↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
현재의 대규모 비전-언어 모델(VLMs)은 열화상, 깊이 정보, X선 정보 등 다양한 멀티 비전 센서 데이터를 심층적으로 이해하지 못하고, 단순히 RGB 이미지 데이터에 의존하는 경향이 있습니다. 이는 VLMs가 복잡한 멀티 비전 센서 추론 문제를 해결하는 데 어려움을 겪는 주요 원인입니다.
본 연구에서는 이러한 문제를 해결하기 위해 새로운 벤치마크인 MS-PR을 제안합니다. MS-PR은 VLMs의 멀티 비전 센서 추론 능력을 평가하기 위한 다양한 작업을 포함하고 있으며, 특히 센서별 추론 능력을 평가하는 데 초점을 맞추고 있습니다. 또한, 제한된 데이터 환경에서도 VLMs의 성능을 향상시키기 위한 새로운 최적화 기법인 DNA를 제안합니다. 실험 결과, DNA를 적용한 VLMs는 멀티 비전 센서 추론 작업에서 성능이 크게 향상됨을 확인했습니다.
Key Takeaways#
Why does it matter?#
본 논문은 다양한 멀티 비전 센서 데이터에 대한 VLMs의 이해 능력 부족이라는 중요한 문제를 제기하고, 이를 해결하기 위한 새로운 벤치마크와 최적화 기법을 제시합니다. 이는 자율주행, 의료 영상 분석, IoT 등 다양한 분야에서 VLMs의 활용 가능성을 크게 높일 수 있어 연구자들에게 중요한 시사점을 제공합니다. 특히, 제한된 데이터 환경에서도 효과적인 학습을 가능하게 하는 DNA 최적화 기법은 향후 멀티모달 학습 연구에 큰 영향을 미칠 것으로 예상됩니다.
Visual Insights#

🔼 그림 1은 최근 VLMs [39, 53]의 다중 비전 센서 관련 질문과 응답 사례를 보여줍니다. 이 예시는 열화상 카메라를 이용한 사진에서 사슴이 배경보다 더 밝게 나타나는 이유를 묻는 질문에 대해, VLM이 햇빛 반사로 오답을 내리는 것을 보여줍니다. 이는 VLM이 다중 비전 센서의 고유한 물리적 특성을 제대로 이해하지 못한다는 어려움을 강조합니다. 즉, 단순히 이미지의 밝기 차이만 인식하고, 열 방출이라는 물리적 현상을 이해하지 못하는 VLM의 한계를 보여주는 것입니다.
read the caption
Figure 1: Multi-vision sensor related question and response examples of recent VLMs [39, 53]. Note that, this example underscores the difficulty that VLMs face in understanding physical properties unique to multi-vision sensors.
🔼 표 1은 MS-PR 벤치마크에서 다양한 VLMs의 성능 평가 결과를 정확도를 측정 기준으로 나타낸 것입니다. ‘다중 비전 인식’ 열은 시각적 인식 평가를 위한 네 가지 차원(존재, 계산, 위치, 일반 설명)에 대한 평균 성능을 보여주고, ‘다중 비전 추론’ 열은 시각적 감각 이해 평가를 위한 두 가지 차원(맥락 추론 및 감각 추론)에 대한 평균 성능을 보여줍니다. VLMs는 출시 날짜 순으로 정렬되어 있습니다.
read the caption
Table 1: Evaluation results of different VLMs on the MS-PR benchmark are reported, using accuracy as the metric. “Multi-vision Perception” shows the average performance on four dimensions (Existence, Count, Position, and General Description) for evaluating visual perception, and “Multi-vision Reasoning” shows the average performance on two dimensions (Contextual Reasoning and Sensory Reasoning) for evaluating vision sensory understanding. VLMs are sorted in ascending order of release date.
In-depth insights#
Multi-vision VLM Gap#
본 논문에서 제시된 ‘멀티비전 VLM 격차’는 기존의 비전-언어 모델(VLM)들이 다양한 멀티비전 센서(열화상, 심도, X선 등) 데이터를 제대로 이해하고 추론하는 데 어려움을 겪는 현상을 의미합니다. 이는 VLMs가 주로 RGB 이미지 데이터로 학습되어 실제 세계의 다양한 센서 특징을 제대로 반영하지 못하기 때문입니다. 각 센서의 물리적 특성을 고려하지 않고 표면적인 판단만 내리는 경향이 있으며, 멀티비전 센서 데이터의 고유한 특징들을 혼동하는 경우도 발생합니다. 이러한 격차는 자율주행, 보안 시스템, 의료 영상 진단 등 센서 정확도가 중요한 응용 분야에서 심각한 문제를 야기할 수 있습니다. 따라서 본 논문에서는 멀티비전 센서에 대한 VLMs의 이해 능력을 평가하고 향상시키기 위한 새로운 벤치마크(MS-PR)와 DNA 최적화 기법을 제안합니다.
MS-PR Benchmark#
본 논문에서 제시된 MS-PR 벤치마크는 다양한 멀티-비전 센서 데이터에 대한 VLMs의 이해 능력을 평가하기 위한 혁신적인 시도입니다. 기존의 벤치마크들이 주로 RGB 이미지 기반의 시각적 이해에 초점을 맞춘 것과 달리, MS-PR 벤치마크는 열화상, 깊이 정보, X-레이 이미지 등 다양한 센서 데이터를 포함, VLMs의 멀티-모달 이해 능력을 더욱 포괄적으로 평가합니다. 특히 센서 특유의 물리적 특성을 고려한 질문과 답변 세트를 통해 VLMs가 단순히 이미지 패턴을 인식하는 수준을 넘어, 센서 데이터의 본질적 의미를 이해하고 추론하는 능력을 평가하는 데 중점을 둡니다. 이는 자율주행, 의료 영상 분석 등 실제 응용 분야에서 VLMs의 성능을 더욱 정확하게 예측하는 데 도움이 될 것입니다. MS-PR 벤치마크의 주요 강점은 멀티-비전 센서 데이터에 대한 VLMs의 능력을 종합적으로 평가하는 데 있다고 할 수 있습니다. 향후 연구에서는 MS-PR 벤치마크의 데이터셋 확장 및 평가 지표 개선을 통해, 더욱 견고하고 실용적인 멀티-모달 모델 개발에 기여할 수 있을 것입니다.
DNA Optimization#
본 논문에서 제시된 DNA 최적화 기법은 데이터 부족 문제를 해결하기 위한 혁신적인 접근 방식입니다. 기존 강화 학습 기반 방법들과 달리, **다양한 부정적 속성(DNA)**을 활용하여 학습 과정에 다양성을 더하고, 단순히 RGB 이미지에 의존하는 한계를 극복하는 데 중점을 둡니다. 다양한 부정적 예시를 통해 모델이 잘못된 추론을 피하도록 유도하며, 제한된 데이터 환경에서도 효과적인 학습을 가능하게 합니다. 특히 멀티-비전 센서 데이터의 고유 특징을 이해하고 활용하는 데 효과적이며, 다양한 멀티-비전 센서 작업에서 성능 향상을 보여줍니다. 이는 실제 환경에 적용되는 VLMs의 성능 향상에 크게 기여할 것으로 기대됩니다.
VLM Reasoning#
본 논문에서 다룬 VLM 추론(Reasoning)은 다중 비전 센서 데이터에 대한 VLMs의 이해 능력 부족 문제를 다룹니다. 기존 VLMs는 RGB 이미지 중심으로 학습되어, 열화상, 심도, X선 등 다양한 센서 데이터의 물리적 특성을 제대로 이해하지 못하고 표면적인 판단에 그치는 경향이 있습니다. MS-PR 벤치마크는 이러한 문제점을 평가하기 위해 제안되었으며, 센서 특징에 대한 깊이 있는 이해를 요구하는 과제들을 포함하여 VLMs의 다중 비전 센서 추론 능력을 종합적으로 평가합니다. DNA 최적화 기법은 제한된 다중 비전 센서 데이터 환경에서 VLMs의 성능 향상을 위해 제안되었습니다. 이는 다양한 부정적 예시를 활용하여 VLMs의 추론 능력을 향상시키고, 단순한 RGB 이미지 기반 추론에서 벗어나도록 유도합니다. 실험 결과는 DNA 최적화를 통해 VLMs의 다중 비전 센서 추론 성능이 크게 향상됨을 보여주며, 실제 환경 적용을 위한 VLMs의 핵심적인 한계점과 개선 방향을 제시합니다.
Future of VLMs#
VLMs의 미래는 다중 비전 센서 이해 및 추론 능력의 향상에 달려 있습니다. 본 논문에서 제시된 MS-PR 벤치마크와 DNA 최적화 기법은 이러한 발전을 위한 중요한 이정표가 될 것입니다. 다양한 센서 데이터에 대한 깊이 있는 이해는 자율 주행, 의료 영상 분석, 보안 시스템 등 실세계 응용 분야에서 VLMs의 성능을 획기적으로 개선할 것입니다. 하지만, 데이터 부족 문제는 여전히 큰 걸림돌이며, 대규모 다중 비전 센서 데이터셋 구축이 시급합니다. 또한, VLMs의 물리적 세계에 대한 이해를 높이기 위한 연구가 더욱 활발히 진행되어야 합니다. 설명 가능성 (Explainability) 및 일반화 능력 (Generalization) 향상도 중요한 과제이며, 앞으로 VLMs의 발전 방향을 결정하는 데 큰 영향을 미칠 것입니다. 궁극적으로, 인간 수준의 다중 감각 지능을 가진 VLMs의 개발이 미래의 목표이며, 이를 위해서는 인간-기계 협력적 연구가 필수적입니다.
More visual insights#
More on figures

🔼 그림 2는 논문의 MS-PR 벤치마크에 대한 데이터 샘플들을 보여줍니다. MS-PR 벤치마크는 VLMs의 다중 비전 센서 이해 능력을 평가하기 위한 벤치마크로, 다중 비전 지각 과제(존재, 계산, 위치, 일반적인 설명) 4가지 유형과 다중 비전 추론 과제(맥락적 추론 및 감각적 추론) 2가지 유형을 포함합니다. 그림은 각 과제 유형에 대한 질문과 답변의 예시를 보여주어, MS-PR 벤치마크가 VLMs의 다중 센서 데이터 해석 및 추론 능력을 어떻게 평가하는지 보여줍니다.
read the caption
Figure 2: Data samples of Multi-vision Sensor Perception and Reasoning (MS-PR) benchmark for evaluating the abilities of VLMs in multi-vision sensor understanding, which covers four types of multi-vision perception tasks (Existence, Counting, Position, and General Description) and two types of multi-vision reasoning tasks (Contextual Reasoning and Sensory Reasoning).
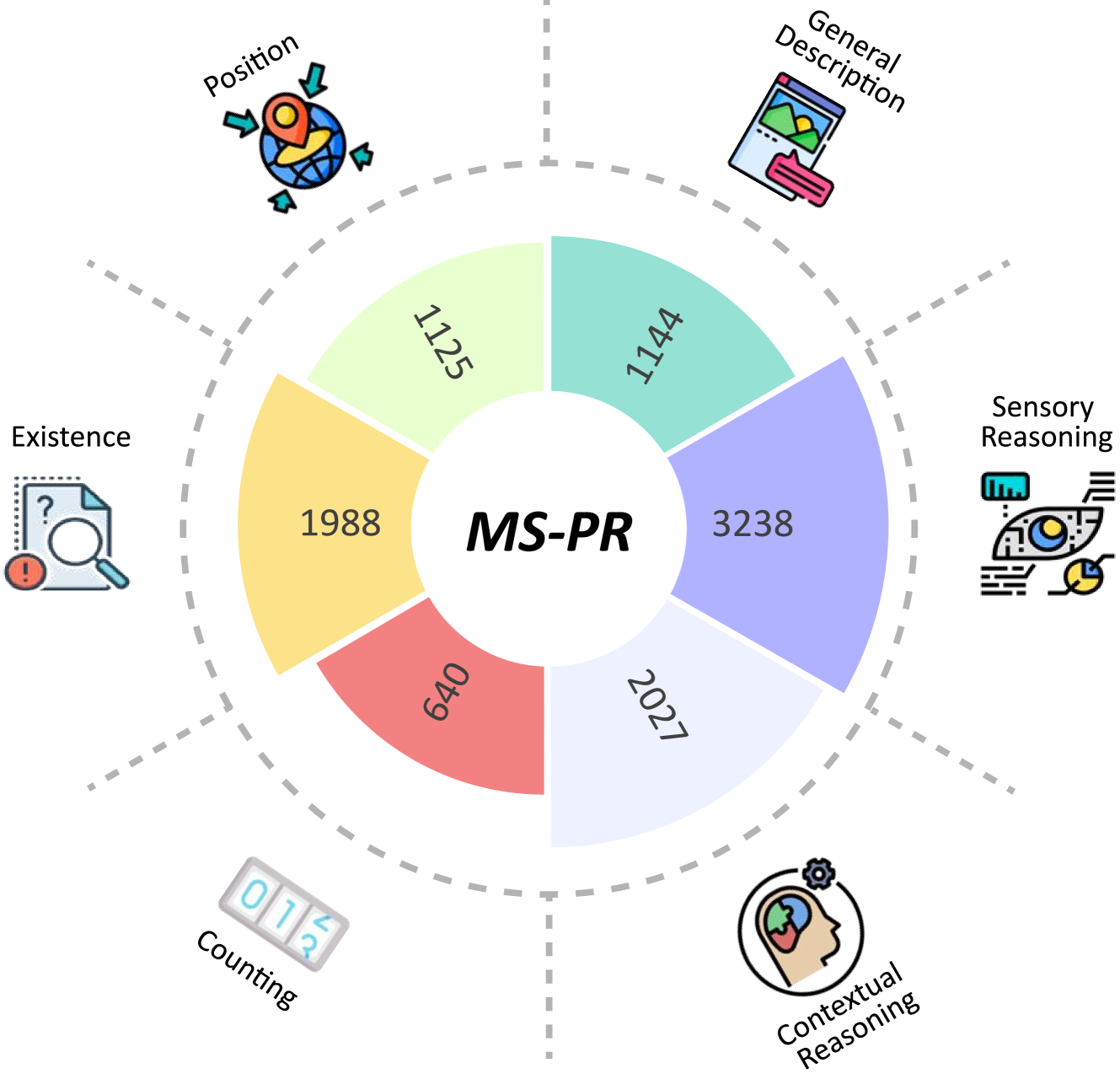
🔼 그림 3은 MS-PR 벤치마크의 데이터 분포를 보여줍니다. 바깥쪽 원은 6가지 핵심 다중 비전 센서 작업(존재, 계산, 위치, 일반 설명, 상황 추론, 감각 추론)을 나타내고, 안쪽 원은 각 작업에 대한 샘플 수를 보여줍니다. 이 그림은 MS-PR 벤치마크에 사용된 각 센서 유형(열화상, 깊이, X선)의 데이터 양을 시각적으로 보여주어, 벤치마크의 구성과 균형을 이해하는 데 도움이 됩니다. 각 작업의 샘플 수는 데이터 셋의 크기와 균형을 보여주는 지표입니다.
read the caption
Figure 3: Distribution of data sources of the MS-PR benchmark. In MS-PR, we demonstrate six core multi-vision sensor tasks in the outer ring, and the inner ring displays the number of samples for each specific task.

🔼 그림 4는 제안된 벤치마크 데이터셋 생성 파이프라인의 개요를 보여줍니다. 다양한 멀티비전 센서와 작업에 대한 지식이 담긴 프롬프트를 기반으로 ChatGPT/GPT-4가 어려운 질문과 답변 세트를 생성합니다. 이후, 인간 어노테이터를 활용하여 데이터셋을 더욱 개선하고, 긍정적 및 부정적 답변 세트를 구성하여 각 쌍을 특정 평가 차원으로 분류합니다. 이는 실제 환경을 정확하게 반영하는 벤치마크 데이터셋을 만드는 데 중요한 과정입니다.
read the caption
Figure 4: Overview of the pipeline for generating the proposed benchmark dataset. Based on the prompts corresponding to knowledge on multi-vision sensors and tasks, ChatGPT/GPT-4o generates challenging question and answer set. We refine the dataset further by utilizing human annotators to construct positive and negative sets, allowing each pair to be classified into a specific evaluation dimension.

🔼 그림 5는 다양한 멀티 비전 센서(열화상, 심도, X선)에 대한 지식 정보와 질문 유형 및 예시를 보여줍니다. 각 센서의 물리적 특성과 응용 분야에 대한 설명과 함께, 각 센서 유형에 적합한 다양한 질문 유형(객체 인식, 개수 세기, 위치 관계, 장면 설명, 상황 추론, 센서 추론)과 구체적인 질문 예시를 제시하여, 멀티 비전 센서 이해를 위한 벤치마크 데이터셋 구축에 대한 이해를 돕습니다.
read the caption
Figure 5: Description of sensor knowledge information and questions types and examples.

🔼 그림 6은 다양한 멀티 비전 센서 작업에 대한 어려운 객관식 질문과 답변을 생성하기 위한 프롬프트에 대한 설명입니다. 이 프롬프트는 센서 지식, 작업 유형 및 예시 질문을 포함하여 모델이 다양한 센서 유형(열, 깊이, X선)의 이미지에 대한 질문을 생성하고, 정답과 함께 여러 개의 그럴듯하지만 틀린 답변을 제공하도록 안내합니다. 이를 통해 멀티 비전 센서에 대한 심층적인 이해 능력을 평가할 수 있는 데이터셋을 효율적으로 생성할 수 있습니다.
read the caption
Figure 6: Description of prompts for generating challenging multiple-choice questions and answers for multi-vision sensor tasks

🔼 그림 7은 다양한 Vision-Language Model(VLM)에 걸쳐 인간의 다중 비전 감각 추론 성과에 대한 합의 결과를 보여줍니다. 다양한 VLM(LLaVA-1.5-7B, Qwen2-VL-7B, InternVL2-8B, Phantom-7B, GPT-40)이 다중 비전 감각 추론 작업에서 얼마나 잘 수행하는지, 그리고 이들의 성능이 인간의 수행 능력과 어떻게 비교되는지를 보여주는 막대 그래프입니다. 각 모델의 정확도를 백분율로 제시하여, 모델들의 상대적 성능을 비교하고 인간의 평균 정확도와 비교 분석합니다. 이는 다중 비전 데이터에 대한 VLMs의 이해도와 추론 능력을 평가하는 데 도움이 됩니다.
read the caption
Figure 7: Human Agreement Results on Multi-Vision Sensory Reasoning Performance Across Diverse VLMs

🔼 그림 8은 논문의 ‘3.1 다중 비전 센서 인식 및 추론(MS-PR) 벤치마크’ 섹션에 속하며, 다중 비전 센서(열화상, 깊이, X선)에 대한 다양한 최첨단 VLMs의 성능을 비교 분석한 것입니다. 특히, ‘존재(Existence)‘라는 다중 비전 인식 작업에 초점을 맞추고 있습니다. 각 센서 유형에 대해 질문과 보기가 제시되고, 정답은 녹색, 오답은 빨간색으로 표시되어 VLMs의 정확성을 시각적으로 보여줍니다. 이 그림은 다양한 VLMs이 다중 비전 센서 데이터를 얼마나 잘 이해하고 해석하는지, 특히 개체의 존재 여부를 파악하는 능력을 비교하는 데 도움이 됩니다.
read the caption
Figure 8: The comparison of performance across different multi-vision sensors with respect to the representative VLMs in the Multi-vision Perception task (Existence). Green font denotes the correct answer, while red font denotes the incorrect answer.

🔼 그림 9는 논문의 ‘3.1 다중 비전 센서 인식 및 추론(MS-PR) 벤치마크’ 섹션에 포함된 그림으로, 다중 비전 센서(열화상, 깊이, X선) 데이터에 대한 다양한 최첨단 비전-언어 모델(VLMs)의 성능을 비교 분석한 것입니다. 특히, ‘개수 세기’라는 인식 과제에 초점을 맞추고 있으며, 각 센서 유형에 따른 질문과 정답에 대해 모델의 정확성을 시각적으로 보여줍니다. 녹색 글꼴은 정답을, 빨간색 글꼴은 오답을 나타냅니다. 이 그림을 통해 각 모델이 서로 다른 센서 유형의 데이터를 얼마나 잘 이해하고 처리하는지, 그리고 각 모델의 강점과 약점을 파악할 수 있습니다.
read the caption
Figure 9: The comparison of performance across different multi-vision sensors with respect to the representative VLMs in the Multi-vision Perception task (Counting). Green font denotes the correct answer, while red font denotes the incorrect answer.

🔼 그림 10은 다양한 VLMs(Vision-Language Models)의 다중 비전 센서(열화상, 깊이, X선)에 대한 성능 비교를 보여줍니다. 특히, 다중 비전 지각 과제 중 ‘위치’에 초점을 맞추고 있습니다. 정답은 녹색, 오답은 붉은색으로 표시되어 VLMs의 정확도를 명확하게 보여줍니다. 각 센서 유형에 따라 모델의 성능 차이를 시각적으로 비교하여, 어떤 유형의 센서 데이터에서 특정 VLM이 잘 작동하고 어떤 유형에서는 잘 작동하지 않는지를 보여줍니다.
read the caption
Figure 10: The comparison of performance across different multi-vision sensors with respect to the representative VLMs in the Multi-vision Perception task (Position). Green font denotes the correct answer, while red font denotes the incorrect answer.

🔼 그림 11은 다양한 멀티 비전 센서(열화상, 깊이, X선)에 대한 대표적인 VLM(Vision-Language Model)들의 성능을 비교 분석한 것입니다. 멀티 비전 지각 과제 중 일반적인 설명(General Description)에 초점을 맞추고 있습니다. 각 질문에 대해 VLM이 선택한 답변이 표시되어 있으며, 정답은 녹색, 오답은 빨간색으로 표시되어 VLMs의 성능을 직관적으로 보여줍니다. 각 센서 유형별로 VLM이 얼마나 정확하게 이미지의 내용을 설명하는지, 즉 일반적인 시각적 특징을 이해하고 기술하는 능력을 평가합니다.
read the caption
Figure 11: The comparison of performance across different multi-vision sensors with respect to the representative VLMs in the Multi-vision Perception task (General Description). Green font denotes the correct answer, while red font denotes the incorrect answer.

🔼 그림 12는 다양한 멀티 비전 센서(열화상, 깊이, X선)에 대해 대표적인 VLMs(LLaVA, InternVL2, Phantom, DNA 적용 Phantom)의 성능을 비교 분석한 결과를 보여줍니다. 특히 멀티 비전 추론 과제 중 문맥적 추론에 초점을 맞추고 있습니다. 각 센서 유형에 대한 질문과 보기가 제시되고, 정답은 녹색, 오답은 빨간색으로 표시되어 VLMs의 문맥적 추론 능력을 시각적으로 비교 분석합니다.
read the caption
Figure 12: The comparison of performance across different multi-vision sensors with respect to the representative VLMs in the Multi-vision Reasoning task (Contextual Reasoning). Green font denotes the correct answer, while red font denotes the incorrect answer.
More on tables
| General | Description |
|---|
🔼 표 2는 다양한 VLMs에 대한 다중 비전 센서 인식 및 추론 성능을 보여줍니다. DNA 최적화를 통해 다중 비전 센서 추론 성능이 향상되었음을 보여주는 결과입니다. 각 VLMs의 다중 비전 센서 인식(존재, 계산, 위치, 일반 설명)과 추론(맥락적 추론, 감각적 추론)에 대한 평균 정확도가 제시되어 있습니다. 각 열의 최고 성능은 굵게 표시되어 있습니다.
read the caption
Table 2: Performance is increased by Diverse Negative Attributes (DNA) optimization in the sense of multi-vision reasoning. Highlighted columns show average performance for perception and reasoning capabilities. The best results are denoted in bold.
| Multi-vision | |
|---|---|
| Perception |
🔼 표 3은 다양한 수의 부정적 예시(k)를 사용하여 다중 비전 센서 추론 성능에 대한 추가 분석 결과를 보여줍니다. 여러 개의 부정적 예시를 사용함으로써 모델이 다양한 상황에서 센서 데이터를 더 잘 이해하고 추론하는 데 도움이 되는지 확인하는 실험입니다. 이 표는 특히 상황 추론 및 감각 추론 과제에서 부정적 예시의 수가 증가함에 따라 성능이 향상됨을 보여줍니다. 즉, 다양한 부정적 예시는 다중 비전 센서에 대한 이해도를 높이는 데 효과적임을 보여줍니다.
read the caption
Table 3: Ablation study on multi-vision sensor reasoning performance according to the number of negative sample k𝑘kitalic_k.
| Contextual | Reasoning |
|---|
🔼 표 4는 다양한 센서 유형(열화상, 깊이, X선)에 대해 학습 이미지 수(n)를 변경하면서 다양한 비전 언어 모델(VLMs)의 멀티 비전 센서 추론 성능 변화를 보여줍니다. 각 센서 유형별로 50개와 100개의 이미지를 사용한 실험 결과를 보여주며, SFT(Supervised Fine-Tuning)와 DNA(Diverse Negative Attributes) 최적화 기법을 적용한 경우와 그렇지 않은 경우의 성능 차이를 비교 분석합니다. 멀티 비전 인식(Existence, Count, Position, General Description)과 멀티 비전 추론(Contextual Reasoning, Sensory Reasoning)의 두 가지 주요 과제에 대한 성능을 평가하여 DNA 최적화가 제한된 데이터 환경에서도 멀티 비전 센서 추론 성능 향상에 효과적임을 보여줍니다.
read the caption
Table 4: Ablation study on multi-vision sensor reasoning performance according to the number of training images per sensor n𝑛nitalic_n
| Sensory | |
|---|---|
| Reasoning |
🔼 표 5는 다양한 벤치마크에서 DNA 최적화 적용 유무에 따른 Phantom-7B 모델의 성능 비교 결과를 보여줍니다. 단순한 성능 비교를 넘어, DNA 최적화가 다양한 유형의 벤치마크 작업에서 얼마나 일반화된 성능 향상을 가져오는지 보여주는 표입니다. 각 벤치마크의 세부적인 특징과 Phantom-7B 모델의 DNA 최적화 전후 성능 변화를 정량적으로 비교하여 모델의 견고성과 일반화 능력을 평가합니다.
read the caption
Table 5: Performance comparison of Phantom-7B with and without DNA optimization across various benchmarks.
Full paper#



















