는 다음과 같은 가능성을 생각해볼 수 있습니다. 먼저, 문제의 난이도를 더욱 정확하게 예측하는 분류기를 개발하는 것이 중요합니다. 현재 사용된 문제 난이도 분류기는 간단한 구조로, 더욱 정교한 모델을 통해 난이도 예측의 정확도를 높일 수 있습니다. 다음으로, 단위 테스트의 다양성과 적용 범위를 향상시키는 연구가 필요합니다. 단순히 단위 테스트의 수만 늘리는 것이 아니라, 다양한 종류의 테스트 케이스를 생성하여 코드의 여러 측면을 검증하는 것이 중요하며, 이는 더욱 강력하고 신뢰할 수 있는 보상 신호를 생성하는 데 기여할 것입니다. 또한, 동적 스케일링 전략을 보다 효율적으로 개선하는 연구도 필요합니다. 현재 사용된 그리디 알고리즘은 단순한 방법이며, 더욱 발전된 최적화 알고리즘을 적용하여 계산 자원을 더욱 효율적으로 활용할 수 있을 것입니다. 마지막으로, 다양한 프로그래밍 언어 및 문제 유형에 대한 실험을 확장하여 본 연구의 일반화 가능성을 높일 필요가 있습니다. 현재 연구는 파이썬 기반의 특정 문제 유형에 국한되어 있으므로, 다른 언어와 문제 유형으로의 확장을 통해 연구의 범용성을 높여야 합니다.
More visual insights#
More on figures

🔼 그림 2는 200개의 후보 코드 솔루션을 사용하여 다양한 단위 테스트 생성기(보상 모델)의 성능과 단위 테스트 수량 간의 상관관계를 보여줍니다. 단위 테스트 수가 증가함에 따라 여러 보상 모델에서 성능이 향상되는 것을 보여주는 다양한 그래프가 제시되어 있습니다. 각 그래프는 특정 보상 모델에 대한 성능 변화를 보여주며, 단위 테스트 수가 증가할수록 정확도가 향상되는 경향을 나타냅니다. 이는 단위 테스트의 수량이 코드 생성 모델의 성능에 긍정적인 영향을 미침을 시사합니다.
read the caption
Figure 2: The correlation between the quantities of unit tests and the performance on different unit test generators (reward model) with 200200200200 candidate code solutions.

🔼 그림 3은 문제 난이도에 따른 최고 N개 성능 향상을 보여줍니다. 5개의 퀀타일로 나누어진 문제들의 정답률을 보면, 퀀타일 1(가장 쉬운 문제)의 정답률이 가장 높고, 퀀타일 5(가장 어려운 문제)의 정답률이 가장 낮습니다. 단위 테스트 수를 늘릴수록 어려운 문제에 대한 정확도가 크게 향상됨을 보여줍니다. 즉, 단위 테스트 수 증가는 문제의 난이도에 따라 성능 향상에 미치는 영향이 다르며, 특히 어려운 문제일수록 그 효과가 더욱 크다는 것을 시사합니다.
read the caption
Figure 3: The improvements of best-of-N performance on problems of different difficulties. Quintile 1 (easiest) has the highest pass rate, while Quintile 2 (hardest) has the lowest pass rate. Scaling the quantity of unit tests significantly improves the accuracy on more complex problems.
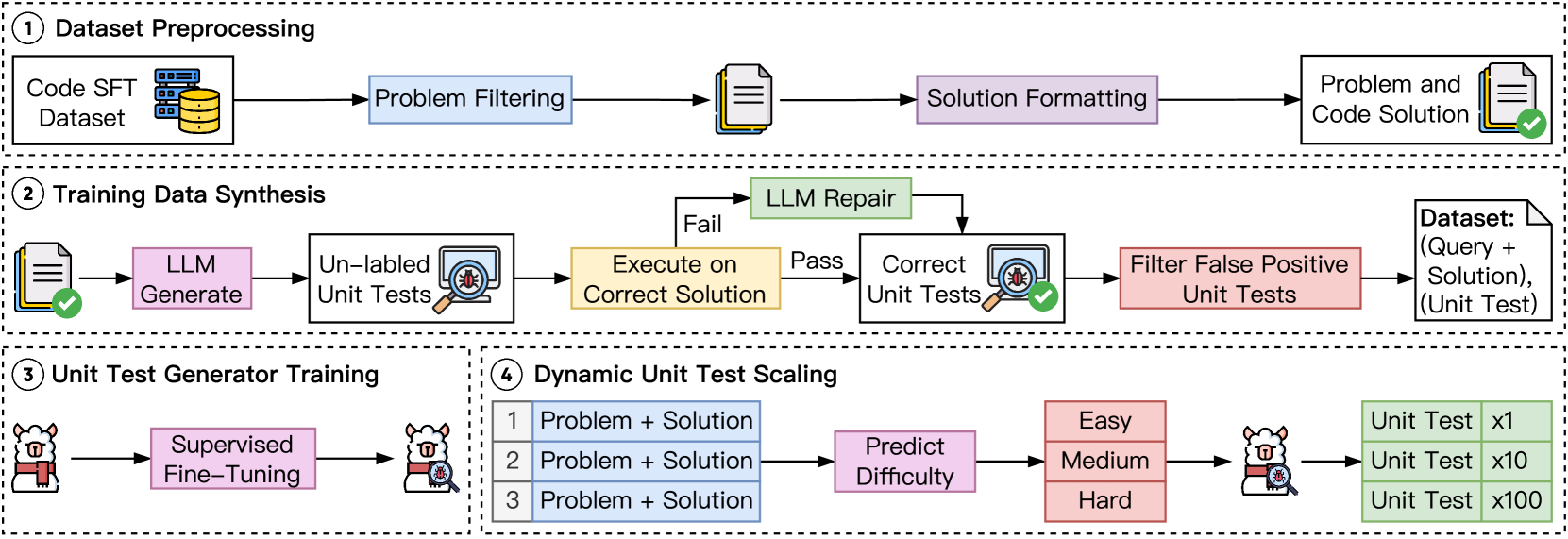
🔼 그림 4는 효율적이고 고품질의 단위 테스트 확장을 위한 개요를 보여줍니다. 먼저, 고품질의 합성 데이터를 기반으로 경량 단위 테스트 생성기를 훈련합니다. 그런 다음, 동적 단위 테스트 확장을 사용하여 효율성을 더욱 향상시킵니다. 이 그림은 단위 테스트 생성기 훈련을 위한 데이터 전처리, 합성 단위 테스트 생성, 단위 테스트 생성기 미세 조정, 문제 난이도 예측, 동적 단위 테스트 할당 및 최종 결과를 포함한 전체 프로세스를 보여주는 단계별 다이어그램입니다.
read the caption
Figure 4: Overview for efficient and high-quality unit test scaling. First, we train a lightweight unit test generator based on high-quality synthetic data. Subsequently, we employ dynamic unit test scaling to further improve efficiency.

🔼 그림 5는 Llama3-8B를 정책 모델로 사용하여 세 가지 서로 다른 단위 테스트 생성기(보상 모델)의 성능을 단위 테스트 수량에 따라 비교한 그래프입니다. 단위 테스트 수량 변화에 따른 세 가지 보상 모델의 성능 변화를 보여주어, 단위 테스트 수량 증가가 모델 성능에 미치는 영향을 시각적으로 보여줍니다.
read the caption
Figure 5: The performance of three different unit test generators (reward model) on different quantities of unit tests, while employing Llama3-8B as the policy model.

🔼 그림 6은 세 가지 계산 비용 할당 전략(골드 패스율을 사용한 동적 할당, 예측 패스율을 사용한 동적 할당, 동일 할당)에 따른 유닛 테스트 확장 시 최고 N개 성능 비교 결과를 보여줍니다. 골드 패스율 기반 동적 할당은 실제 패스율을 사용하여 문제의 난이도에 따라 계산 비용을 할당하는 반면, 예측 패스율 기반 동적 할당은 예측된 패스율을 사용합니다. 동일 할당은 모든 문제에 동일한 계산 비용을 할당합니다. 이 그림은 다양한 문제 난이도에 따른 각 전략의 성능을 보여주어, 동적 할당 전략이 특히 어려운 문제에 대해 성능 향상에 효과적임을 시사합니다.
read the caption
Figure 6: Best-of-N performance comparison under unit test scaling with three computation budget allocation strategies: dynamic allocation with gold pass rate, dynamic allocation with predicted pass rate, and equal allocation.

🔼 그림 7은 합성 데이터의 크기가 모델 성능에 미치는 영향을 보여줍니다. 훈련 데이터 크기가 증가함에 따라 모델 성능이 지속적으로 향상되는 것을 보여줍니다. 이는 고품질의 훈련 데이터를 확보하고 데이터 합성 파이프라인을 사용하여 더 많은 고품질 단위 테스트를 생성하는 것이 모델 성능 향상에 크게 기여함을 보여줍니다.
read the caption
Figure 7: The effects of data size.

🔼 그림 8은 다양한 난이도의 문제에 대해 유닛 테스트 수를 늘리는 것의 성능 향상 효과를 보여줍니다. 다양한 정책 모델과 보상 모델을 사용하여 실험을 진행하였습니다. 전반적으로 유닛 테스트의 수를 늘리면 더 어려운 문제에서 더 큰 성능 향상을 가져오는 것을 확인할 수 있습니다. 특히 Llama3.1-70B를 정책 모델로 사용했을 때 그 효과가 더욱 두드러졌습니다. 그림은 문제의 난이도에 따른 성능 향상과 유닛 테스트 수의 관계를 보여주는 히트맵을 포함하고 있습니다.
read the caption
Figure 8: The performance gain of scaling the number of unit tests on problems of different difficulties across various policy model and reward model. Overall, increasing the number of unit tests yields greater performance improvements on more challenging problems, particularly when employing Llama3.1-70B as the policy model.

🔼 그림 9는 단위 테스트 생성기를 위한 훈련 데이터의 예시를 보여줍니다. 질문과 그에 대한 코드 답변이 주어지고, 테스트 케이스를 작성하여 코드 답변의 정확성을 확인하는 작업이 제시됩니다. 이 예시에서는
expected_strangle_return함수에 대한 테스트 케이스를 작성하는 방법을 보여주는 것으로, 양수, 음수, 영의 예상 수익률을 각각 테스트하는 세 가지 테스트 케이스가 포함되어 있습니다. 각 테스트 케이스는unittest라이브러리를 사용하며, 자세한 주석과 함께 예상 수익률을 계산하고assertAlmostEqual을 사용하여 결과를 검증합니다. 이러한 방식으로 생성된 질문, 코드 답변, 그리고 테스트 케이스는 단위 테스트 생성기 모델을 훈련시키는 데 사용됩니다.read the caption
Figure 9: An example of the training data for the unit test generator.
More on tables
| Model | Acc ( | F1 ( | FAR ( | FRR ( |
|---|---|---|---|---|
| Llama3.1-8B | 60.02 | 44.97 | 13.66 | 46.13 |
| Llama3.1-70B | 73.65 | 70.15 | 11.10 | 34.51 |
| CodeRM-8B (Ours) | 69.64 | 63.63 | 11.17 | 38.55 |
| Llama3.1-8B | 74.21 | 74.35 | 20.44 | 30.55 |
| Llama3.1-70B | 78.30 | 78.76 | 17.19 | 25.97 |
| CodeRM-8B (Ours) | 80.46 | 81.27 | 16.48 | 22.71 |
🔼 이 표는 HumanEval Plus 데이터셋에서 Llama3.1-8B 모델을 정책 모델로 사용하여 개별 단위 테스트와 다수의 단위 테스트 조합의 품질을 보여줍니다. 단일 단위 테스트와 여러 단위 테스트를 결합했을 때의 정확도(Accuracy), F1 점수, 거짓 양성률(FAR), 거짓 음성률(FRR)을 측정하여 모델의 성능을 평가합니다. 상위 두 개의 성능은 굵은 글씨와 밑줄로 강조 표시되어 있습니다. 이를 통해 단위 테스트의 품질과 다수의 테스트를 결합하는 전략의 효과를 정량적으로 비교 분석합니다.
read the caption
Table 2: The quality of individual unit tests and the combination of multiple unit tests on HumanEval Plus, utilizing Llama3.1-8B as the policy model. The top two performances are highlighted using bold and underlining.
| Method | HumanEval+ | MBPP+ |
|---|---|---|
| zero-shot | 66.67 | 63.27 |
| training wo / quality control | 69.71+3.04 | 64.96+1.69 |
| training w / quality control | 71.09+4.42 | 66.31+3.04 |
🔼 본 표는 합성 데이터의 품질 관리가 모델 성능에 미치는 영향을 보여줍니다. 품질 관리 과정이 없는 모델과 비교하여, 품질 관리 과정이 포함된 모델의 정확도와 F1 점수가 향상되었음을 보여줍니다. 이는 양성 데이터의 품질이 단위 테스트 생성기의 성능에 중요한 역할을 한다는 것을 시사합니다.
read the caption
Table 3: The effects of synthetic data quality control.
| Hyperparameters | Value |
|---|---|
| Temperature | 0.8 |
| Top P | 0.95 |
| Frequency Penalty | 0 |
| Presence Penalty | 0 |
🔼 이 표는 본 논문에서 사용된 대규모 언어 모델(LLM)의 하이퍼파라미터들을 보여줍니다. LLM은 코드 솔루션과 단위 테스트 생성에 사용되었으며, 구체적으로는 temperature, top p, frequency penalty, presence penalty의 네 가지 하이퍼파라미터 값을 제시합니다. 이는 LLM의 출력 확률 분포를 조절하여 다양한 종류의 결과를 생성하는 데 활용됩니다. 각 하이퍼파라미터의 값은 모델의 성능에 영향을 미치므로, 이 표는 실험 환경 설정을 이해하는 데 중요한 역할을 합니다.
read the caption
Table 4: The hyperparameters of LLMs for solution and unit test generation.
Full paper#


















