↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
소프트웨어 엔지니어링(SWE) 분야는 최근 몇 년 동안 괄목할 만한 발전을 이루었지만, 여전히 실제 세계의 문제를 해결하는 데 어려움을 겪고 있습니다. 기존의 벤치마크는 합성 데이터나 불완전한 정보를 사용하여 실제 상황과 차이가 있으며, 에이전트의 일반화 능력과 실제 적용 가능성을 제한합니다. 또한, 기존 모델들은 주로 독점적인 모델에 의존하여 연구의 재현성과 확장성을 저해하는 문제점이 있습니다.
본 논문에서는 실제 GitHub 이슈 데이터를 기반으로 한 새로운 훈련 환경인 SWE-Gym을 제시합니다. SWE-Gym은 실제 코드베이스, 실행 가능한 환경, 단위 테스트를 포함하고 있어 기존 데이터셋보다 현실적인 문제 해결에 도움을 줍니다. 연구진은 SWE-Gym을 사용하여 에이전트 모델을 훈련시킨 결과, 기존 최고 성능 대비 최대 19%의 성능 향상을 달성했습니다. 또한, 에이전트의 궤적을 사용하여 검증자 모델을 훈련시켜 추론 시간을 단축하는 방법도 제시했습니다. SWE-Gym, 모델, 그리고 에이전트 궤적은 공개적으로 배포되어 다른 연구자들의 후속 연구를 지원합니다.
Key Takeaways#
Why does it matter?#
본 논문은 소프트웨어 엔지니어링 분야에서 실제 문제 해결에 초점을 맞춘 새로운 훈련 환경인 SWE-Gym을 제시하여 연구자들에게 큰 영향을 미칩니다. SWE-Gym은 실제 GitHub 이슈를 기반으로 구축되어 있어 기존의 합성 데이터셋보다 현실적이며, 에이전트와 검증자 모델 모두의 성능 향상을 가져왔습니다. 본 연구는 추후 연구를 위한 새로운 방향을 제시하고, 소프트웨어 엔지니어링 분야의 발전에 기여할 것입니다.
Visual Insights#

🔼 그림 1은 SWE-Gym을 사용하여 소프트웨어 엔지니어링 에이전트의 성능을 향상시키는 방법을 보여줍니다. 위쪽 그래프는 학습 데이터(궤적)의 수가 증가함에 따라 성능이 일관되게 향상됨을 보여줍니다. 491개의 궤적을 사용했을 때에도 성능 향상이 포화되지 않았습니다. 아래쪽 그래프는 추론 시간에 따른 성능 향상을 보여줍니다. SWE-Gym에서 학습된 검증자를 사용하여 후보 궤적을 생성하고 최상의 궤적을 선택하는 방법을 사용했습니다. 이 방법은 샘플링된 해결책의 수가 증가함에 따라 대략 로그 방식으로 성능이 향상됨을 보여줍니다. 온도 매개변수(t)는 위쪽 그래프에서는 0으로, 아래쪽 그래프에서는 첫 번째 가설에 일관성을 유지하기 위해 0으로 설정하고 이후 0.5로 설정했습니다.
read the caption
Figure 1: SWE-Gym enables scalable improvements for software engineering agents. Top: Training time scaling shows consistent performance improvements as we obtain more training trajectories, with no signs of saturation at 491 trajectories. We use temperature t=0𝑡0t=0italic_t = 0. Bottom: For inference time scaling, we generate a number of candidate trajectories per task and select the best using a verifier trained on SWE-Gym. This approach demonstrates roughly logarithmic gains with the number of sampled solutions. t=0𝑡0t=0italic_t = 0 (excluded from regression) is used as the first hypothesis to be consistent with the top figure; later rollouts use t=0.5𝑡0.5t=0.5italic_t = 0.5.
| Dataset (split) | Repository-Level | Executable Environment | Real task | # Instances (total) | # Instances (train) |
|---|---|---|---|---|---|
| CodeFeedback (Zheng et al., 2024b) | ✗ | ✗ | ✓ | 66,383 | 66,383 |
| APPS (Hendrycks et al., 2021a) | ✗ | ✓ | ✓ | 10,000 | 5,000 |
| HumanEval (Chen et al., 2021) | ✗ | ✓ | ✓ | 164 | 0 |
| MBPP (Tao et al., 2024) | ✗ | ✓ | ✓ | 974 | 374 |
| R2E (Jain et al., 2024) | ✓ | ✓ | ✗ | 246 | 0 |
| SWE-Bench (train) (Jimenez et al., 2024) | ✓ | ✗ | ✓ | 19,008 | 19,008 |
| SWE-Gym Raw | ✓ | ✗ | ✓ | 66,894 | 66,894 |
| SWE-Bench (test) (Jimenez et al., 2024) | ✓ | ✓ | ✓ | 2,294 | 0 |
| SWE-Gym | ✓ | ✓ | ✓ | 2,438 | 2,438 |
🔼 표 1은 SWE-Gym의 특징을 요약하여 보여줍니다. SWE-Gym은 GitHub 이슈에서 발췌한 실제 소프트웨어 엔지니어링 작업을 사용하는 최초의 공개적으로 이용 가능한 훈련 환경입니다. 각 작업에는 사전 설치된 종속성과 실행 가능한 테스트 검증이 포함되어 있습니다. 이 표는 세 가지 주요 특징을 중심으로 데이터셋을 비교 분석합니다. 첫째, 리포지토리 수준(Repository-level)은 각 작업이 정교한 리포지토리에 있는지 여부를 나타냅니다. 둘째, 실행 가능한 환경(Executable Environment)은 리소스의 각 인스턴스에 모든 관련 종속성이 사전 설치된 실행 가능한 환경이 있는지 여부를 나타냅니다. 셋째, 실제 작업(Real task)은 각 인스턴스에 대한 지침이 실제 개발자들로부터 수집되었는지 여부를 나타냅니다.
read the caption
Table 1: SWE-Gym is the first publicly-available training environment combining real-world software engineering tasks from GitHub issues with pre-installed dependencies and executable test verification. Repository-level: whether each task is situated in a sophisticated repository; Executable Environment: whether each instance in the resource comes with an executable environment with all relevant dependencies pre-installed; Real task: whether the instruction for each instance is collected from human developers.
In-depth insights#
SWE-Gym Overview#
SWE-Gym은 실제 소프트웨어 엔지니어링(SWE) 작업을 기반으로 하는 최초의 훈련 환경입니다. 2,438개의 실제 Python 작업 인스턴스를 포함하며, 각 인스턴스는 실행 가능한 런타임 환경, 단위 테스트, 자연어로 작성된 작업 설명을 포함합니다. 이를 통해 연구진은 언어 모델 기반 SWE 에이전트를 훈련시켜, SWE-Bench Verified 및 Lite 테스트 세트에서 성능을 크게 향상시켰습니다. 특히 추론 시간 확장을 위한 검증자 훈련도 가능하며, 이를 통해 새로운 최첨단 기술을 달성했습니다. 공개적으로 SWE-Gym, 모델 및 에이전트 경로를 공개하여 추가 연구를 촉진합니다. 이는 기존의 합성 데이터나 제한적인 환경과 달리, 실제 SWE 환경의 복잡성과 다양성을 반영하여 더욱 현실적인 에이전트 훈련을 가능하게 합니다. 실험 결과는 훈련 시간 및 추론 시간 확장 모두에서 지속적인 성능 향상을 보여줍니다. 다양한 에이전트 구조에도 적용 가능하며, 향후 SWE 에이전트 연구 발전에 중요한 역할을 할 것으로 기대됩니다.
Agent Training#
본 논문에서 제시된 에이전트 훈련 방법은 실제 소프트웨어 엔지니어링 작업을 기반으로 하며, SWE-Gym 환경 내에서 강화 학습 방식을 사용합니다. 다양한 에이전트 구조와 **정책 개선 알고리즘(예: rejection sampling fine-tuning)**을 통해 실험을 진행하며, SWE-Bench Lite 및 Verified 데이터셋을 사용하여 성능을 평가합니다. 대규모 언어 모델을 기반으로 하는 에이전트는 SWE-Gym의 실제 환경에서의 경험을 통해 성능 향상을 보이며, 이는 합성 데이터 기반 훈련의 한계를 극복하는 것을 의미합니다. 특히, 추론 시간 단축을 위한 검증자(verifier) 훈련 및 다중 솔루션 샘플링을 통한 최적 솔루션 선택이라는 흥미로운 접근 방식을 제시합니다. 이러한 결과는 실제 세계 문제 해결에 더욱 효과적인 소프트웨어 엔지니어링 에이전트 개발의 가능성을 보여줍니다.
Verifier Models#
본 논문에서 제시된 검증자 모델은 소프트웨어 엔지니어링 에이전트의 성능 향상에 중요한 역할을 합니다. 에이전트가 생성한 코드 패치의 정확성을 평가하고, 다양한 후보 솔루션 중 최적의 솔루션을 선택하는 데 사용됩니다. 이는 에이전트의 추론 시간을 효율적으로 확장하는 데 기여하며, 검증자 모델의 학습을 통해 얻은 지식을 활용하여 에이전트의 성능을 간접적으로 향상시키는 효과가 있습니다. 특히, 다양한 에이전트 아키텍처와 훈련 데이터에 대한 실험을 통해 검증자 모델의 일반화 성능과 확장성을 확인하였으며, 이를 통해 실제 소프트웨어 개발 환경에 적용 가능성을 높였습니다. 다만, 검증자 모델의 정확성은 에이전트의 성능에 직접적인 영향을 미치므로, 향후 연구에서는 검증자 모델의 정확도 향상 및 훈련 데이터의 질 개선에 더욱 집중해야 할 것입니다.
Scalability Results#
본 논문에서 제시된 연구는 소프트웨어 엔지니어링 작업에 대한 에이전트의 확장성을 평가하는 데 중점을 두고 있습니다. 훈련 시간 확장성 결과는 더 많은 훈련 데이터가 모델 성능 향상에 기여함을 보여줍니다. 특히, 포화 상태 없이 지속적인 성능 향상이 관찰되었다는 점은 주목할 만합니다. 추론 시간 확장성에 대한 분석에서는 검증기를 활용하여 후보 솔루션을 여러 개 생성하고 가장 우수한 것을 선택함으로써 성능 향상을 달성할 수 있음을 보여줍니다. 이는 계산 비용 증가에 따른 로그 성장을 보이는 효율적인 방법임을 시사합니다. 모델 크기 역시 성능에 영향을 미치는 중요한 요소로, 더 큰 모델이 일반적으로 더 나은 결과를 산출하는 것으로 나타났습니다. 전반적으로, 본 연구의 확장성 결과는 제안된 방법의 실용성과 효율성을 강조하며, 향후 연구를 위한 토대를 마련합니다. 데이터 크기의 영향 또한 탐구되었으며, 다양한 데이터 샘플링 전략에 대한 실험 결과는 데이터 다양성의 중요성을 시사하지만, 단순히 데이터 양을 늘리는 것만으로는 최적의 성능을 보장할 수 없다는 점을 보여줍니다.
Future Directions#
본 논문은 소프트웨어 엔지니어링 에이전트 및 검증자를 위한 새로운 훈련 환경인 SWE-Gym을 제시합니다. 미래 방향으로는, 첫째, 더욱 다양하고 복잡한 실제 세계의 소프트웨어 엔지니어링 작업을 포함하도록 SWE-Gym의 규모를 확장하는 것입니다. 둘째, 에이전트의 일반화 능력을 향상시키기 위해 다양한 프로그래밍 언어와 코드베이스를 지원하는 방향으로 발전시킬 수 있습니다. 셋째, 에이전트 학습을 위한 효율적인 알고리즘 개발 및 적용이 필요합니다. 강화 학습, 전이 학습 등의 기법을 활용하여 더욱 효과적이고 효율적인 학습 방식을 모색해야 합니다. 마지막으로, 다양한 평가 지표를 개발하고 적용하여 에이전트의 성능을 객관적으로 평가하는 체계를 마련해야 합니다. 단순한 성공률 뿐 아니라, 코드 품질, 유지보수성, 실행 속도 등 다양한 측면을 고려한 종합적인 평가가 필요합니다.
More visual insights#
More on figures

🔼 그림 2는 SWE-Gym 인스턴스의 저장소 분포를 보여줍니다. 각 저장소에서 가져온 인스턴스의 수를 시각적으로 표현하여, SWE-Gym 데이터셋 내에서 각 저장소의 상대적 중요도를 보여줍니다. 데이터셋의 균형과 다양성을 파악하는 데 도움이 됩니다.
read the caption
Figure 2: Repository distribution of SWE-Gym instances.

🔼 그림 3은 7B 모델을 사용하여 제로샷 방식으로 SWE-Gym Lite에서 30라운드에 걸쳐 작업 성공 분포를 보여줍니다. 자연스럽게 쉬운 작업에 치우쳐지는 경향이 나타납니다. 인스턴스별 상한선 설정을 통해 이러한 편향을 줄일 수 있지만, 그로 인해 학습에 사용할 수 있는 전체 경로 수가 감소합니다. 샘플링 과정에서는 온도 매개변수 t를 1로 설정했습니다. 즉, 모델이 예측에서 다양한 결과를 생성할 확률이 높습니다. 이 그림은 데이터 샘플링 방법의 영향을 시각적으로 보여주어, 쉬운 작업 위주 샘플링의 문제점과 인스턴스별 상한선 설정을 통한 해결 방안의 장단점을 비교 분석하는 데 도움을 줍니다.
read the caption
Figure 3: Success distribution over 30 rounds on SWE-Gym Lite with 7B model in zero-shot. The distribution is naturally biased toward easy tasks. Per instance capping reduces this bias but lowers the total trajectory count for training. We set temperature t=1𝑡1t=1italic_t = 1 during sampling.

🔼 그림 4는 미세 조정된 검증자를 사용하여 SWE-Bench Verified에서 추론 시간 계산을 확장하면 성능이 향상됨을 보여줍니다. 에이전트와 검증자 모두 해당 데이터 세트(§4.1.1)에서 미세 조정된 Qwen2.5-Coder-Instruct-32B 모델입니다. 에이전트 스캐폴드로는 OpenHands(Wang et al., 2024c)가 사용됩니다. 첫 번째 롤아웃은 온도 t=0으로 수행되었고, 나머지는 t=0.5로 수행되었습니다. 이 그림은 다양한 수의 에이전트 롤아웃(k)에 따른 Pass@k와 Best@k 지표의 변화를 보여줍니다. Pass@k는 k개의 샘플링된 경로 중 적어도 하나의 성공적인 솔루션을 찾는 작업의 비율을 나타내고, Best@k는 가장 높은 검증 점수를 가진 경로를 선택하고 선택된 경로 중 성공적인 것의 비율을 보고합니다. 이 그림은 계산을 확장하여 성능이 향상되는 것을 보여주며, 특히 Best@k 지표는 로그 스케일에서 선형성을 보여주어 확장 가능성이 있음을 시사합니다.
read the caption
Figure 4: Scaling inference-time compute improves performance on SWE-Bench Verified using a fine-tuned verifier. Both the agent and the verifier are Qwen2.5-Coder-Instruct-32B model fine-tuned on the corresponding dataset (§4.1.1). OpenHands (Wang et al., 2024c) is used as the agent scaffold. The first rollout was performed with temperature t=0𝑡0t=0italic_t = 0, and t=0.5𝑡0.5t=0.5italic_t = 0.5 was used for the rest.
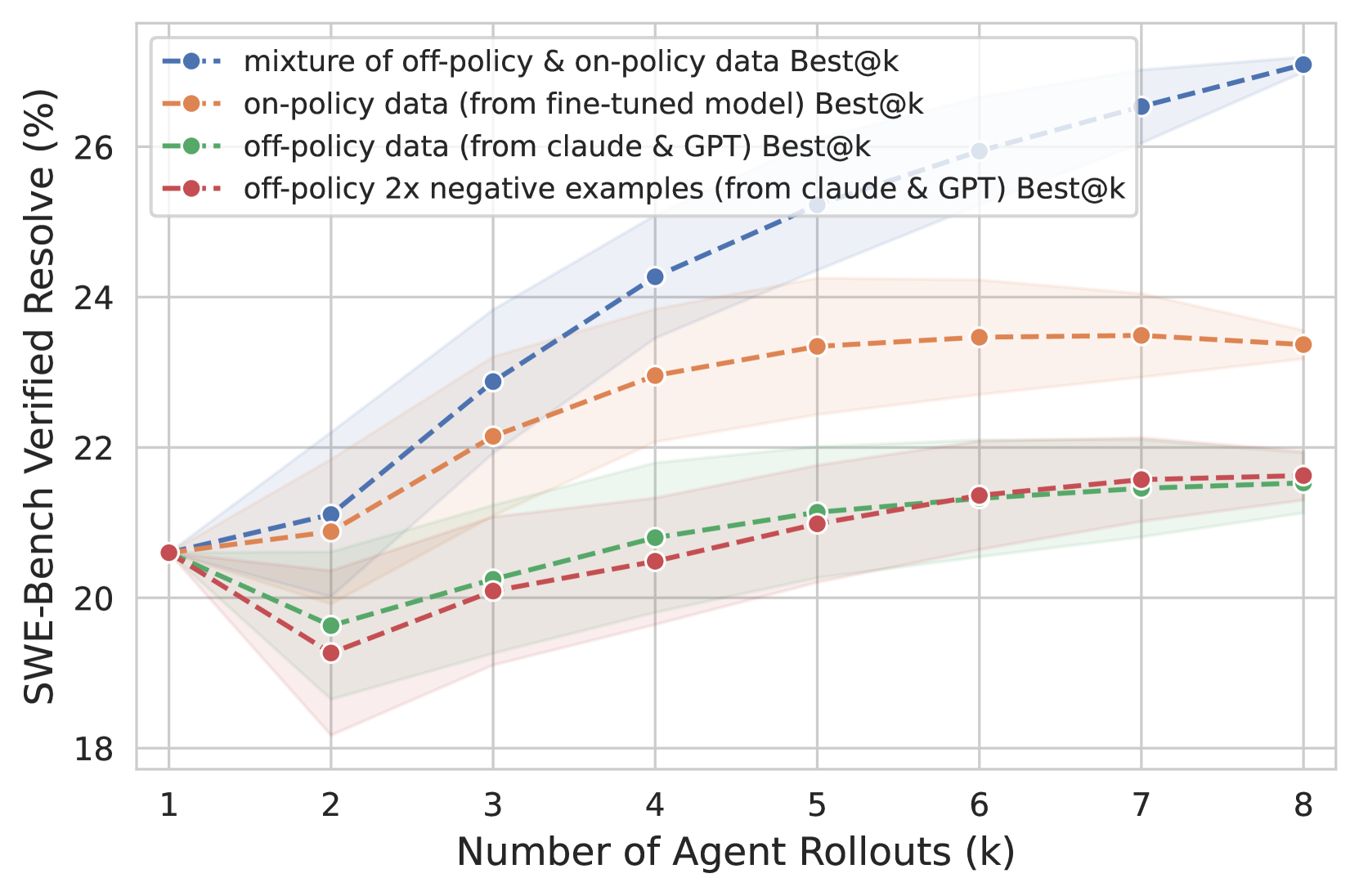
🔼 그림 5는 검증자 훈련에 대한 ablation 연구 결과를 보여줍니다. 성능은 SWE-Bench Verified 데이터셋을 기준으로 평가되었으며, 에이전트와 검증자 모두 Qwen-2.5-Coder-Instruct-32B 모델을 사용하여 해당 데이터셋으로 미세 조정되었습니다. 에이전트 스캐폴드로는 OpenHands (Wang et al., 2024c)가 사용되었습니다. 그림은 다양한 훈련 데이터(off-policy 데이터, on-policy 데이터, 두 데이터의 혼합)를 사용했을 때 검증자의 성능 변화를 보여줍니다. off-policy 데이터만 사용했을 때는 성능 향상이 제한적이었고, on-policy 데이터만 사용했을 때는 중간 정도의 성능 향상을 보였습니다. 반면, off-policy와 on-policy 데이터를 혼합하여 사용했을 때 가장 좋은 성능을 보였습니다. 이는 검증자 훈련에 다양한 데이터를 사용하는 것이 중요함을 시사합니다.
read the caption
Figure 5: Abaltion study for verifier training (§4.1.1). Performances are evaluated on SWE-Bench Verified. Both the agent and the verifier are Qwen2.5-Coder-Instruct-32B model fine-tuned on the corresponding dataset (§4.1.1). OpenHands (Wang et al., 2024c) is used as the agent scaffold.

🔼 그림 6은 학습된 검증자를 사용하는 MoatlessTools 에이전트에 대한 추론 시간 컴퓨팅의 확장성을 보여줍니다. 샘플링 중 온도(temperature)를 t=0.5로 설정했음을 보여줍니다. 이 그래프는 여러 개의 에이전트 경로를 샘플링하여 최상의 솔루션을 선택하는 데 검증자가 얼마나 효과적으로 확장되는지 보여줍니다. x축은 에이전트 롤아웃 수(샘플링된 솔루션 수)이고 y축은 SWE-Bench Lite에서의 해결률을 나타냅니다. 이를 통해 계산량을 늘림으로써 성능을 향상시킬 수 있음을 보여줍니다.
read the caption
Figure 6: Scaling inference-time compute for MoatlessTools Agents with learned verifiers. We set temperature t=0.5𝑡0.5t=0.5italic_t = 0.5 during sampling.

🔼 그림 7은 학습 데이터 크기가 모델 성능에 미치는 영향을 보여줍니다. 로그베이스 2 스케일로 표현된 x축은 사용된 학습 데이터의 비율을 나타내고, y축은 SWE-Bench Verified에서 평가된 모델의 해결률을 나타냅니다. 7B 및 32B 모델 모두 학습 데이터가 증가함에 따라 성능이 향상되는 것을 보여주며, 특히 32B 모델에서 그 효과가 더욱 두드러집니다. 이는 SWE-Gym의 현재 크기와 저장소 다양성이 성능의 병목 현상을 야기하지 않으며, 더 많은 학습 데이터를 확보할 경우 성능 향상이 가능함을 시사합니다.
read the caption
Figure 7: Model performance scaling with training data size. The x-axis shows the percentage of training data used in log base 2 scale.

🔼 그림 8은 SWE-Bench Verified 데이터셋을 사용하여 32B 모델을 평가한 세 가지 데이터 샘플링 방법(중복 제거 없음, 저장소 기반 샘플링, 무작위 샘플링)의 비교 결과를 보여줍니다. 각 방법에 대해 훈련 데이터의 25%, 50%, 100%를 사용하여 모델을 훈련시켰고, 그 결과를 비교 분석했습니다. 이 그림은 데이터 샘플링 전략이 모델 성능에 미치는 영향을 보여주는 시각적 자료입니다. 특히, 중복 제거 여부, 저장소 기반 샘플링 방식, 그리고 무작위 샘플링 방식의 차이에 따른 성능 변화를 보여주는 것이 핵심입니다.
read the caption
Figure 8: Comparison of three data sampling approaches: without deduplication, repository-based sampling, and random sampling (§4.2). All variants use the 32B model evaluated on SWE-Bench Verified.
More on tables
| ↑) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | zero-shot | fine-tuned | Δ | zero-shot | fine-tuned | Δ | zero-shot | fine-tuned | Δ | zero-shot | fine-tuned | Δ |
| 7B | 40.3 | 29.7 | -10.7 | 47.0 | 31.0 | -16.0 | 20.3 | 22.2 | +1.9 | 1.0 (± 1.0) | 10.0 (± 2.4) | +9.0 |
| 14B | 49.7 | 18.1 | -31.6 | 31.7 | 27.1 | -4.6 | 23.2 | 21.4 | -1.8 | 2.7 (± 1.9) | 12.7 (± 2.3) | +10.0 |
| 32B | 27.0 | 18.1 | -8.9 | 16.7 | 18.1 | +1.5 | 15.5 | 29.3 | +13.9 | 3.0 (± 1.4) | 15.3 (± 2.5) | +12.3 |
SWE-Bench Verified (500 instances)
| Model | Empty Patch (%, ↓) | | | Stuck in Loop (%, ↓) | | | Avg. Turn(s) | | | Resolve Rate (%,
| ↑) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | zero-shot | fine-tuned | Δ | zero-shot | fine-tuned | Δ | zero-shot | fine-tuned | Δ | zero-shot | fine-tuned | Δ |
| 7B | 45.8 | 33.8 | -12.0 | 39.6 | 21.0 | -18.6 | 21.9 | 35.3 | +13.4 | 1.8 (± 1.1) | 10.6 (± 2.1) | +8.8 |
| 14B | 44.9 | 14.5 | -30.4 | 32.1 | 21.3 | -10.7 | 25.5 | 30.1 | +4.6 | 4.0 (± 1.6) | 16.4 (± 2.0) | +12.4 |
| 32B | 9.5 | 13.8 | +4.3 | 29.4 | 23.8 | -5.6 | 24.6 | 31.6 | +7.0 | 7.0 (± 1.3) | 20.6 (± 2.1) | +13.6 |
🔼 표 3은 OpenHands 에이전트 스캐폴드를 사용하여 SWE-Bench(Jimenez et al., 2024)에서 491개의 SWE-Gym 샘플링된 경로에 대해 미세 조정된 모델 성능을 보여줍니다. 기본 모델로 Qwen-2.5-Coder-Instruct를 사용하고 평가를 위해 온도 t=0을 설정했습니다. 표에는 모델 크기, 빈 패치 비율, 루프에 갇히는 비율, 평균 턴 수, SWE-Bench Lite 및 SWE-Bench Verified에서의 해결률 변화율 등의 정보가 포함되어 있습니다. 각 지표는 모델의 성능을 다각적으로 평가하는 데 유용한 정보를 제공합니다.
read the caption
Table 3: Model performance (fine-tuned on 491 SWE-Gym-sampled trajectories) on SWE-Bench (Jimenez et al., 2024) using OpenHands (Wang et al., 2024c) as agent scaffold. We use Qwen-2.5-Coder-Instruct as the base model. We set temperature t=0𝑡0t=0italic_t = 0 for evaluation.
| ↑) | |||
|---|---|---|---|
| 0 (Zero-shot) | 0 | 56.3 | 7.0 |
| 1 | 36 | 37.3 | 9.0 |
| 2 | 62 | 29 | 9.7 |
| 3 | 82 | 43.7 | 7.7 |
| No Cap (All) | 172 | 30.7 | 9.3 |
🔼 표 4는 7B 모델을 사용하여 훈련 데이터의 인스턴스 캡핑 전략에 따라 다른 수의 궤적(Traj)을 사용하여 훈련한 후 SWE-Bench Lite에서 계산된 해결률(Resolve Rate)과 빈 패치율(Empty Patch Rate)을 보여줍니다. 인스턴스 캡핑 전략(Cap)이 다르면 사용되는 궤적의 수가 달라집니다. 즉, 훈련 데이터의 크기와 난이도에 따른 모델 성능의 변화를 보여주는 표입니다.
read the caption
Table 4: Resolve rate and empty patch rate on SWE-Bench Lite after 7B model trained with with data from different instance capping strategies (Cap) and therefore different number of trajectories (Traj).
| Setting | 7B Model | 32B Model | ||
|---|---|---|---|---|
| EP(%, | ||||
| ↓) | RR(%, | |||
| ↑) | EP(%, | |||
| ↓) | RR(%, | |||
| ↑) | ||||
| — | — | — | — | — |
| Zero-Shot | 56.3% | 7.0% | 24.3% | 19.0% |
| Iteration 1 | 29.0% | 9.0% | 18.3% | 19.7% |
| Iteration 2 | 23.3% | 10.0% | 9.7% | 19.7% |
🔼 표 5는 MoatlessTools Scaffold를 사용하여 온라인 리젝션 샘플링 파인튜닝 후 평가된 SWE-Bench Lite의 해결률(RR)과 빈 패치율(EP)을 보여줍니다. 온도 t=0에서 평가되었으며, 해결률은 강조 표시된 열에 나와 있습니다. 이 표는 모델이 자체적으로 학습하여 성능을 개선하는 방법과 온라인 리젝션 샘플링 방식이 성능 향상에 미치는 영향을 보여주는 실험 결과를 보여줍니다.
read the caption
Table 5: Resolve rate (RR) and Empty patch rate (EP) on SWE-Bench Lite with MoatlessTools Scaffold after online rejection sampling fine-tuning, evaluated at temperature t=0𝑡0t=0italic_t = 0. RR shown in highlighted columns.
| Model | SWE-Bench | Openness | ||
|---|---|---|---|---|
| Name, Model Size | Lite | Verified | Model | Environment |
| Ma et al. (2024), 72B | 22.0 | 30.2 | ✅ | ❌ |
| Golubev et al. (2024) Agent and Verifier, 72B | - | 40.6 | ❌ | ✅ |
| Our SWE-Gym Agent and Verifier, 32B | 26.0 | 32.0 | ✅ | ✅ |
🔼 표 6은 SWE-Bench 벤치마크에서 모델 성능과 모델 가중치 및 환경이 공개적으로 접근 가능한지 여부를 비교한 표입니다. 다시 말해, 각 모델의 성능(SWE-Bench Lite 및 Verified에서의 성능)과 해당 모델의 가중치와 실행 환경에 대한 접근성을 보여줍니다. 공개적으로 접근 가능한지 여부는 연구의 재현성과 다른 연구자들에 의한 후속 연구의 용이성 측면에서 중요한 의미를 가집니다.
read the caption
Table 6: Comparison of model performance on SWE-Bench benchmark and if the model weights and environments are publically accessible (openness).
| Original | Dedup. | Sorted by Random (Dedup.) | Sorted by Random (Dedup.) | Sorted by Repo (Dedup.) | Sorted by Repo (Dedup.) | |
|---|---|---|---|---|---|---|
| First 25% | First 50% | First 25% | First 50% | |||
| getmoto/moto | 155 | 72 | 12 | 33 | 0 | 46 |
| Project-MONAI/MONAI | 95 | 53 | 17 | 25 | 53 | 53 |
| pandas-dev/pandas | 70 | 61 | 14 | 30 | 0 | 0 |
| python/mypy | 46 | 27 | 7 | 12 | 0 | 0 |
| dask/dask | 45 | 29 | 8 | 17 | 6 | 29 |
| iterative/dvc | 36 | 24 | 8 | 12 | 0 | 0 |
| conan-io/conan | 20 | 12 | 1 | 7 | 12 | 12 |
| pydantic/pydantic | 11 | 7 | 2 | 4 | 0 | 0 |
| facebookresearch/hydra | 7 | 5 | 2 | 5 | 0 | 5 |
| bokeh/bokeh | 3 | 2 | 1 | 1 | 2 | 2 |
| modin-project/modin | 3 | 2 | 1 | 1 | 0 | 0 |
| Total | 491 | 294 | 73 | 147 | 73 | 147 |
🔼 표 7은 훈련 시간 확장 실험 (§4.2)에 사용된 성공적인 경로의 분포를 보여줍니다. ‘Dedup.‘은 인스턴스 ID당 성공적인 경로 하나를 무작위로 선택하여 중복을 제거했음을 나타냅니다. ‘무작위(저장소) 정렬 X%(Dedup.)‘은 중복을 제거한 인스턴스의 처음 X%에서 무작위로 (저장소 이름으로) 정렬된 성공적인 경로의 하위 집합을 나타냅니다.
read the caption
Table 7: Distribution of success trajectories used in training-time scaling experiments (§4.2). Dedup. denotes that the trajectories are deduplicated by randomly select ONE success trajectory per instance ID; Sorted by random (repo) X% (Dedup.) denotes a subset of trajectories taken from the first X% from dedup. instances that are sorted randomly (by repository name).
| Resolved | Count | Mean | Std | Min | Max | 5% | 10% | 25% | 50% | 75% | 90% | 95% | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Num. of Messages | ✗ | 5,557.0 | 39.2 | 31.9 | 7.0 | 101.0 | 9.0 | 9.0 | 9.0 | 29.0 | 61.0 | 100.0 | 101.0 |
| ✓ | 491.0 | 39.9 | 19.9 | 13.0 | 101.0 | 19.0 | 21.0 | 25.0 | 33.0 | 47.5 | 65.0 | 87.0 | |
| Num. of Tokens | ✗ | 5,557.0 | 17,218.3 | 17,761.6 | 1,615.0 | 167,834.0 | 1,833.0 | 1,907.0 | 2,268.0 | 12,305.0 | 26,434.0 | 41,182.2 | 51,780.6 |
| ✓ | 491.0 | 18,578.5 | 11,361.4 | 2,560.0 | 81,245.0 | 5,813.0 | 8,357.0 | 11,559.5 | 15,999.0 | 22,040.5 | 31,632.0 | 39,512.5 |
🔼 표 8은 SWE-Gym에서 샘플링된 경로들의 통계를 보여줍니다. 각 경로는 여러 개의 자연어 메시지와 토큰으로 구성되며, 평균적으로 39.9개의 메시지와 18,578개의 토큰을 포함하고 있습니다. 또한, 각 열은 경로의 메시지 수, 토큰 수, 사용된 토크나이저(Qwen-2.5-Coder-Instruct-7B)를 나타냅니다. 이 표는 SWE-Gym 데이터셋의 특징을 이해하는 데 도움을 줍니다.
read the caption
Table 8: Statistics of SWE-Gym-sampled trajectories. We use the tokenizer from Qwen-2.5-Coder-Instruct-7B to estimate the number of tokens.
| Agent | Model | Model Size | Training Data | Resolved (%) |
|---|---|---|---|---|
| RAG | SWE-Llama (Jimenez et al., 2024) | 7B | 10K instances | 1.4 |
| RAG | SWE-Llama (Jimenez et al., 2024) | 13B | 10K instances | 1.2 |
| Lingma Agent (Ma et al., 2024) | Lingma SWE-GPT (v0925) | 7B | 90K PRs from 4K repos | 18.2 |
| Lingma Agent (Ma et al., 2024) | Lingma SWE-GPT (v0925) | 72B | 90K PRs from 4K repos | 28.8 |
| OpenHands (Wang et al., 2024c) (Ours) | fine-tuned Qwen2.5-Coder-Instruct | 32B | 491 agent trajectories from 11 repos | 20.6 |
| OpenHands w/ Verifier (Wang et al., 2024c) (Ours) | fine-tuned Qwen2.5-Coder-Instruct | 32B (Agent & Verifier) | 491 agent trajectories from 11 repos for agent + 1318 × 2 success/failure agent trajectories for verifier | 32.0 |
🔼 표 9는 공개적으로 접근 가능한 가중치를 사용하는 SWE-Bench (Jimenez et al., 2024) 기준과의 성능 비교를 보여줍니다. SWE-Bench 기준 점수와 비교하여 본 논문에서 제시하는 모델들의 성능을 보여주는 여러 모델들의 해결률(%)을 비교 분석합니다. 데이터 출처는 https://www.swebench.com/이며, 2024년 12월 21일에 접근하였습니다.
read the caption
Table 9: Performance comparison with SWE-Bench (Jimenez et al., 2024) baselines with publicly accessible weights. Data source: https://www.swebench.com/, Accessed on Dec 21, 2024.
Full paper#


















