↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
현재의 멀티모달 대규모 언어 모델(MLLM)은 영상에 대한 세밀한 이해가 부족하여 다양한 시각적 과제에서 성능이 제한적입니다. 기존 연구들은 특정 시각 과제에 초점을 맞춰 MLLM의 성능을 향상시키려 했으나, 전체적인 멀티모달 성능 저하를 초래하는 경우가 많았습니다. 이러한 문제점을 해결하기 위해 본 논문에서는 **시각적 과제 정렬을 통한 작업 선호도 최적화(TPO)**라는 새로운 방법론을 제시합니다.
TPO는 학습 가능한 작업 토큰을 사용하여 여러 개의 과제별 헤드와 MLLM 간의 연결을 강화합니다. 풍부한 시각적 레이블을 활용하여 MLLM의 멀티모달 능력과 과제별 성능을 향상시키는 것이 핵심입니다. 다중 과제 공동 학습을 통해 개별 과제의 성능을 단일 과제 학습보다 훨씬 향상시키는 시너지 효과를 확인하였습니다. VideoChat과 LLaVA 모델에 적용한 결과, 기존 모델 대비 멀티모달 성능이 14.6% 향상되었으며, 다양한 과제에서 강력한 제로샷 성능을 보였습니다.
Key Takeaways#
Why does it matter?#
본 논문은 **멀티모달 대규모 언어 모델(MLLM)**의 시각적 과제 수행 능력 향상에 중점을 두고 있어, 영상 이해 및 멀티모달 처리 분야 연구자들에게 중요한 의미를 지닙니다. 제안된 TPO 방법론은 다양한 시각 과제에 적용 가능하며, 향후 연구를 위한 새로운 방향을 제시하고 다른 모달리티로의 확장 가능성을 시사합니다. 최첨단 성능을 달성한 실험 결과는 MLLM의 성능 향상에 대한 깊이 있는 통찰력을 제공합니다.
Visual Insights#

🔼 그림 1은 제시된 논문에서 제안하는 TPO(Task Preference Optimization) 방법의 개념을 보여줍니다. TPO는 다양한 세분화된 시각적 작업(예: 공간적 위치 파악, 시간적 순서 파악, 객체 추적 등)에 대한 학습 가능한 작업 토큰(task token)을 사용하여 다중 모드 대규모 언어 모델(MLLM)의 성능을 향상시키는 방법입니다. 각 작업별 헤드(task-specific head)를 통해 밀집된 시각적 지도 데이터(dense visual supervision)에서 얻은 미분 가능한 작업 선호도(differentiable task preferences)를 활용하여 MLLM의 세부적인 이해 능력을 높입니다. 즉, 다양한 시각적 작업들을 MLLM에 효과적으로 통합하여 보다 정확하고 정교한 시각 정보 처리를 가능하게 합니다.
read the caption
Figure 1: TPO uses differentiable task preferences from dense visual supervisions via task-specific heads to enhance MLLMs in fine-grained understanding.
| Task | Samples | Datasets |
|---|---|---|
| Segmentation | 114.6K | MeViS [18], SAMv2 [69] |
| Temporal Grounding | 116.5K | ActivityNet [7], TACoS [70], QVHighlight [39], DiDeMo [27], QuerYD [63], HiREST [107], NLQ [25] |
| Spatial Grounding | 540.0K | Allseeing-V2 [85], Visual Genome [37], RefCOCO [103], RefCOCO+ [103], RefCOCOg [59] |
| Conversation | 3M | YouCook2 [17], ActivityNet [7], VideoChat2-IT [48], ShareGPT-4o [14], LLaVA-Hound-DPO [113], ShareGPT4V [10] |
🔼 표 1은 논문에서 제안하는 TPO(Task Preference Optimization) 방법론의 다양한 시각적 작업에 사용된 데이터셋을 개괄적으로 보여줍니다. 각 작업 유형(분할, 시간적 지정, 공간적 지정, 대화)별로 사용된 데이터셋의 종류와 개수를 나타내어 TPO의 훈련 과정에 사용된 데이터의 범위와 특징을 이해하는 데 도움을 줍니다. 세부적으로는 각 데이터셋의 이름과 해당 작업 유형에 대한 데이터 수량이 명시되어 있어 TPO 모델의 훈련 및 성능 평가에 사용된 데이터의 규모와 다양성을 파악할 수 있게 합니다.
read the caption
Table 1: Overview of Datasets Used in TPO for Various Tasks.
In-depth insights#
Visual Task Alignment#
본 논문에서 제시된 “Visual Task Alignment” 개념은 **멀티모달 대규모 언어 모델(MLLM)**이 시각적 과제를 보다 정확하고 세밀하게 이해할 수 있도록 하는 핵심 전략입니다. 이는 단순히 이미지나 비디오를 이해하는 것을 넘어, **세분화된 시각적 작업(예: 객체 추적, 시간적 구분, 공간적 배치 파악)**에 대한 명확한 이해를 달성하는 데 중점을 둡니다. 기존의 MLLM은 종합적인 인식 능력을 갖추었지만, 미묘한 시각적 차이를 정확하게 구분하는 데 어려움을 겪는다는 점을 고려할 때, 이러한 정렬 과정은 매우 중요합니다. **차별화 가능한 작업 선호도(differentiable task preferences)**를 활용하여 MLLM이 특정 시각적 작업에 집중할 수 있도록 유도하는 것이 핵심이며, 이를 통해 개별 작업 성능 향상뿐 아니라 전반적인 멀티모달 성능 향상이라는 시너지 효과를 창출합니다. **다양한 시각적 과제 헤드(task-specific heads)**를 도입하여 MLLM의 시각적 처리 능력을 강화하고, 학습 과정에서 **풍부한 시각적 레이블(rich visual labels)**을 활용하여 모델의 정확도를 높입니다. 결과적으로, **제로샷 성능(zero-shot capability)**이 향상되어 다양한 시각적 과제에서 최첨단 지도 학습 모델에 필적하는 성능을 보입니다.
TPO Optimization#
본 논문에서 제시된 TPO(Task Preference Optimization)는 다양한 시각적 과제에 대한 미세한 이해도를 높이기 위해 다중 모드 대규모 언어 모델(MLLM)의 능력을 향상시키는 새로운 방법론입니다. TPO는 학습 가능한 과제 토큰을 통해 여러 과제 특유의 헤드와 MLLM 간의 연결을 구축하고, 시각적 과제로부터 유도된 미분 가능한 과제 선호도를 활용하여 모델을 미세 조정합니다. 이를 통해 MLLM은 다양한 시각적 과제에서 로버스트한 제로샷 성능을 달성하며, 개별 과제 성능을 향상시킬 뿐만 아니라, 다중 과제 공동 학습을 통해 시너지 효과를 창출합니다. 실험 결과는 TPO가 다양한 벤치마크에서 우수한 성능을 보여주며, 특히 공간적, 시간적 세분화된 시각적 과제에서 탁월한 능력을 입증합니다. TPO의 확장성과 다양한 MLLM 접근 방식 및 과제에 대한 적응성도 뛰어난 것으로 나타났습니다. 본 연구는 다중 모드 모델의 시각적 이해 능력을 향상시키는 데 있어 TPO의 잠재력을 보여주는 중요한 결과입니다.
Multimodal Gains#
본 논문에서 제시된 다양한 실험 결과들은 멀티모달 학습의 강점을 명확히 보여줍니다. 특히, 비전 관련 하위 작업들(예: 공간적, 시간적 구분, 추적 등)을 개별적으로 학습시키는 것보다 통합적인 멀티모달 접근 방식이 훨씬 더 우수한 성능을 달성한다는 것을 확인했습니다. 이는 서로 다른 작업들이 상호 보완적으로 작용하여 시너지 효과를 창출하기 때문입니다. 예를 들어, 시간적 구분 작업의 향상은 추적 작업의 성능 향상으로 이어지고, 이는 다시 멀티모달 대화 능력을 향상시키는 선순환 구조를 형성합니다. TPO(Task Preference Optimization) 기법을 통해 이러한 멀티모달 이점을 극대화함으로써, 기존의 단일 작업 학습 방식을 뛰어넘는 성능 향상을 얻을 수 있었습니다. 제로샷 성능 역시 주목할 만하며, 이는 TPO가 다양한 작업에 대한 강인성과 일반화 능력을 갖추었음을 시사합니다. 따라서, 멀티모달 모델 개발에 있어서 통합적이고 최적화된 접근 방식의 중요성을 강조하며, 향후 연구는 더욱 다양한 작업과 데이터 규모를 고려한 확장성을 확보하는 데 초점을 맞춰야 합니다.
Scalability & Limits#
본 논문에서 제시된 방법의 확장성과 한계에 대한 심층적인 고찰은 다양한 모달리티와 작업 규모에 대한 적응력을 평가하는 데 중점을 둡니다. 대규모 언어 모델의 구조적 특징과 훈련 과정의 복잡성으로 인해, 모든 종류의 시각적 과제에 대한 일반화 능력과 효율성을 보장하기는 어렵습니다. 따라서 제한된 데이터셋이나 특정 유형의 시각적 과제에 대한 과적합 가능성을 고려해야 합니다. 다양한 시각적 과제의 상호작용 및 연관성을 효과적으로 활용하여 일반화 성능을 높이는 방안에 대한 탐구가 필요하며, 모델의 계산 비용 및 메모리 사용량 최소화를 위한 효율적인 훈련 기법 개발 또한 중요한 과제입니다. 궁극적으로, 제시된 방법론의 실제 적용 가능성과 한계를 명확히 파악하여, 더욱 강력하고 확장 가능한 다중 모달 대규모 언어 모델의 발전을 위한 방향을 제시하는 것이 중요합니다.
Future of TPO#
TPO의 미래는 확장성과 일반화 능력의 향상에 달려 있습니다. 현재 TPO는 특정 시각적 과제에 대한 성능 향상에 초점을 맞추고 있지만, 다양한 모달리티와 복잡한 시각적 이해 과제에 대한 적용 가능성을 높이는 것이 중요합니다. 더욱 다양한 시각적 과제 데이터셋을 활용하여 훈련 데이터의 규모를 확장하고, 다양한 유형의 시각적 과제에 대한 일반화 능력을 강화해야 합니다. 또한, **다른 모달리티 (예: 청각, 촉각)**와의 통합을 통해 보다 포괄적인 멀티모달 이해를 가능하게 하는 연구가 필요하며, 설명 가능성 및 투명성 향상을 위한 연구도 중요합니다. 에너지 효율적인 훈련 방법에 대한 연구도 필수적입니다. 지속적인 연구를 통해 TPO가 더욱 강력하고, 효율적이며, 일반화된 멀티모달 대규모 언어 모델을 개발하는데 기여할 것으로 기대합니다.
More visual insights#
More on figures

🔼 그림 2는 제시된 세 가지 학습 방법(PPO, DPO, TPO)을 비교하여 보여줍니다. 각 방법은 다양한 모듈(MLLM, Reward Model, Task Head 등)로 구성되며, 데이터 흐름과 피드백 메커니즘을 화살표로 표시합니다. 실선은 데이터의 흐름을, 점선은 피드백을 나타냅니다. 각 모듈이 학습 과정에서 고정되는지( ), 학습에 참여하는지( ) 여부를 명확히 구분하여, 세 가지 방법의 차이점을 시각적으로 이해할 수 있도록 합니다. 특히 TPO는 DPO와 유사하지만, 시각적 레이블을 활용하여 MLLM의 시각적 이해 능력을 향상시키는 점이 다릅니다.
read the caption
Figure 2: Comparison of Learning Method. A solid line indicates data flow, and a dotted line represents feedback. and denote modules that are frozen and unfrozen.
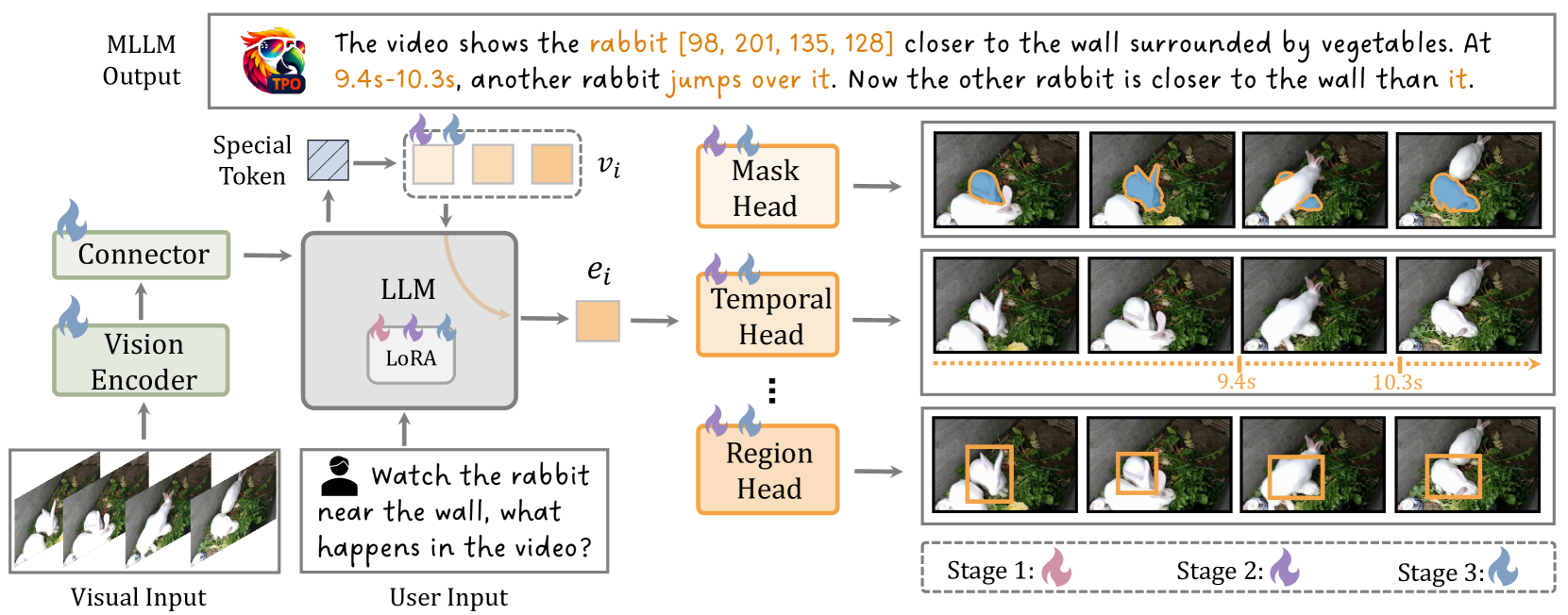
🔼 그림 3은 제안하는 TPO(Task Preference Optimization) 모델의 전체 구조를 보여줍니다. TPO는 크게 네 가지 구성 요소로 이루어져 있습니다. 첫째, 비전 인코더(Vision Encoder)는 입력 영상을 처리하여 특징 벡터를 추출합니다. 둘째, 커넥터(Connector)는 비전 인코더로부터 얻은 특징 벡터와 사용자의 질문을 결합합니다. 셋째, 대규모 언어 모델(Large Language Model)은 커넥터로부터 받은 정보를 기반으로 응답을 생성합니다. 마지막으로, 여러 개의 비전 작업 헤드(Visual Task Heads)는 대규모 언어 모델의 출력에 연결되어 특정 비전 작업(예: 영역, 시간, 마스크)을 수행합니다. 그림에서 다른 색상의 불꽃 기호는 학습 과정의 각 단계에서 어떤 구성 요소가 고정되고 어떤 구성 요소가 학습되는지 나타냅니다. 이는 다양한 비전 작업을 효율적으로 처리하고 전체적인 다중 모드 성능을 향상시키기 위한 TPO의 핵심 메커니즘을 보여줍니다.
read the caption
Figure 3: Overall Pipeline of TPO. The architecture of Task Preference Optimization (TPO) consists of four main components: (1) a vision encoder, (2) a connector, (3) a large language model, and (4) a series of visual task heads. Differently colored flame symbols indicate which components are unfrozen at various stages of the training process.

🔼 표 3은 grounded question answering(GQA) 작업에 대한 실험 결과를 보여줍니다. 다양한 모델들의 정확도(Acc), IoU(Intersection over Union), IoP(Intersection over Prediction) 지표를 비교하여 TPO(Task Preference Optimization) 기법의 효과를 보여줍니다. 특히, Acc@IoP와 Acc@GQA 점수는 모델이 비디오 내용을 효과적으로 이해하고 복잡한 추론 작업을 처리하는 능력을 보여줍니다. 이 표는 TPO가 비디오 이해 및 추론 능력을 향상시켜, 복잡한 질문에도 정확하고 시의적절한 답변을 생성할 수 있음을 시사합니다.
read the caption
Table 3: Performance on Grounded QA.

🔼 표 4는 제시된 TPO 방법이 이미지 이해 과제에서 얼마나 성능 향상을 가져왔는지 보여줍니다. 다양한 벤치마크(MMIU, SEED-Bench2)에서 기존 VideoChat2 모델 대비 성능 향상 수치를 보여주는 표입니다. 구체적으로는 각 벤치마크별 평균 점수와 개별 과제별 점수 향상률을 제시하여 TPO의 효과를 정량적으로 평가합니다. 특히, LLaVA-Interleave, InternVL1.5-Chat 등 다른 최첨단 모델들과의 비교를 통해 TPO의 경쟁력을 보여줍니다.
read the caption
Table 4: Performance on Image Understanding.

🔼 표 5는 제로샷 방식으로 수행된 순간 검색(Moment Retrieval) 작업의 성능을 보여줍니다. 이 표는 다양한 모델의 성능을 비교하여 제로샷 순간 검색 작업에서 각 모델의 정확도를 보여줍니다. 특히, 회색으로 표시된 부분은 LLM(대규모 언어 모델)을 사용하지 않은 모델을 나타냅니다. 이는 LLM의 사용 유무에 따른 성능 차이를 비교 분석하는 데 도움이 됩니다.
read the caption
Table 5: Zero-Shot Performance on Moment Retrieval.Gray means no LLM.

🔼 표 6은 순수 비전 모델(LLM 없음)과 LLM 기반 모델을 포함한 다양한 모델의 영상 장면 검색 및 하이라이트 감지 성능을 보여줍니다. 정확도와 IoU(Intersection over Union) 점수를 비교하여 각 모델의 성능을 평가하고, 제로샷(zero-shot)과 미세 조정(fine-tuned) 설정에서의 성능 차이를 분석합니다. 회색으로 표시된 부분은 LLM을 사용하지 않은 순수 비전 모델임을 나타냅니다.
read the caption
Table 6: Fine-tuning Performance on Moment Retrieval and Highlight Detection. Gray means no LLM.
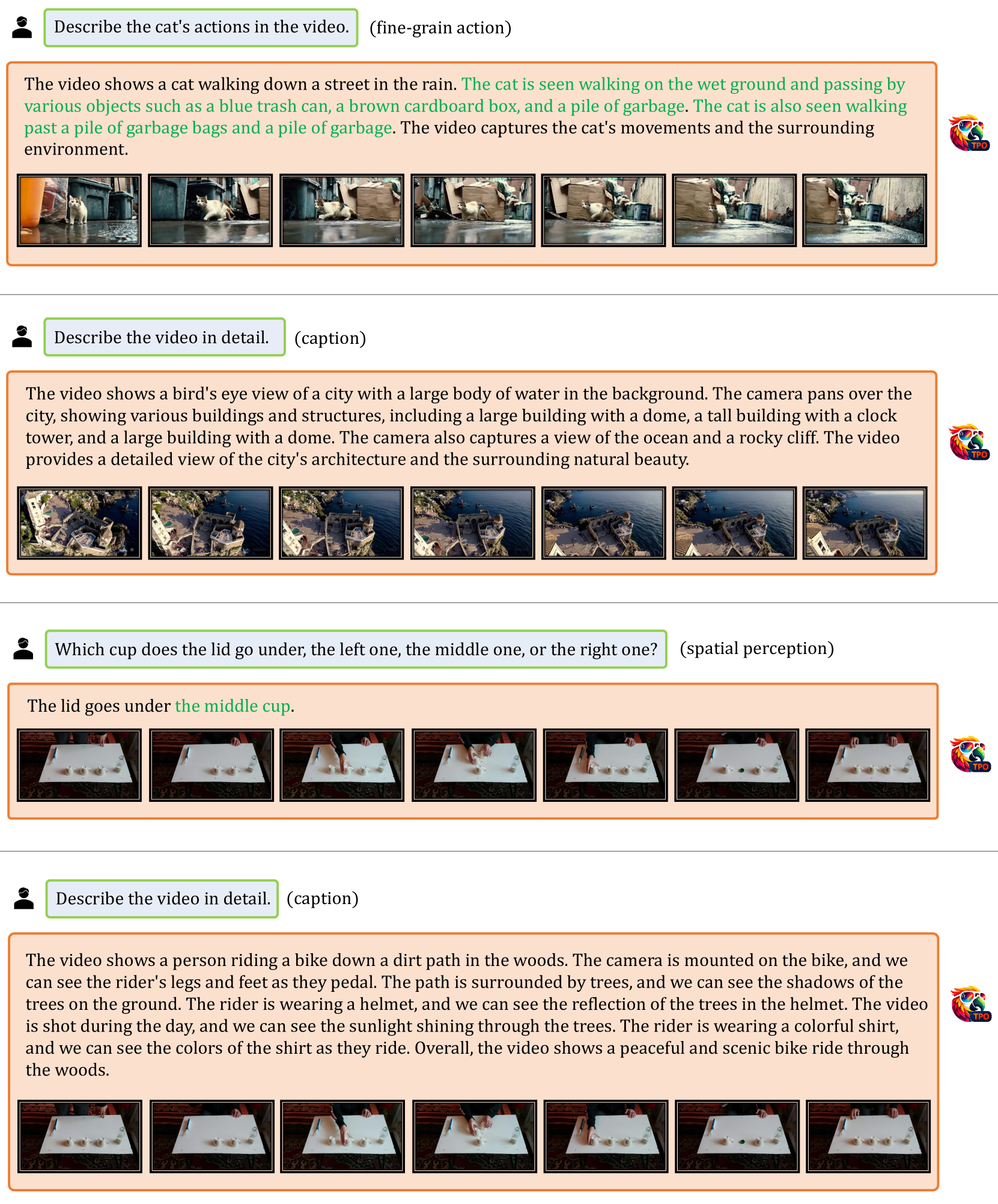
🔼 표 7은 공간적 지시(Spatial Grounding) 작업에 대한 결과를 보여줍니다. 이 작업은 사용자의 텍스트 설명을 기반으로 이미지 내에서 특정 객체의 위치를 찾는 것을 목표로 합니다. VideoChat-TPO는 간단한 태스크 헤드만을 사용하여 픽셀-투-임베딩 방식보다 성능이 우수함을 보여줍니다. 이는 VideoChat-TPO가 픽셀 단위의 정확한 위치 정보를 효과적으로 처리할 수 있음을 시사합니다. 세부적으로는, VideoChat-TPO가 RefCOCO 데이터셋에서 기존의 최첨단 모델들과 비교하여 우수한 성능을 달성했다는 점을 강조하고 있습니다. 특히, 픽셀-투-시퀀스 방식의 모델과 비교하여 경쟁력 있는 결과를 제시합니다.
read the caption
Table 7: Spatial Grounding Task. ★★\bigstar★ with a refined decoder.
More on tables
| Model | LLM Params | Frames | MVBench [48] | VideoMME [22] Overall | VideoMME [22] Short | VideoMME [22] Medium | VideoMME [22] Long | MLVU [117] M-AVG |
|---|---|---|---|---|---|---|---|---|
| AVG | w/o s. | w/ s. | w/o s. | w/ s. | w/o s. | w/ s. | w/o s. | |
| TimeChat [72] | 7B | 96 | 38.5 | 34.3 | 36.9 | 39.1 | 43.1 | 31.8 |
| Video-LLAVA [49] | 7B | 8 | 43.0 | 41.1 | 41.9 | 46.9 | 47.3 | 38.7 |
| ShareGPT4Video [11] | 7B | 16 | 51.2 | 39.9 | 43.6 | 48.3 | 53.6 | 36.3 |
| LLaVA-Next-Video [115] | 7B | 16 | 44.0 | 38.0 | 40.8 | 44.6 | 47.4 | 37.7 |
| ST-LLM [52] | 7B | 64 | 54.9 | 37.9 | 42.3 | 45.7 | 48.4 | 36.8 |
| PLLaVA-34B [97] | 34B | 16 | 58.1 | 40.0 | 35.0 | 47.2 | 36.2 | 38.2 |
| Chat-UniVi [33] | 7B | 64 | 40.8 | 40.6 | 45.9 | 45.7 | 51.2 | 41.3 |
| VideoChat2 (baseline) [48] | 7B | 16 | 60.4 | 39.5 | 43.8 | 48.3 | 52.8 | 37.0 |
| VideoChat-TPO | 7B | 16 | 66.8 (+6.4) | 48.8 (+9.3) | 53.8 (+10.0) | 58.8 | 64.9 | 46.7 |
🔼 표 2는 다양한 비디오 이해 벤치마크에서 제안된 TPO 방법을 사용한 VideoChat 모델의 성능을 보여줍니다. 비교 대상은 동일한 세대의 LLM 또는 16프레임 입력을 사용하는 다른 모델들입니다. ‘w/o s.‘는 자막 없이, ‘w/s.‘는 자막을 포함하여 평가한 결과를 나타냅니다. M-AVG는 MLVU(Multimodal Large-scale Video Understanding) 벤치마크의 평균 점수를 의미합니다. 표에는 MVBench, VideoMME, 그리고 MLVU 세 가지 벤치마크에 대한 성능이 제시되어 있으며, 각 벤치마크 내에서도 비디오 길이(짧음, 중간, 긴)에 따른 세분화된 결과를 확인할 수 있습니다. 이를 통해 TPO가 다양한 비디오 길이와 조건에서 강건하고 우수한 성능을 보임을 보여줍니다.
read the caption
Table 2: Performance on Multimodal Video Understanding. We compare our model to others using LLMs of the same generation or 16-frame input. w/o s. indicates without subtitle, while w s. indicates with subtitle. M-AVG refers to the mean average of MLVU.
| Model | Acc@IoP | Acc@GQA | mIoP | IoP@0.3 | IoP@0.5 | mIoU | IoU@0.3 | IoU@0.5 |
|---|---|---|---|---|---|---|---|---|
| VIOLETv2 [23] | 54.9 | 12.8 | 23.6 | 25.1 | 23.3 | 3.1 | 4.3 | 1.3 |
| SeViLA [105] | 72.5 | 16.6 | 29.5 | 34.7 | 22.9 | 21.7 | 29.2 | 13.8 |
| LangRepo [34] | 59.6 | 17.1 | 31.3 | - | 28.7 | 18.5 | - | 12.2 |
| FrozenBiLM NG+ [100] | 73.8 | 17.5 | 24.2 | 28.5 | 23.7 | 9.6 | 13.5 | 6.1 |
| VideoStreaming [65] | 57.4 | 17.8 | 32.2 | - | 31.0 | 19.3 | - | 13.3 |
| LLoVi [110] | 65.9 | 24.3 | 37.3 | - | 36.9 | 20.0 | - | 15.3 |
| HawkEye [90] | - | - | - | - | - | 25.7 | 37.0 | 19.5 |
| VideoChat-TPO | 77.7 | 25.5 | 35.6 | 47.5 | 32.8 | 27.7 | 41.2 | 23.4 |
🔼 표 11은 TPO(Task Preference Optimization) 모델의 성능에 대한 ablation study 결과를 보여줍니다. 특히 추론 데이터(reasoning data)와 각각의 task head (temporal, region, mask head) 가 모델 성능에 미치는 영향을 분석합니다. 각 열은 특정 구성 요소의 유무에 따른 다양한 지표(예: R@0.3, R@0.5, R@0.7, mIoU, AVG)를 나타내며, 각 행은 다른 실험 조건(추론 데이터 유무, 특정 task head 제거 등)을 의미합니다. 이 표를 통해 연구자들은 TPO 모델의 주요 구성 요소들이 성능에 얼마나 기여하는지, 그리고 각 구성 요소의 상호 작용을 정량적으로 분석할 수 있습니다.
read the caption
Table 11: Ablation of Reasoning Data and Head Performance.
| Model | MM IU [60] | SEED2I [41] | SEED2M [41] |
|---|---|---|---|
| LLaVA-v1.5 [51] | 19.2 | 58.3 | 39.2 |
| ShareGPT4V [10] | 18.5 | - | - |
| OpenFlamingo [2] | 22.3 | 36.6 | 43.5 |
| LLaVA-Interleave [43] | 32.4 | - | - |
| VideoChat2 [48] | 35.0 | 26.5 | 27.6 |
| VideoChatGPT [57] | - | 38.3 | 49.8 |
| InternLM-XComposer [19] | 21.9 | 65.4 | 49.8 |
| VideoChat-TPO | 40.2 (+5.2) | 67.3 (+40.8) | 70.0 (+42.4) |
🔼 표 12는 TPO 구성 요소와 데이터의 영향을 보여줍니다. T, R, M, C는 각각 시간적 헤드, 영역 헤드, 마스크 헤드, 대화 데이터를 나타냅니다. R1@0.5는 Charades-STA 데이터셋에서 R1@0.5를, Acc@0.5는 모든 COCO 데이터셋에서 Acc@0.5의 평균을, 𝒥&ℱ는 Ref-YouTube-VOS 데이터셋에서 𝒥&ℱ를 나타냅니다. 이 표는 다양한 시각적 과제에 대한 TPO 구성 요소의 기여도를 정량적으로 분석하여 TPO의 성능 향상에 대한 통찰력을 제공합니다.
read the caption
Table 12: Impact of TPO Components and Data. T, R, M, and C denote temporal head, region head, mask head, and conversation data respectively. R1@0.5 means R1@0.5 in Charades-STA, Acc@0.5 represents the mean of Acc@0.5 in all COCO datasets, 𝒥𝒥\mathcal{J}caligraphic_J&ℱℱ\mathcal{F}caligraphic_F means 𝒥𝒥\mathcal{J}caligraphic_J&ℱℱ\mathcal{F}caligraphic_F in Ref-YouTube-VOS.
| Model | Charades-STA [24] | ||||
|---|---|---|---|---|---|
| R@0.3 | R@0.5 | R@0.7 | mIoU | ||
| — | — | — | — | — | — |
| UniVTG [50] | 44.1 | 25.2 | 10.0 | 27.1 | |
| VideoChat2 [48] | 38.0 | 14.3 | 3.8 | 24.6 | |
| VTimeLLM [29] | 51.0 | 27.5 | 11.4 | 31.2 | |
| TimeChat [72] | - | 32.2 | 13.4 | - | |
| HawkEye [90] | 50.6 | 31.4 | 14.5 | 33.7 | |
| ChatVTG [66] | 52.7 | 33.0 | 15.9 | 34.9 | |
| VideoChat-TPO | 58.3 | 40.2 | 18.4 | 38.1 |
🔼 표 13은 MVBench 멀티초이스 질문응답 과제에 대한 VideoChat-TPO 모델의 성능을 보여줍니다. MVBench는 다양한 시각적 지각 능력(예: 시간적 추론, 공간적 추론, 시공간적 추론 등)을 평가하는 비디오 이해 벤치마크입니다. 이 표는 여러 모델(VideoChat2, TimeChat, Video-LLaVA, ShareGPT4Video, ST-LLM, Chat-UniVi, PLlava-34B 등)과 비교하여 VideoChat-TPO의 전반적인 성능과 하위 과제별 성능을 보여줍니다. 또한 자막 유무에 따른 성능 차이도 확인할 수 있습니다. 각 모델의 성능은 정확도(%)로 나타내며, VideoChat-TPO는 여러 모델 중 가장 높은 성능을 보입니다.
read the caption
Table 13: Results on MVBench Multi-choice Question Answering.
| Model | Charades-STA [24] | QVHighlight [39] | |||||
|---|---|---|---|---|---|---|---|
| R@0.3 | R@0.5 | R@0.7 | mIoU | mAP | HIT@1 | ||
| — | — | — | — | — | — | — | — |
| M-DETR [39] | 65.8 | 52.1 | 30.6 | 45.5 | 35.7 | 55.6 | |
| QD-DETR [62] | - | 57.3 | 32.6 | - | 38.9 | 62.4 | |
| UniVTG [50] | 72.6 | 60.2 | 38.6 | 52.2 | 40.5 | 66.3 | |
| TimeChat [72] | - | 46.7 | 23.7 | - | 21.7 | 37.9 | |
| HawkEye [90] | 72.5 | 58.3 | 28.8 | - | - | - | |
| VideoChat-TPO | 77.0 | 65.0 | 40.7 | 55.0 | 38.8 | 66.2 |
🔼 표 14는 논문의 실험 결과 중 다중 이미지 이해(MMIU) [60]에 대한 정량적 결과를 보여줍니다. MMIU는 다양한 다중 이미지 관계를 포함하는 광범위한 벤치마크로, 총 52개의 작업과 77,000개의 이미지, 그리고 11,000개의 엄선된 객관식 질문으로 구성됩니다. 표는 다양한 모델들의 정확도(Accuracy)를 측정한 결과를 보여주며, ‘Overall’ 점수는 모든 작업에 대한 종합적인 성능을 나타냅니다. 이 표를 통해 TPO(Task Preference Optimization) 기법을 적용한 모델이 기준 모델에 비해 얼마나 향상된 성능을 보이는지, 그리고 다양한 시각적 작업에 대한 모델의 세부적인 성능을 비교 분석할 수 있습니다.
read the caption
Table 14: Quantitative results of MMIU [60]. Accuracy is the metric, and the Overall score is computed across all tasks.
| Methods | RefCOCO [103] | |||
|---|---|---|---|---|
| val | testA | testB | ||
| MAttNet ★ [104] | 76.4 | 80.4 | 69.3 | |
| OFA-L [82] | 80.0 | 83.7 | 76.4 | |
| G-DINO-L ★ [53] | 90.6 | 93.2 | 88.2 | |
| VisionLLM-H [84] | - | 86.7 | - | |
| Shikra-7B [8] | 87.0 | 90.6 | 80.2 | |
| NExT-Chat-7B [109] | 85.5 | 90.0 | 77.9 | |
| VideoChat-TPO | 85.9 | 90.8 | 81.3 |
🔼 표 15는 TPO(Task Preference Optimization) 모델의 성능에 대한 ablation study 결과를 보여줍니다. 다양한 시각적 과제 데이터셋을 사용하여 실험을 진행했으며, 각 데이터셋을 사용했을 때의 성능 변화를 보여주는 표입니다. 구체적으로는, 어떤 시각적 과제 데이터를 사용했을 때 TPO 모델의 성능이 어떻게 변하는지, 그리고 각 과제 데이터셋의 크기가 모델 성능에 어떤 영향을 미치는지 등을 분석한 결과를 보여줍니다. 이를 통해 TPO 모델의 성능에 가장 크게 영향을 미치는 요소와 모델의 일반화 능력 향상에 필요한 데이터셋 구성에 대한 통찰력을 제공합니다.
read the caption
Table 15: Ablation task datasets.
| Model | LaSOT [21] | GOT-10k [30] | ||||
|---|---|---|---|---|---|---|
| Success | Pnorm | P | Overlap | SR0.5 | SR0.75 | |
| — | — | — | — | — | — | — |
| SiamFC [5] | 33.6 | 42.0 | 33.9 | 34.8 | 35.3 | 9.8 |
| ATOM [16] | 51.5 | - | - | 55.6 | 63.4 | 40.2 |
| SiamRPN++ [40] | 49.6 | 56.9 | 49.1 | 51.8 | 61.8 | 32.5 |
| SiamFC++ [98] | 54.4 | 62.3 | 54.7 | 59.5 | 69.5 | 47.9 |
| LLaVA-1.5 [51] | 19.4 | 16.5 | 12.8 | 23.5 | 20.2 | 9.7 |
| Merlin [102] | 39.8 | 40.2 | 38.1 | 51.4 | 55.9 | 42.8 |
| VideoChat-TPO | 69.4 | 80.1 | 76.9 | 70.6 | 79.8 | 66.0 |
🔼 표 16은 논문에서 제시된 VideoChat-TPO 모델의 학습 설정을 보여줍니다. 각 열은 Vision Encoder 학습률, Connector 학습률, Temporal Head 학습률, Region Head 학습률, Mask Head 학습률, Mask Adapter 학습률, 각 태스크 토큰의 학습률, LLM LoRA 학습률, 최적화 알고리즘, 가중치 감쇠, 입력 해상도, 입력 프레임 수, LLM LoRA Rank, LLM LoRA Alpha, 웜업 비율, 배치 크기, 에폭 수, 그리고 수치적 정밀도 등의 하이퍼파라미터를 나타냅니다. 각 설정 값은 학습의 세 단계 (Stage 1, Stage 2, Stage 3, Stage 3 w/o Con.) 에 따라 다르게 설정되어 있으며, Frozen 열은 특정 단계에서 고정된(학습하지 않는) 파라미터를 나타냅니다. Con.은 대화 데이터를 의미하고, LR은 학습률을 의미합니다. 이 표는 VideoChat-TPO 모델의 학습 과정을 이해하는 데 중요한 정보를 제공합니다.
read the caption
Table 16: Training Settings of VideoChat-TPO. Con. means conversation data and LR means learning rate.
| Method | Ref-YouTube-VOS [74] | MeViS [18] | ||||
|---|---|---|---|---|---|---|
| J | F | J | F | |||
| — | — | — | — | — | — | — |
| ReferFormer [93] | 62.9 | 61.3 | 64.6 | 31.0 | 29.8 | 32.2 |
| OnlineRefer [92] | 62.9 | 61.0 | 64.7 | - | - | - |
| LISA [38] | 52.6 | 52.1 | 53.0 | - | - | - |
| VideoLISA [4] | 63.7 | 61.7 | 63.7 | 44.4 | 41.3 | 47.6 |
| VideoChat-TPO | 63.9 | 52.3 | 75.4 | 47.0 | 42.6 | 51.3 |
🔼 표 17은 TPO(Task Preference Optimization) 방법론의 훈련에 사용된 데이터셋을 보여줍니다. 각 단계별로 사용된 데이터의 종류와 개수를 상세하게 기술합니다. 특히, Temporal Grounding 작업에는 moment retrieval과 highlight detection 두 가지 하위 작업이 포함되어 있음을 명시합니다. 세부적으로는 각 단계(Stage 1, 2, 3)별로 Temporal Grounding, Spatial Grounding, Segmentation 작업에 사용된 데이터셋의 이름과 각 데이터셋에 포함된 샘플 수를 보여줍니다. 추가적으로, Temporal Reasoning과 대화 데이터 (Conversation) 에 사용된 데이터셋과 샘플 수도 포함되어 있습니다. 이 표는 TPO 모델 훈련의 구성 요소를 이해하는 데 중요한 정보를 제공합니다.
read the caption
Table 17: Training Datasets. The temporal grounding includes two subtasks: moment retrieval and highlight detection.
Full paper#



















