TL;DR#
기존의 비디오 LLM들은 전체적인 영상 이해에 집중하여 세밀한 공간-시간적 정보를 포착하는 데 어려움을 겪고, 고품질 개체 수준 데이터의 부족으로 인해 발전이 제한적이었습니다. 이러한 문제를 해결하기 위해, 본 논문에서는 새로운 비디오 LLM인 VideoRefer와 대규모 고품질 데이터셋 VideoRefer-700K, 그리고 종합적인 벤치마크 VideoRefer-Bench를 제시합니다.
VideoRefer는 다양한 공간-시간적 개체 정보를 포착하기 위해 다중 에이전트 데이터 엔진을 통해 생성된 고품질 데이터셋을 기반으로, 새로운 공간-시간적 개체 인코더를 통해 세밀한 영상 이해를 가능하게 합니다. 또한, VideoRefer-Bench는 다양한 측면에서 VideoRefer의 성능을 평가하여, 향후 연구 방향을 제시하고 영상 이해 분야의 발전에 기여합니다.
Key Takeaways#
Why does it matter?#
본 논문은 비디오에 대한 정교한 공간-시간적 이해를 가능하게 하는 새로운 비디오 LLM인 VideoRefer와 대규모 데이터셋 및 벤치마크를 제시함으로써, 영상 이해 분야 연구에 중요한 기여를 합니다. 영상 내 개체의 정확한 위치와 시간적 흐름을 포착하고, 다양한 작업에서 기존 모델보다 뛰어난 성능을 보여줍니다. 따라서, 향후 영상 이해 연구의 새로운 방향을 제시하고, 다양한 응용 분야에 적용 가능한 잠재력을 지닙니다.
Visual Insights#

🔼 그림 1은 기존의 일반적인 다중 모드 대규모 언어 모델(MLLM)과 특수화된 MLLM과 비교하여 VideoRefer의 성능을 보여줍니다. VideoRefer는 기존 모델들보다 세분화된 지역 및 시간적 비디오 이해 작업에서 뛰어난 성능을 보입니다. 여기에는 기본적인 비디오 객체 참조, 복잡한 비디오 관계 분석 및 비디오 객체 검색 등이 포함됩니다.
read the caption
Figure 1: Comparisons with previous general and specialized MLLMs. Our VideoRefer excels in multiple fine-grained regional and temporal video understanding tasks, including basic video object referring, complex video relationship analysis, and video object retrieval.
| Method | Single-Frame SC | Single-Frame AD | Single-Frame TD | Single-Frame HD | Single-Frame Avg. | Multi-Frame SC | Multi-Frame AD | Multi-Frame TD | Multi-Frame HD | Multi-Frame Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| Generalist Models | ||||||||||
| GPT-4o [28] | 3.34 | 2.96 | 3.01 | 2.50 | 2.95 | 4.15 | 3.31 | 3.11 | 2.43 | 3.25 |
| GPT-4o-mini [28] | 3.56 | 2.85 | 2.87 | 2.38 | 2.92 | 3.89 | 3.18 | 2.62 | 2.50 | 3.05 |
| InternVL2-26B [8] | 3.55 | 2.99 | 2.57 | 2.25 | 2.84 | 4.08 | 3.35 | 3.08 | 2.28 | 3.20 |
| Qwen2-VL-7B [43] | 2.97 | 2.24 | 2.03 | 2.31 | 2.39 | 3.30 | 2.54 | 2.22 | 2.12 | 2.55 |
| Specialist Models | ||||||||||
| Image-level models | ||||||||||
| Osprey-7B [46] | 3.19 | 2.16 | 1.54 | 2.45 | 2.34 | 3.30 | 2.66 | 2.10 | 1.58 | 2.41 |
| Ferret-7B [44] | 3.08 | 2.01 | 1.54 | 2.14 | 2.19 | 3.20 | 2.38 | 1.97 | 1.38 | 2.23 |
| Video-level models | ||||||||||
| Elysium-7B [41] | 2.35 | 0.30 | 0.02 | 3.59 | 1.57 | - | - | - | - | - |
| Artemis-7B [32] | - | - | - | - | - | 3.42 | 1.34 | 1.39 | 2.90 | 2.26 |
| VideoRefer-7B | 4.41 | 3.27 | 3.03 | 2.97 | 3.42 | 4.44 | 3.27 | 3.10 | 3.04 | 3.46 |
🔼 표 1은 VideoRefer-BenchD에 대한 다양한 모델들의 성능 비교 결과를 보여줍니다. ‘SC’, ‘AD’, ‘TD’, ‘HD’는 각각 주제 일치율, 외형 묘사 정확도, 시간적 묘사 정확도, 환각 검출 정확도를 나타냅니다. ‘Avg’는 네 가지 지표의 평균 점수입니다. 최고 성능은 굵은 글씨체로, 두 번째로 높은 성능은 밑줄로 표시되어 있습니다. ‘-‘는 특정 입력 형식을 지원하지 않는 모델을 나타냅니다. 회색으로 표시된 셀은 원래 방법으로 작업을 완료할 수 없는 경우를 나타내며, 이 경우에는 대상의 마스크가 원본 비디오에 겹쳐졌습니다 (아래도 동일). 이 표는 단일 프레임과 다중 프레임 모드 모두에 대한 결과를 제시하여, 다양한 모델들의 공간-시간적 객체 이해 능력을 비교 분석합니다.
read the caption
Table 1: Performance comparisons on VideoRefer-BenchDD{}^{\text{D}}start_FLOATSUPERSCRIPT D end_FLOATSUPERSCRIPT. The best results are bold and the second-best results are underlined. “–” means that the model does not support the certain input form. Grey entries denote cases where the original method cannot accomplish the task; for these tests, masks of the targets were overlaid on the original video (the same below).
In-depth insights#
VideoLLM Advancements#
본 논문은 VideoLLM의 발전에 대한 심도있는 논의를 제시합니다. 초기 VideoLLM은 전반적인 비디오 이해에 초점을 맞추었으나, 세밀한 공간-시간적 정보 및 개체 수준의 이해에는 어려움을 겪었습니다. 이러한 한계를 극복하기 위해 제시된 VideoRefer Suite는 대규모 고품질 개체 수준 비디오 데이터셋(VideoRefer-700K)을 구축하고, 공간-시간적 개체 인코더를 탑재한 VideoRefer 모델을 제안하며, 포괄적인 벤치마크(VideoRefer-Bench)를 통해 성능을 평가합니다. 다양한 세부 과제(개체 참조, 관계 분석, 개체 검색 등)에서 우수한 성능을 보이며, 기존 모델의 한계를 넘어선 더욱 정교하고 상호작용적인 비디오 이해를 가능하게 합니다. 특히, 다중 에이전트 데이터 엔진을 활용한 데이터셋 구축과 공간 토큰 추출기 및 시간 토큰 병합 모듈을 통한 모델 개선은 주목할 만한 부분입니다. 미래 예측과 같은 복잡한 추론 과제에도 성과를 거두어, VideoLLM의 실제 응용 가능성을 높입니다. 결론적으로, VideoRefer Suite는 VideoLLM의 공간-시간적 개체 이해 능력을 크게 향상시키는 중요한 발전을 제시합니다.
VideoRefer Suite#
VideoRefer Suite는 비디오에 대한 정밀한 공간-시간적 객체 이해를 향상시키기 위해 제안된 포괄적인 프레임워크입니다. **대규모 고품질 객체 수준 비디오 지시 데이터셋(VideoRefer-700K)**을 통해 고난이도의 비디오 이해 과제를 해결할 수 있도록 설계되었습니다. 다양한 공간-시간적 객체 인코더를 갖춘 VideoRefer 모델은 정확한 지역 및 순차적 표현을 포착하여 다양한 비디오 참조 벤치마크에서 우수한 성능을 보여줍니다. VideoRefer-Bench 벤치마크는 다양한 측면에서 Video LLM의 공간-시간적 이해 능력을 종합적으로 평가하여 모델의 강점과 약점을 파악하는 데 도움을 줍니다. 전반적으로 VideoRefer Suite는 비디오 이해 분야의 혁신적인 발전을 가져올 잠재력을 가진 중요한 연구입니다.
Multi-agent Engine#
연구 논문에서 제시된 ‘멀티에이전트 엔진’에 대한 심층적인 분석 결과를 요약하면 다음과 같습니다. 다양한 전문 모델들을 통합하여 고품질의 객체 수준 비디오 지시 데이터셋을 생성하는 시스템으로, 각 에이전트는 특정 작업(명사 추출, 캡션 생성, 마스크 생성, 검증, 개선)에 특화되어 있습니다. 각 에이전트의 전문성을 바탕으로 상호 협력 및 검증을 통해 노이즈 제거 및 정확도 향상을 도모하며, 이는 단순히 데이터를 수집하는 수준을 넘어 데이터의 질적 향상에 초점을 맞추고 있음을 보여줍니다. 다양한 유형의 데이터 (상세 캡션, 간략 캡션, 질의응답 쌍) 생성을 지원하여, VideoLLM의 다양한 측면을 평가할 수 있는 종합적인 벤치마크 구축에 기여합니다. 전반적으로, 이 멀티에이전트 엔진은 데이터 생성 과정의 효율성과 정확성을 극대화하는 동시에, 고품질의 객체 수준 데이터 확보라는 어려운 과제에 대한 효과적인 해결책을 제시합니다.
Benchmarking LLMs#
LLM 벤치마킹은 다양한 측면에서 LLM의 성능을 평가하는 필수적인 과정입니다. 단순한 정확도 측정을 넘어, 추론 능력, 일반화 능력, 편향성, 그리고 효율성까지 고려해야 합니다. 기존 벤치마크는 종종 특정 작업에 치우쳐 일반적인 LLM 성능을 제대로 반영하지 못하는 한계를 가지고 있습니다. 따라서 다양한 작업 유형과 데이터셋을 포함하는 포괄적인 벤치마킹 프레임워크가 필요하며, 공정한 비교를 위한 표준화된 평가 지표의 개발 또한 중요합니다. 더 나아가, LLM의 윤리적 측면을 평가하는 벤치마크도 필요하며, 환경에 대한 영향까지 고려하는 지속가능한 벤치마킹 방식에 대한 연구가 필요합니다. 실제 응용 사례를 반영한 평가를 통해 LLM의 실질적인 유용성을 측정하는 것도 중요한 부분입니다. 궁극적으로, LLM의 발전을 촉진하고 신뢰할 수 있는 시스템 구축을 위해서는 지속적인 벤치마킹과 개선 노력이 필수적입니다.
Future Directions#
본 논문은 비디오에 대한 객체 수준의 공간-시간적 이해를 향상시키기 위해 VideoRefer Suite를 제시합니다. 향후 연구 방향으로는 우선, 객체 접지(grounding) 기능을 통합하여 실제 환경에서의 적용성을 높이는 것입니다. 현재 객체 수준의 이해에 초점을 맞추고 있지만, 접지 기능이 추가된다면 객체와 주변 환경과의 상호작용을 더욱 정확하게 파악할 수 있게 됩니다. 또한, 데이터셋의 확장을 통해 다양한 객체, 상황, 그리고 복잡한 상호작용을 포괄하는 모델을 개발하는 것이 중요합니다. 현재 데이터셋은 고품질이지만 규모가 제한적이기 때문에, 더욱 광범위한 비디오 데이터를 포함하여 모델의 일반화 능력을 향상시킬 필요가 있습니다. 아울러, 더욱 효율적인 모델 아키텍처를 연구하여 추론 속도와 자원 소모를 개선하는 것도 중요한 과제입니다. 현재 모델은 우수한 성능을 보이지만, 계산 비용이 상대적으로 높을 수 있으므로, 더욱 경량화된 아키텍처를 연구하여 실시간 처리에 적합한 모델을 개발해야 합니다. 마지막으로, 다양한 하위 작업(subtask)에 대한 성능 평가 지표를 추가하여 모델의 전체적인 성능을 더욱 면밀하게 분석하는 연구가 필요합니다.
More visual insights#
More on figures

🔼 이 그림은 논문의 VideoRefer-700K 데이터셋 구축을 위한 다중 에이전트 데이터 엔진의 구조를 보여줍니다. 데이터셋 생성 과정은 Analyzer(명사 추출), Annotator(객체 수준 캡션 생성), Segmentor(마스크 생성), Reviewer(일관성 검증), Refiner(요약 및 개선)의 다섯 가지 구성 요소로 이루어져 있습니다. 각 구성 요소는 비디오 데이터에서 객체 수준의 설명과 마스크를 생성하고, 이를 검증 및 개선하여 고품질의 데이터셋을 만드는 역할을 합니다. 데이터 엔진은 여러 전문 모델을 협업하여 다양한 객체 수준의 지침 데이터를 생성합니다. 최종적으로 생성된 VideoRefer-700K는 객체 수준의 상세한 설명, 짧은 설명, 그리고 다중 라운드 질의응답 쌍으로 구성됩니다.
read the caption
Figure 2: A multi-agent data engine for the construction of our VideoRefer-700K.

🔼 이 그림은 논문의 VideoRefer 모델 아키텍처를 보여줍니다. VideoRefer는 영상 내의 특정 객체에 대한 정확한 공간-시간적 이해를 가능하게 하는 비디오 LLM(대규모 언어 모델)입니다. 아키텍처는 공유된 시각적 인코더, 다양한 입력(단일 프레임 및 다중 프레임)을 처리할 수 있는 다목적 공간-시간적 객체 인코더(공간 토큰 추출기와 시간 토큰 병합 모듈 포함), 그리고 언어 디코딩을 위한 지시 사항 따르는 LLM으로 구성됩니다. 단일 프레임 모드에서는 단일 프레임과 사용자가 지정한 영역을 입력으로 받고, 다중 프레임 모드에서는 여러 프레임과 해당 영역을 입력받아 시간적 맥락 정보를 효과적으로 포착합니다. 결과적으로, 이 모델은 단일 프레임 및 다중 프레임 객체에 대한 정확하고 풍부한 표현을 생성하여 다양한 공간-시간적 영상 이해 작업을 수행합니다.
read the caption
Figure 3: Model architecture of our VideoRefer for spatial-temporal video object understanding.

🔼 이 그림은 논문의 VideoRefer-Bench에 대한 시각적 예시를 보여줍니다. VideoRefer-Bench는 비디오 객체에 대한 참조 능력을 평가하기 위한 벤치마크이며, 이 그림은 다차원 평가를 통해 생성된 설명의 다양한 측면(주어 일치, 외모 묘사, 시간적 묘사, 환각 탐지)을 보여줍니다. 각 측면은 GPT-40 모델을 이용하여 점수가 매겨지며, 그림은 이러한 평가 과정과 결과를 시각적으로 보여주는 대표적인 예시를 제시합니다. 비디오 클립과 함께 생성된 묘사, 그리고 각 측면에 대한 점수를 보여주어 VideoRefer-Bench의 평가 방식을 이해하는 데 도움을 줍니다.
read the caption
Figure 4: Exemplar visual illustration of VideoRefer-Bench.

🔼 Figure 5는 VideoRefer-Bench 데이터셋의 특징을 보여주는 그림입니다. (a)는 VideoRefer-Bench에 포함된 카테고리 목록을 보여줍니다. 사람, 동물, 교통수단, 물건, 환경, 가구 등 다양한 종류의 객체들이 포함되어 있음을 알 수 있습니다. (b)는 VideoRefer-Bench에서 사용된 질문 유형을 보여줍니다. 기본적인 질문, 순차적인 질문, 관계 질문, 추론 질문, 미래 예측 질문 등 다양한 유형의 질문들이 포함되어 있어 모델의 다양한 측면을 평가할 수 있음을 보여줍니다. 각 질문 유형별 비율을 통해 어떤 유형의 질문이 얼마나 많이 사용되었는지 확인할 수 있습니다.
read the caption
Figure 5: Data characteristics of VideoRefer-Bench.

🔼 그림 6은 VideoRefer-BenchD에서 VideoRefer 모델의 성능을 일반적인 GPT-4와 지역적 비디오 수준의 Elysium 및 Artemis 모델과 비교하여 보여줍니다. VideoRefer 모델은 단일 객체 참조, 복잡한 추론, 미래 예측, 비디오 개체 검색 및 일반적인 비디오 이해와 같은 다양한 작업에서 우수한 성능을 보여줍니다. 이 그림은 각 모델의 출력 결과와 비교하여 VideoRefer 모델의 정확성과 세부적인 묘사 능력을 강조합니다. 세 모델 모두 같은 비디오 클립을 입력으로 받았지만, VideoRefer 모델은 객체의 외관, 동작 및 주변 환경에 대한 보다 정확하고 풍부한 설명을 생성합니다.
read the caption
Figure 6: Visual comparisons between our VideoRefer with general GPT-4o and regional video-level Elysium and Artemis. Here we provide detailed illustrations on VideoRefer-BenchDD{}^{\text{D}}start_FLOATSUPERSCRIPT D end_FLOATSUPERSCRIPT.

🔼 그림 7은 비디오의 시간적 차원에 걸쳐 인접한 객체 수준 토큰 쌍 간의 유사성을 시각적으로 보여줍니다. 각 비디오 클립의 여러 프레임을 보여주는 일련의 이미지가 있으며, 각 프레임마다 객체의 마스크와 해당 마스크에 대한 토큰 표현이 표시됩니다. 인접 프레임의 토큰 쌍 사이의 유사성은 코사인 유사도를 사용하여 측정되며, 열 지도 형태로 표시되어 유사도의 정도를 나타냅니다. 색상이 밝을수록 유사도가 높음을 나타냅니다. 이는 시간 경과에 따른 객체 표현의 변화를 이해하는 데 도움이 됩니다. 예를 들어, 객체가 시간이 지남에 따라 유사한 모양을 유지하면 높은 유사도 값을 갖게 되고, 반대로 객체의 모양이 크게 변하면 낮은 유사도 값을 갖게 됩니다. 이러한 시각화는 비디오 내의 객체 추적 및 상호 작용을 분석하는 데 유용합니다.
read the caption
Figure 7: Visualizations of similarity among adjacent object-level token pairs across the temporal dimension. Here, we use cosine similarity as the measurement.

🔼 이 그림은 논문의 VideoRefer Suite에 대한 설명 중 데이터셋 구성 부분(3.1 VideoRefer-700K Dataset)에 해당하는 그림입니다. 각 훈련 단계별 데이터 분포를 시각적으로 보여줍니다. 총 네 단계(Stage 1~3, 2.5)로 나뉘며, 각 단계마다 사용된 데이터의 종류와 개수를 이미지와 텍스트를 통해 설명합니다. Stage 1은 Image-Text Alignment Pre-training, Stage 2는 Region-Text Alignment Pre-training, Stage 2.5는 High-Quality Knowledge Learning, Stage 3는 Visual Instruction Tuning 단계를 나타냅니다. 각 단계별로 사용된 데이터의 종류와 양을 명확하게 보여주어 VideoRefer 모델의 훈련 과정을 이해하는 데 도움을 줍니다.
read the caption
Figure 8: Visual illustrations of the data distribution for each training stage.

🔼 그림 9는 VideoRefer-700K 데이터셋의 데이터 분포를 보여줍니다. 이 데이터셋은 짧은 설명, 상세 설명, 그리고 다양한 유형의 질문과 답변 쌍(QA pairs)을 포함한 다섯 가지 유형의 데이터로 구성됩니다. 각 데이터 유형의 개수를 시각적으로 보여주어 데이터셋의 구성을 한눈에 파악할 수 있도록 합니다. 짧은 설명 데이터는 영상 속 객체에 대한 간략한 설명을 포함하며, 상세 설명 데이터는 객체에 대한 더욱 자세하고 풍부한 설명을 제공합니다. QA pairs는 객체, 객체 간 관계, 또는 미래 예측 등에 관한 다양한 질문과 답변을 포함합니다. 이 그림은 VideoRefer 모델의 학습에 사용된 데이터셋의 규모와 다양성을 보여주는 중요한 정보를 제공합니다.
read the caption
Figure 9: Data distributions of our VideoRefer-700K dataset, encompassing five different data types.

🔼 그림 10은 VideoRefer-700K 데이터셋 생성 과정에서 사용된 Reviewer의 성능 평가를 위한 수동 검증 과정을 시각적으로 보여줍니다. Reviewer는 생성된 객체 수준의 캡션과 마스크의 정확성을 검증하는 역할을 합니다. 그림에서는 Reviewer의 검증 결과에 따라 TP(True Positive), TN(True Negative), FP(False Positive), FN(False Negative) 네 가지 경우를 예시로 제시하여, 각각의 경우에 해당하는 비주얼 데이터와 설명을 제공합니다. TP는 Reviewer가 정확하게 식별하고 평가한 항목이고, TN은 Reviewer가 잘못된 것으로 정확하게 제거한 항목입니다. FP는 Reviewer가 올바르다고 판단했지만 실제로는 잘못된 항목이고, FN은 Reviewer가 잘못된 것으로 판단했지만 실제로는 올바른 항목입니다. 이 그림은 Reviewer의 성능 평가에 사용된 지표와 그에 따른 시각적 예시를 통해, 데이터 품질 관리 과정에 대한 이해를 높여줍니다.
read the caption
Figure 10: Visual illustrations of human check process. TP, TN, FP and FN are introduced for the assessment on Reviewer.

🔼 그림 11은 논문에서 제시된 다중 에이전트 데이터 엔진의 구성 과정을 자세하게 보여주는 예시입니다. 단계별로 설명하자면, 먼저 분석기(Analyzer)를 통해 비디오 캡션에서 명사(주어)를 추출하고, 주석기(Annotator)를 통해 객체에 대한 자세한 설명(동작 및 외형)을 생성합니다. 다음으로, 분할기(Segmentor)를 사용하여 객체에 대한 픽셀 단위 마스크를 생성하고, 검토자(Reviewer)가 마스크와 설명의 일관성을 검증합니다. 최종적으로, 다듬는 과정(Refiner)을 통해 일관성 있는 객체 수준의 비디오 설명 데이터를 생성합니다. 이 그림은 다중 에이전트 기반 데이터 생성 과정을 시각적으로 보여주는 상세한 예시를 제공합니다.
read the caption
Figure 11: A detailed illustrative example of the construction pipeline in our multi-agent data engine.

🔼 그림 12는 VideoRefer 모델이 수행하는 다양한 작업에 대한 시각화 결과를 보여줍니다. 여기에는 단일 객체 언급, 비디오 관계 분석, 복잡한 추론, 미래 예측, 비디오 객체 검색뿐만 아니라 일반적인 비디오 이해 및 이미지 객체 이해도 포함됩니다. 각 작업 유형에 대해 VideoRefer 모델이 생성한 결과의 예시 이미지와 함께 질문과 답변이 제시되어 있습니다. 이를 통해 VideoRefer 모델의 다양한 능력과 정확도를 시각적으로 확인할 수 있습니다.
read the caption
Figure 12: Visualization results of VideoRefer across various tasks, including single-object referring, video relationship analysis, complex reasoning, future prediction, video object retrieval, as well as general video understanding and image object understanding.

🔼 그림 13은 VideoRefer-700K 데이터셋의 시각적 예시를 보여줍니다. 간략한 설명, 자세한 설명, 그리고 질문과 답변(QA) 쌍을 포함하는 다양한 유형의 데이터가 포함되어 있습니다. 각 예시는 비디오 클립의 특정 영역을 가리키는 질문과 그에 대한 답변을 보여주며, 비디오에 대한 다양한 수준의 이해도를 평가하는 데 사용됩니다. 예시는 단순한 객체 설명에서부터 복잡한 관계 추론, 미래 예측까지 다양한 질문 유형을 다룹니다. 이 그림은 VideoRefer 모델이 다양한 유형의 비디오 이해 작업을 수행하는 능력을 보여주는 데 도움이 됩니다.
read the caption
Figure 13: Visual samples from our VideoRefer-700 dataset, typical including short descriptions, detailed descriptions, and QA pairs.
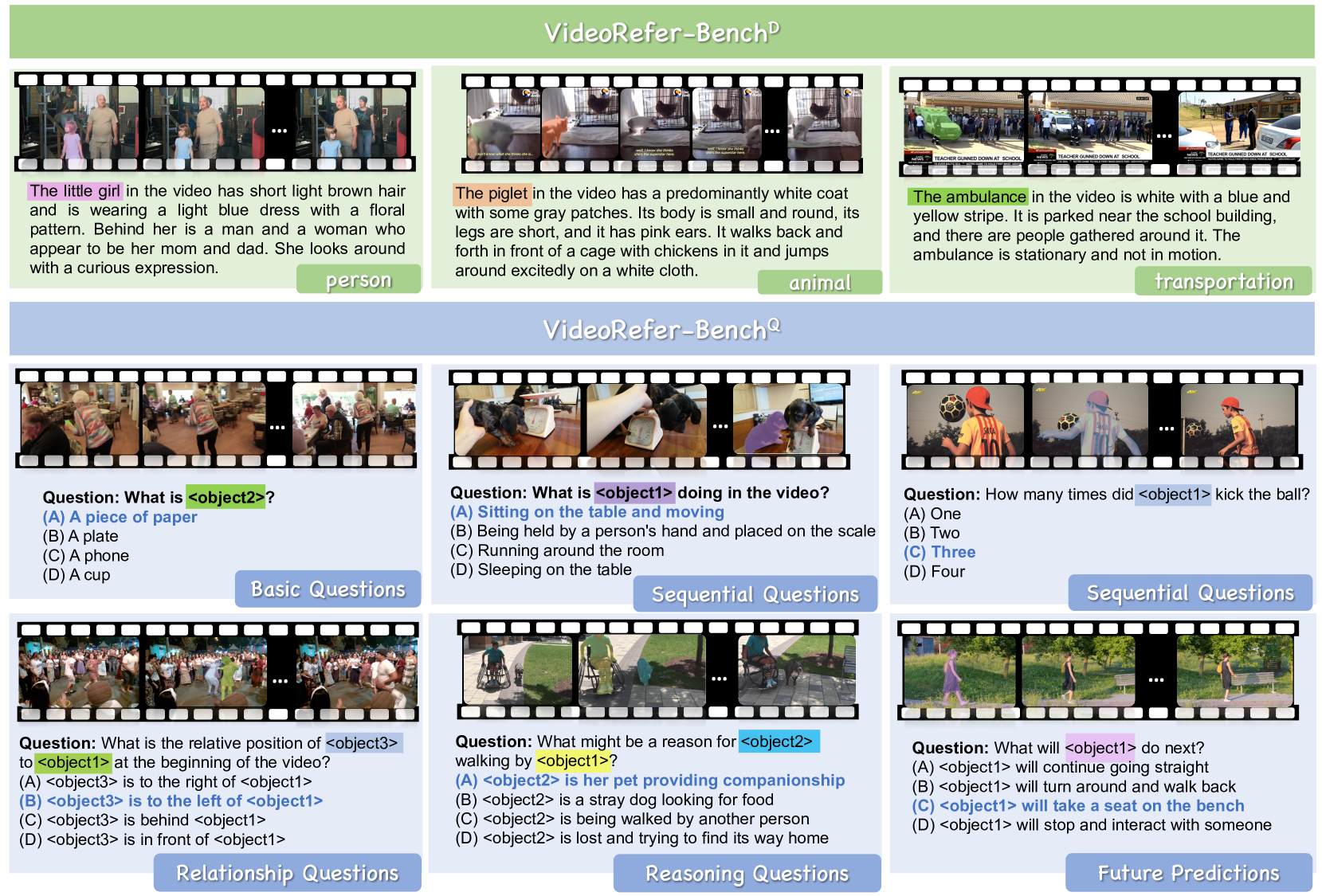
🔼 그림 14는 VideoRefer-Bench의 시각적 예시를 보여줍니다. VideoRefer-Bench는 설명 생성 작업을 평가하는 VideoRefer-BenchD와 다중 선택 질의응답 작업을 평가하는 VideoRefer-BenchQ의 두 가지 하위 벤치마크로 구성됩니다. VideoRefer-BenchD는 다양한 시각적 예시와 함께 객체에 대한 세부적인 설명을 생성하는 모델의 능력을 평가합니다. VideoRefer-BenchQ는 비디오에서 다양한 객체의 특징과 행동에 대한 이해도를 평가하는 다중 선택 질문을 포함합니다. 각 하위 벤치마크는 시각적 예시와 함께, 모델이 어떻게 다양한 유형의 질문에 답변하는지를 보여줍니다. 이 그림은 비디오 객체 참조, 시계열 이해 및 추론과 같은 다양한 비디오 이해 과제에서 VideoRefer 모델의 성능을 종합적으로 보여주는 데 도움이 됩니다.
read the caption
Figure 14: Visual examples of our VideoRefer-Bench, including VideoRefer-BenchDD{}^{\text{D}}start_FLOATSUPERSCRIPT D end_FLOATSUPERSCRIPT and VideoRefer-BenchQQ{}^{\text{Q}}start_FLOATSUPERSCRIPT Q end_FLOATSUPERSCRIPT.
More on tables
| Method | Basic Questions | Sequential Questions | Relationship Questions | Reasoning Questions | Future Predictions | Average |
|---|---|---|---|---|---|---|
| Generalist Models | ||||||
| GPT-4o [28] | 62.3 | 74.5 | 66.0 | 88.0 | 73.7 | 71.3 |
| GPT-4o-mini [28] | 57.6 | 67.1 | 56.5 | 85.9 | 75.4 | 65.8 |
| InternVL2-26B [8] | 58.5 | 63.5 | 53.4 | 88.0 | 78.9 | 65.0 |
| Qwen2-VL-7B [43] | 62.0 | 69.6 | 54.9 | 87.3 | 74.6 | 66.0 |
| Specialist Models | ||||||
| Osprey-7B [46] | 45.9 | 47.1 | 30.0 | 48.6 | 23.7 | 39.9 |
| Ferret-7B [44] | 35.2 | 44.7 | 41.9 | 70.4 | 74.6 | 48.8 |
| VideoRefer-7B | 75.4 | 68.6 | 59.3 | 89.4 | 78.1 | 71.9 |
🔼 표 2는 VideoRefer-BenchQ의 다양한 측면에서 모델 성능을 비교 분석한 결과를 보여줍니다. VideoRefer-BenchQ는 다중 선택 질문을 기반으로 비디오에 대한 이해도를 평가하는 벤치마크입니다. 표에는 기본 질문, 순차 질문, 관계 질문, 추론 질문, 미래 예측 질문 등 다양한 유형의 질문에 대한 모델의 정확도가 제시되어 있습니다. Elysium[41]과 Artemis[32]와 같은 일부 비디오 전문 모델은 다중 선택 질문을 처리할 수 없기 때문에 이 표에는 해당 모델의 결과가 포함되어 있지 않습니다. 각 질문 유형에 대한 정확도 외에도 평균 정확도가 계산되어 전체적인 모델 성능을 비교하는 데 도움을 줍니다.
read the caption
Table 2: Performance comparisons on VideoRefer-BenchQQ{}^{\text{Q}}start_FLOATSUPERSCRIPT Q end_FLOATSUPERSCRIPT. Note: Video-level specialist models, including Elysium [41] and Artemis [32], do not have the ability to handle multi-choice questions on VideoRefer-BenchQQ{}^{\text{Q}}start_FLOATSUPERSCRIPT Q end_FLOATSUPERSCRIPT.
| Method | BLEU@4 | METEOR | ROUGE_L | CIDER | SPICE |
|---|---|---|---|---|---|
| Merlin [45] | 3.3 | 11.3 | 26.0 | 10.5 | 20.1 |
| Artemis [32] | 15.5 | 18.0 | 40.8 | 53.2 | 25.4 |
| VideoRefer | 16.5 | 18.7 | 42.4 | 68.6 | 28.3 |
🔼 표 3은 HC-STVG [38] 테스트 세트에서 비디오 기반 참조 지표에 대한 실험 결과를 보여줍니다. 비디오 참조 작업에서 VideoRefer 모델의 성능을 평가하기 위해 다양한 지표 (BLEU@4, METEOR, ROUGE-L, CIDEr, SPICE)를 사용하여 기존 방법들과 비교 분석한 결과를 제시합니다. 이를 통해 VideoRefer 모델이 비디오 참조 작업에서 얼마나 효과적인지 정량적으로 보여줍니다.
read the caption
Table 3: Exprimental results on video-based referring metrics on the HC-STVG [38] test set.
| Method | Perception-Test | MVBench | VideoMME |
|---|---|---|---|
| VideoLLaMA2 [9] | 51.4 | 54.6 | 47.9/50.3 |
| VideoLLaMA2.1 [9] | 54.9 | 57.3 | 54.9/56.4 |
| Artemis [32] | 47.1 | 34.1 | 28.8/35.3 |
| VideoRefer | 56.3 | 59.6 | 55.9/57.6 |
🔼 표 4는 일반적인 비디오 이해 작업에 대한 실험 결과를 보여줍니다. VideoLLaMA2.1 모델의 Perception-Test, MVBench, VideoMME 세 가지 벤치마크에 대한 성능 점수와 VideoRefer 모델의 동일한 벤치마크에 대한 성능 점수를 비교하여 VideoRefer 모델의 성능 향상을 보여줍니다. 각 벤치마크는 비디오 이해의 다양한 측면을 평가합니다. 즉, VideoRefer 모델이 일반적인 비디오 이해 작업에서도 우수한 성능을 보임을 나타냅니다.
read the caption
Table 4: Exprimental results on general video understanding tasks.
| Mode | VideoRefer-BenchD | VideoRefer-BenchQ | |||||
|---|---|---|---|---|---|---|---|
| Mode | TD | HD | Avg. | SQ | RQ | Avg. | |
| — | — | — | — | — | — | — | — |
| Single-frame | 3.03 | 2.97 | 3.42 | 68.3 | 59.1 | 71.9 | |
| Multi-frame | 3.10 | 3.04 | 3.46 | 70.6 | 60.5 | 72.1 |
🔼 표 5는 추론 과정에서 단일 프레임 모드와 다중 프레임 모드를 사용했을 때의 결과를 보여줍니다. 단일 프레임 모드는 비디오의 특정 프레임 하나만을 사용하는 반면, 다중 프레임 모드는 여러 프레임을 사용하여 시간적 맥락을 고려합니다. 표에는 각 모드에서의 Subject Correspondence(SC), Appearance Description(AD), Temporal Description(TD), Hallucination Detection(HD) 평균 점수와 Sequential Questions(SQ), Relationship Questions(RQ) 평균 점수가 포함되어 있습니다. SQ와 RQ는 비디오의 객체에 대한 순차적 질문과 관계적 질문에 대한 정확도를 나타냅니다. 이를 통해 단일 프레임과 다중 프레임 모드가 비디오 이해 작업에 미치는 영향을 비교 분석할 수 있습니다.
read the caption
Table 5: Results using different modes during the inference. Here, SQ and RQ are Sequential Questions and Relationship Questions.
| Method | BenchD | BenchQ | MVBench |
|---|---|---|---|
| 0 w/o Regional data | – | – | 57.9 |
| 1 + Short description | 2.43 | 68.3 | 58.0 |
| 2 + QA | 2.45 | 71.7 | 58.4 |
| 3 + Detailed description | 3.42 | 71.9 | 59.6 |
🔼 표 6은 VideoRefer-700K 데이터셋에서 다양한 데이터 유형에 대한 ablation 결과를 보여줍니다. 간단히 하기 위해 Bench는 VideoRefer-Bench를 나타냅니다. 이 표는 짧은 설명, 상세 설명, 그리고 질문과 답변 쌍을 포함한 세 가지 유형의 객체 수준 비디오 지시 데이터를 사용하여 VideoRefer 모델의 성능을 비교 분석한 결과입니다. 각 데이터 유형을 사용했을 때 VideoRefer-BenchD와 VideoRefer-Bench, 그리고 MVBench에서 달성한 점수를 보여주어, 어떤 유형의 데이터가 모델 성능 향상에 가장 효과적인지 확인할 수 있도록 합니다. 특히, 상세 설명 데이터가 포함되었을 때 가장 좋은 성능을 보임을 알 수 있습니다.
read the caption
Table 6: Ablation results on various data types in VideoRefer-700K dataset. Bench denotes VideoRefer-Bench for simplicity.
| Union | VideoRefer-BenchD | VideoRefer-BenchQ |
|---|---|---|
u | VideoRefer-BenchD | VideoRefer-BenchQ |
| TD | HD | SQ |
| 32 | 3.17 | 3.01 |
| 16 | 3.20 | 2.99 |
| 8 | 3.18 | 3.02 |
| 4 | 3.10 | 3.04 |
| 1 | 3.08 | 2.98 |
🔼 표 7은 TTM(Temporal Token Merge) 모듈의 다중 프레임 모드에서 다양한 유니온 수(u)에 따른 시간적 및 순차적 성능 비교 결과를 보여줍니다. 다양한 u 값에 따른 VideoRefer-BenchD(설명 생성) 및 VideoRefer-BenchQ(질문 답변)의 TD(시간적 설명), HD(환각 검출), SQ(순차적 질문), RQ(관계 질문) 성능을 비교 분석하여 최적의 유니온 수를 결정하는 데 사용되었습니다.
read the caption
Table 7: Temporal and sequential performance comparisons for various union u𝑢uitalic_u in the TTM module under multi-frame mode.
| Manually True | Manually False | |
|---|---|---|
| Reviewer True | 88 (TP) | 12 (FP) |
| Reviewer False | 36 (FN) | 64 (TN) |
🔼 표 8은 검토자 평가에서 무작위로 추출한 100개 항목에 대한 혼동 행렬을 보여줍니다. TP(참 양성), TN(참 음성), FP(거짓 양성), FN(거짓 음성)의 개수를 보여주는 2x2 행렬로, 검토자의 성능을 평가하는 데 사용됩니다. 각 셀의 값은 검토자의 판단과 실제 정답 간의 일치 여부를 나타내며, 정확도, 재현율, F1 점수와 같은 성능 지표를 계산하는 데 사용됩니다. 이 표는 VideoRefer-700K 데이터셋의 품질 관리 과정에서 검토자의 성능을 평가하는 데 중요한 역할을 합니다.
read the caption
Table 8: Confusion matrix of the randomly sampled 100 items in the Reviewer evaluation.
Full paper#
















