↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
현존하는 비디오 생성 모델들은 주로 단일 프롬프트에 초점을 맞추고 있으며, 다중 프롬프트를 사용한 장시간 비디오 생성은 여전히 어려운 과제입니다. 기존 연구들은 엄격한 학습 데이터 요구사항, 약한 프롬프트 따르기, 비자연스러운 전환 등의 문제점을 가지고 있습니다.
본 논문에서는 이러한 문제점들을 해결하기 위해 튜닝이 필요 없는 다중 프롬프트 비디오 생성 기법인 DiTCtrl을 제시합니다. DiTCtrl은 MM-DiT 아키텍처의 어텐션 메커니즘을 분석하여 마스크 기반 어텐션 제어 및 잠재적 혼합 전략을 사용하여 다중 프롬프트에 대한 매끄러운 전환을 가능하게 합니다. MPVBench라는 새로운 벤치마크를 통해 다중 프롬프트 비디오 생성 모델의 성능을 평가하며, 실험 결과 DiTCtrl이 최첨단 성능을 달성함을 보여줍니다.
Key Takeaways#
Why does it matter?#
본 논문은 튜닝 없이 다중 프롬프트를 사용한 장시간 비디오 생성이라는 어려운 문제에 대한 새로운 접근 방식을 제시합니다. 이는 MM-DiT 아키텍처의 장점을 활용하면서도 새로운 KV 공유 메커니즘과 잠재적 혼합 전략을 통해 매끄러운 전환을 달성하는 방법을 보여줍니다. 새로운 벤치마크인 MPVBench도 제시하여, 이 분야의 미래 연구를 위한 토대를 마련합니다. 따라서 비디오 생성 및 편집 분야 연구자들에게 중요한 의미를 지닙니다.
Visual Insights#
🔼 본 그림은 제안된 DiTCtrl 모델이 다중 텍스트 프롬프트를 입력받아 복잡한 움직임과 부드러운 전환 효과를 가진 긴 비디오를 생성하는 뛰어난 성능을 보여주는 예시입니다. 특히, 운동선수가 세 가지 다른 장면을 활주하는 어려운 예시를 보여줍니다. 복잡한 피사체의 움직임과 극적인 카메라 움직임에도 불구하고, DiTCtrl은 시퀀스 전체에서 놀라운 안정성과 프롬프트 설명을 충실히 따르는 매끄러운 의미적 전환을 유지합니다. 이는 DiTCtrl의 강력한 다중 프롬프트 비디오 생성 능력을 보여줍니다.
read the caption
Figure 1: The proposed DiTCtrl takes multiple text prompts as input and demonstrates superior capability in generating longer videos with complex motion and smooth transitions as output. In this figure, we showcase a challenging example where an athlete glides through three distinct scenes. Despite the complex subject motion and dramatic camera movement, our method maintains remarkable stability throughout the sequence and seamless semantic transitions that faithfully follow the prompt descriptions.
| Method | CSCV | Motion smoothness | Text-Image similarity |
|---|---|---|---|
| Gen-L-Video | 59.44% | 83.36% | 30.58% |
| FreeNoise | 84.37% | 97.22% | 32.69% |
| FreeNoise+DiT | 78.74% | 97.76% | 30.90% |
| Video-Infinity | 74.97% | 97.31% | 32.35% |
| DiTCtrl(w/o kv-sharing) | 81.79% | 97.35% | 31.37% |
| DiTCtrl(Ours) | 84.90% | 97.80% | 30.68% |
🔼 표 1은 MPVBench를 사용하여 벤치마킹된 다양한 비디오 생성 방법에 대한 성능 지표를 비교한 것입니다. 각 비디오 생성 방법(Gen-L-Video, FreeNoise, FreeNoise+DiT, Video-Infinity, DiTCtrl)에 대해 세 가지 주요 지표인 CSCV(Clip Similarity Coefficient of Variation, 클립 유사성 계수의 변동 계수), Motion smoothness(움직임 부드러움), Text-Image similarity(텍스트-이미지 유사성)가 측정됩니다. CSCV는 여러 프롬프트 간의 전환의 부드러움을 평가하는 지표이며, Motion smoothness는 비디오 내 객체의 움직임 자연스러움을 측정하고, Text-Image similarity는 생성된 비디오와 입력 텍스트 프롬프트 간의 의미적 일관성을 평가합니다. 각 열의 굵은 값은 해당 그룹 내에서 최고 성능을 나타냅니다.
read the caption
Table 1: Evaluation metrics. Comparison of performance metrics for various video generation methods as benchmarked by MPVBench. Bold values represent the best performance within each group.
In-depth insights#
MM-DiT Attention#
본 논문에서 제시된 MM-DiT(Multi-Modal Diffusion Transformer) 어텐션 메커니즘은 텍스트와 비디오 정보를 통합하여 처리하는 핵심 구성 요소입니다. 기존의 UNet 기반 비디오 생성 모델들과는 달리, 3D 풀 어텐션을 사용하여 텍스트와 비디오 피처 간의 복잡한 상호작용을 포착합니다. 이를 통해 텍스트 정보를 효과적으로 비디오 생성에 반영하고, 시간적 일관성을 유지하며, 세밀한 시맨틱 제어가 가능해집니다. 특히, 텍스트-비디오, 비디오-텍스트 어텐션은 텍스트 토큰과 비디오 프레임 간의 정확한 의미 연결을 가능하게 하며, 텍스트-텍스트, 비디오-비디오 어텐션은 각각 텍스트와 비디오 내의 일관성 유지를 담당합니다. 이러한 어텐션 메커니즘의 특성 분석을 통해, 마스크 기반 어텐션 제어 및 KV-공유 전략과 같은 혁신적인 기법들이 가능해졌으며, 이는 다중 프롬프트 비디오 생성에서 높은 성능을 달성하는데 기여합니다. 시간적 일관성 유지 및 부드러운 전환을 위한 핵심 요소로서, MM-DiT 어텐션 메커니즘은 멀티 모달 정보 처리의 효율성을 높이고, 고품질 비디오 생성을 위한 새로운 가능성을 제시합니다. 더 나아가, 본 논문은 MM-DiT 어텐션의 작동 방식을 심층적으로 분석하여, 기존 UNet 구조와의 유사성 및 차이점을 명확히 밝힘으로써, 향후 멀티 모달 비디오 생성 모델 연구에 대한 중요한 발판을 마련했습니다.
DiTCtrl: KV-Sharing#
DiTCtrl의 KV-공유 메커니즘은 다중 프롬프트 비디오 생성에서 일관성 있는 객체 표현을 유지하는 핵심입니다. 기존의 단일 프롬프트 모델의 한계를 극복하고자, DiTCtrl은 이전 프롬프트의 키(Key)와 밸류(Value) 정보를 현재 프롬프트의 어텐션 메커니즘에 공유함으로써, 시맨틱 일관성을 유지합니다. 이는 시간에 따른 매끄러운 전이를 가능하게 하여, 각 프롬프트가 독립적으로 생성된 영상이 아니라, 하나의 연속적인 비디오 시퀀스로 인식되도록 합니다. 마스크 기반 어텐션 제어와 결합하여, 특정 객체에 대한 어텐션을 정확하게 조절하고 배경과의 혼동을 방지합니다. 이러한 접근 방식은 추가적인 학습 없이 다중 프롬프트에 대한 응답으로 일관되고 자연스러운 비디오를 생성하는 능력을 제공하며, DiTCtrl의 핵심적인 기술적 강점으로 볼 수 있습니다. 효율성과 효과성을 동시에 달성하는 이러한 메커니즘은 향후 다중 프롬프트 비디오 생성 모델 개발에 중요한 영향을 줄 것으로 예상됩니다.
Multi-Prompt Video#
멀티 프롬프트 비디오는 단일 비디오 내에서 여러 프롬프트를 통합하여 보다 역동적이고 다층적인 스토리텔링을 가능하게 하는 새로운 비디오 생성 패러다임을 제시합니다. 기존의 단일 프롬프트 방식은 제한된 표현력으로 현실 세계의 복잡성을 제대로 반영하지 못하는 반면, 멀티 프롬프트 방식은 시간적 연속성과 일관성 있는 시각적 전환을 유지하면서 여러 장면과 행동을 자연스럽게 연결할 수 있습니다. 새로운 어텐션 제어 기법과 잠재적 블렌딩 전략을 통해 각 프롬프트 간의 매끄러운 전환을 보장하고, 일관된 객체 움직임과 시각적 일관성을 유지하는 것이 중요합니다. 이러한 기술은 긴 비디오 생성, 비디오 편집, 특수 효과 등의 분야에 혁신적인 가능성을 열어줄 것입니다. 하지만, 모델의 계산 복잡도 증가와 프롬프트 간의 의미적 모호성 해결 등의 과제를 해결하기 위한 추가적인 연구가 필요합니다. 효율적인 어텐션 메커니즘과 견고한 프롬프트 해석 기법의 개발은 멀티 프롬프트 비디오 기술의 발전에 필수적입니다.
MPVBench: Evaluation#
논문에서 제시된 MPVBench 평가는 다중 프롬프트 비디오 생성 모델의 성능을 종합적으로 평가하기 위한 벤치마크임을 보여줍니다. 기존의 단일 프롬프트 평가 방식과 달리, 다양한 전이 유형과 특수 지표를 포함하여 시간에 따른 일관성 및 매끄러운 전환을 평가할 수 있습니다. 새로운 지표인 CSCV(Clip Similarity Coefficient of Variation)는 클립 간의 유사성 변화의 정도를 측정하여 비디오의 매끄러운 전이를 정량적으로 평가합니다. 또한, MPVBench는 다양한 전이 유형(배경, 주제, 카메라, 스타일, 조명, 위치, 속도, 감정, 의상, 액션 등)을 포함하는 포괄적인 데이터셋을 제공하며, 이를 통해 모델의 다양한 어려움에 대한 일반화 능력을 평가할 수 있습니다. 인간 평가와 결합된 이러한 정량적, 정성적 평가는 다중 프롬프트 비디오 생성 모델의 전반적인 성능에 대한 포괄적인 이해를 제공합니다. 새로운 벤치마크의 도입은 향후 연구 방향을 제시하며, 다중 프롬프트 비디오 생성 분야의 발전에 크게 기여할 것으로 예상됩니다.
Future Work#
본 논문의 “향후 연구 방향"에 대한 심층적인 고찰은 다중 프롬프트 비디오 생성 모델의 개념적 한계점 극복을 위한 구체적인 방안 모색에 초점을 맞춰야 합니다. 계산 비용 감소 및 효율성 증대를 위한 효과적인 아키텍처 개선 연구가 필수적이며, 더욱 정교한 의미론적 이해 및 제어를 가능하게 하는 세부적인 메커니즘 연구 또한 중요합니다. 다양한 프롬프트 유형 및 전이 방식에 대한 포괄적인 벤치마크 개발은 모델 성능 평가의 객관성을 확보하고, 향후 연구의 방향성 제시에 큰 도움이 될 것입니다. 나아가, 실시간 비디오 생성 및 편집 기술 개발은 실용적인 측면에서 중요한 의미를 지닙니다. 모델의 일반화 능력 향상 및 다양한 도메인 적용 연구 또한 미래 연구의 주요 과제입니다. 마지막으로, 윤리적 및 사회적 함의에 대한 심도있는 논의를 바탕으로 책임감 있는 기술 개발 방향을 설정해야 할 것입니다.
More visual insights#
More on figures

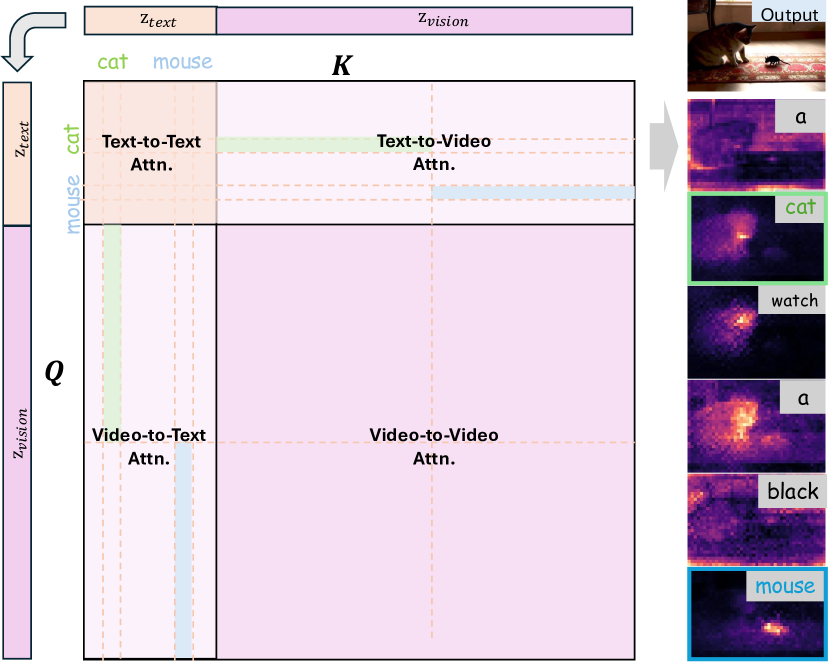
🔼 그림 2는 MM-DiT(Multi-Modal Diffusion Transformer)의 어텐션 메커니즘 분석 결과를 보여줍니다. MM-DiT는 텍스트와 이미지(또는 비디오)를 통합된 시퀀스로 매핑하여 어텐션 계산을 수행하는 모델입니다. 이 그림에서는 ‘고양이가 검은 생쥐를 본다’라는 프롬프트를 사용하여 어텐션 매트릭스를 분석합니다. 분석 결과, 어텐션 매트릭스는 크게 네 가지 영역(텍스트-텍스트 어텐션, 비디오-비디오 어텐션, 텍스트-비디오 어텐션, 비디오-텍스트 어텐션)으로 나눌 수 있음을 보여줍니다. 특히, 각 텍스트 토큰은 텍스트-비디오 및 비디오-텍스트 어텐션의 평균을 사용하여 강조 표시된 응답을 보여주는 것을 확인할 수 있습니다. 이는 MM-DiT의 어텐션 메커니즘이 텍스트와 비디오 간의 의미적 연관성을 효과적으로 포착하고, 세밀한 수준의 의미적 제어를 가능하게 함을 시사합니다. 즉, 모델이 프롬프트에 제시된 텍스트와 시각적 정보를 정확하게 연결하고 이해하여, 프롬프트에 충실한 비디오를 생성하는 데 기여한다는 것을 보여줍니다.
read the caption
Figure 2: MM-DiT Attention Analysis. We find the attention matrix in MM-DiT attention can be divided into four different regions. As for the prompt of “ a cat watch a black mouse”, each text token shows a high-light response using the average of the text-to-video and video-to-text attention.

🔼 그림 3은 MM-DiT의 Text-to-Text 어텐션과 Video-to-Video 어텐션을 시각화한 것입니다. 기존의 UNet 구조 기반의 모델들과 달리 MM-DiT는 텍스트와 비디오를 통합된 시퀀스로 매핑하여 어텐션 메커니즘을 적용합니다. 이 그림은 MM-DiT의 어텐션 매트릭스를 분석하여 각 영역(Text-to-Text, Video-to-Video, Text-to-Video, Video-to-Text)의 어텐션 패턴을 시각화하고 있습니다. 각 어텐션 영역의 시각화를 통해 텍스트 토큰과 비디오 프레임 간의 세밀한 관계를 보여주고, 특히 토큰 수준의 의미적 위치 파악 및 정확한 의미 제어에 대한 MM-DiT의 강점을 보여줍니다. 이는 멀티-프롬프트 비디오 생성 작업에서 일관성 있고 고품질의 비디오를 생성하는 데 중요한 역할을 합니다. 즉, 이전 UNet 구조보다 MM-DiT가 개별 어텐션을 구성하는 데 더 강력한 잠재력을 가지고 있음을 보여주는 시각적 증거를 제공합니다.
read the caption
Figure 3: MM-DiT Text-to-Text and Video-to-Video Attention Visualization. We find that the current MM-DiT has a stronger potential to construct the individual attention in the previous UNet-like structure [10, 11, 41].

🔼 그림 4는 제안된 DiTCtrl의 파이프라인을 보여줍니다. 이 방법은 여러 프롬프트를 기반으로 콘텐츠 일관성과 동작 일관성이 있는 비디오를 합성하려고 시도합니다. 첫 번째 비디오는 소스 텍스트 프롬프트 Pi-1을 사용하여 합성됩니다. 비디오 합성을 위한 잡음 제거 과정에서 전체 어텐션을 마스크 기반 KV 공유 전략으로 변환하여 소스 비디오 Vi-1에서 비디오 콘텐츠를 쿼리하여 수정된 대상 프롬프트 Pi에서 콘텐츠 일관성이 있는 비디오를 합성합니다. 초기 레이턴트는 5프레임으로 간주됩니다. 처음 3프레임은 Pi-1의 콘텐츠를 생성하는 데 사용되고, 마지막 3프레임은 Pi의 콘텐츠를 생성하는 데 사용됩니다. 분홍색 레이턴트는 겹치는 프레임을 나타내고, 파란색과 녹색 레이턴트는 서로 다른 프롬프트 세그먼트를 구분하는 데 사용됩니다.
read the caption
Figure 4: Pipeline of the proposed DiTCtrl. Our method tries to synthesize content-consistent and motion-consistent videos based on multi-prompts. The first video is synthesized with source text prompt Pi−1subscript𝑃𝑖1P_{i-1}italic_P start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT. During the denoising process for video synthesis, we convert the full-attention into masked-guided KV-sharing strategy to query video contents from source video 𝒱i−1subscript𝒱𝑖1\mathcal{V}_{i-1}caligraphic_V start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT, so that we can synthesize content-consistent video under the modified target prompt Pisubscript𝑃𝑖P_{i}italic_P start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. Note that initial latents are assumed to be 5 frames. The first three frames are used to generate the contents of Pi−1subscript𝑃𝑖1P_{i-1}italic_P start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT, and the last three frames are used to generate contents of Pisubscript𝑃𝑖P_{i}italic_P start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. The pink latent represents the overlapping frame, while the blue and green latents are used to distinguish different prompt segments.

🔼 그림 5는 다중 프롬프트 비디오 생성에서 연속적인 비디오 클립 간의 매끄러운 전환을 위한 잠재적 혼합 전략을 보여줍니다. 여러 개의 프롬프트를 사용하여 생성된 비디오는 각 프롬프트가 다른 의미론적 부분을 나타내는 여러 세그먼트로 나뉩니다. 각 세그먼트는 개별적으로 생성되고, 이어지는 세그먼트와 중첩되는 부분을 갖습니다. 이 중첩 영역에서, 위치에 따른 가중치 함수가 적용되어 인접한 세그먼트 간의 매끄러운 전환을 보장합니다. 중첩 영역에 더 가까운 프레임은 해당 세그먼트의 가중치가 더 높고, 경계에 있는 프레임은 가중치가 낮아져 자연스러운 전환을 만듭니다. 이 방법은 추가적인 훈련 없이도 의미론적 일관성과 시간적 응집력을 유지하는 매끄러운 비디오 전환을 생성합니다.
read the caption
Figure 5: Latent blending strategy for video transition between video clips.

🔼 그림 6은 제안된 DiTCtrl 방법과 기준 모델들(Kling, FreeNoise+DiT)을 사용하여 생성된 비디오의 결과를 보여줍니다. Kling은 상용 모델이고, FreeNoise+DiT는 CogVideoX에 FreeNoise를 구현한 것입니다. 다양한 프롬프트에 대한 각 모델의 비디오 생성 품질을 시각적으로 비교하여 DiTCtrl의 성능 우수성을 보여줍니다. 그림은 각 프롬프트에 대한 여러 프레임의 이미지들을 나열하여 비교합니다. 자세히 살펴보면, DiTCtrl은 특히 동작의 자연스러움과 일관성, 장면 간의 부드러운 전환 면에서 다른 모델들보다 뛰어난 성능을 보입니다.
read the caption
Figure 6: Generation results on given prompts by our method and baseline models. Kling is the commercial model, and Freenoise+DiT is our implementation of Freenoise on CogVideoX.

🔼 그림 7은 CLIP 임베딩의 t-SNE 시각화를 보여줍니다. 각 점은 차원 축소 후 단일 비디오 프레임의 CLIP 임베딩을 나타냅니다. 이 시각화는 기존의 다중 프롬프트 비디오가 별개의 클러스터를 형성하는 반면, 제안된 방법은 보다 연속적인 분포를 생성하여 보다 매끄러운 의미적 전환을 나타냄을 보여줍니다. 즉, 기존 방법으로 생성된 다중 프롬프트 비디오는 서로 다른 영역에 분포되어 있지만, 본 논문에서 제안하는 방법으로 생성된 비디오는 서로 밀접하게 연결된 하나의 영역에 분포되어 매끄러운 전환을 나타냅니다.
read the caption
Figure 7: T-SNE visualization of CLIP embeddings. Each point represents the CLIP embedding of a single video frame after dimensionality reduction. The visualization demonstrates that conventional multi-prompt videos form distinct clusters, while our method produces a more continuous distribution, indicating smoother semantic transitions.

🔼 그림 8은 DiTCtrl의 구성 요소별 실험 결과를 보여줍니다. 첫 번째 줄과 두 번째 줄은 각각 98프레임으로 구성되어 있으며, 나머지 방법들은 105프레임으로 구성되어 있습니다. 이 그림은 다양한 구성 요소(마스크 가이드, KV 공유, 레이턴트 블렌딩)를 제거했을 때의 결과를 비교하여 DiTCtrl의 각 구성 요소가 모델 성능에 미치는 영향을 보여줍니다. 특히, 마스크 가이드와 KV 공유 메커니즘이 영상의 일관성과 매끄러운 전환에 중요한 역할을 한다는 것을 시각적으로 보여줍니다.
read the caption
Figure 8: Ablation Component in DiTCtrl. The first and second rows have 98 frames, while the remaining methods generate 105 frames.

🔼 그림 9는 본 논문에서 제안하는 방법을 사용하여 단일 프롬프트로 생성된 긴 비디오의 예시를 보여줍니다. 이 그림은 다양한 시간대에 걸쳐 일관된 시각적 요소와 매끄러운 전환을 유지하면서, 긴 비디오 생성의 가능성을 보여줍니다. 특히, 동적인 움직임과 복잡한 시각적 세부 사항을 정확하게 재현하는 모델의 능력을 강조합니다.
read the caption
Figure 9: single prompt longer video generation example.

🔼 그림 10은 DiTCtrl의 핵심 메커니즘인 마스크 기반 KV 공유의 세부적인 과정을 보여줍니다. 다중 프롬프트 비디오 생성 작업에서 시간에 따른 일관성 있는 비디오 생성을 위해, 이전 프롬프트(Pi-1)와 현재 프롬프트(Pi)의 어텐션 맵을 활용하여 마스크를 생성하고, 이를 이용해 KV 공유 어텐션 연산을 수행합니다. 구체적으로는 텍스트-비디오 및 비디오-텍스트 어텐션 영역에서 특정 토큰(예: ‘달리는 말’)에 해당하는 값들을 추출, 평균화하여 의미론적 마스크 맵(Mi-1, Mi)을 생성하고, 이를 통해 전경에 초점을 맞춘 어텐션 결과(Ffore, Fback)를 얻습니다. 최종 결과는 이 마스크들을 이용해 Ffore와 Fback을 융합하여 생성됩니다. 이러한 마스크 기반 접근 방식은 의미론적 일관성을 유지하면서 프롬프트 간의 부드러운 전환을 가능하게 합니다.
read the caption
Figure 10: Mask-guided KV-sharing details.

🔼 그림 11은 논문에서 제시된 다중 프롬프트 결과의 추가적인 예시를 보여줍니다. 세 개의 서로 다른 시나리오 (피는 장미, 자전거를 타는 소년, 숲 속의 풍경) 가 다중 프롬프트를 사용하여 생성되었으며, 각 시나리오는 여러 단계의 프롬프트를 통해 시각적 세부 사항과 전환이 점진적으로 변화하는 것을 보여줍니다. 이 그림은 제안된 DiTCtrl 방법의 다중 프롬프트 비디오 생성 능력과 시각적 일관성 및 매끄러운 전환을 유지하는 능력을 보여줍니다.
read the caption
Figure 11: More multi-prompt results

🔼 그림 12는 논문에서 제시된 다중 프롬프트 비디오 생성 결과의 추가적인 예시들을 보여줍니다. 각각의 이미지 시퀀스는 여러 개의 프롬프트를 순차적으로 입력하여 생성한 비디오의 일부분을 보여주는 것으로, 다양한 시나리오에서 다중 프롬프트 기반 비디오 생성 모델의 성능을 시각적으로 보여주는 역할을 합니다. 각 시퀀스는 매끄러운 전환과 일관된 객체 움직임을 유지하면서, 서로 다른 의미를 지닌 여러 프롬프트를 성공적으로 결합하여 생성된 결과임을 보여줍니다. 다양한 배경, 객체, 움직임 등이 포함된 시각자료는, 제안된 방법론의 효과적인 다중 프롬프트 처리 능력과 시각적 일관성 유지를 보여주는 데 중점을 둡니다.
read the caption
Figure 12: More multi-prompt results

🔼 그림 13은 다양한 멀티 프롬프트 비디오 생성 방법과 기존 상용 솔루션 및 최첨단 모델들과의 비교 결과를 보여줍니다. 특히, 움직임과 배경 전환이라는 두 가지 측면에 초점을 맞추어 비교 분석합니다. 움직임 전환의 경우, 말을 타고 달리는 기사의 동작이 자연스럽게 변화하는 과정을 보여주는 반면, 다른 방법들은 움직임이 부자연스럽거나 일관성이 부족한 모습을 보입니다. 배경 전환의 경우, 눈 덮인 도시 거리에서 햇볕이 내리쬐는 도시 거리로 변화하는 과정을 보여줍니다. DiTCtrl은 매끄럽고 자연스러운 전환을 보여주는 반면, 다른 방법들은 배경 전환이 부자연스럽거나 갑작스러운 경우를 보여줍니다. 이를 통해 DiTCtrl이 멀티 프롬프트 비디오 생성에서 뛰어난 성능을 보임을 시각적으로 보여줍니다.
read the caption
Figure 13: Motion and background transition.

🔼 그림 14는 배경 전환을 보여줍니다. 다양한 방법들 (Kling, Gen-L-Video, Video-Infinity, FreeNoise, FreeNoise+DiT 그리고 제안된 방법)을 사용하여 생성된 비디오의 일부 프레임을 보여주는 여러 행으로 구성되어 있습니다. 각 행은 동일한 멀티 프롬프트(여기서는 ‘눈 내리는 도시 거리’, ‘화창한 도시 거리’)에 대한 결과를 보여주며, 각 방법의 배경 전환 능력을 비교 분석하기 위한 것입니다. 제안된 방법(DiTCtrl)은 배경이 매끄럽게 전환되는 것을 보여주는 반면, 다른 방법들은 자연스럽지 못한 전환이나 불일치를 보여줍니다.
read the caption
Figure 14: Background transition.

🔼 그림 15는 단일 프롬프트를 사용한 장시간 비디오 생성의 시각화를 보여줍니다. 이 그림은 다양한 환경에서 장시간 비디오 생성 능력을 보여주는 여러 개의 비디오 클립을 보여줍니다. 각 클립은 프롬프트에 따라 일관성 있게 생성되었으며, 매끄러운 시각적 전환과 사실적인 움직임을 보여줍니다. 이는 모델이 단일 프롬프트로도 다양한 시각적 요소와 장면을 정확하고 일관되게 생성할 수 있음을 시사합니다.
read the caption
Figure 15: Visualization of single prompt longer video generation.

🔼 그림 16은 비디오 편집에서 어텐션 가중치 재조정(Reweighting) 기법의 예시를 보여줍니다. (a)에서는 ‘분홍색(pink)’ 토큰에 해당하는 어텐션 값을 줄여서 분홍색 요소의 시각적 강도를 약화시키는 것을 보여줍니다. 반대로 (b)에서는 ‘눈(snowy)’ 토큰의 어텐션 값을 높여 눈에 덮인 장면의 시각적 강도를 강화시키는 것을 보여줍니다. 이를 통해, MM-DiT의 Text-to-Video 및 Video-to-Text 어텐션이 시맨틱 제어에 어떻게 활용될 수 있는지를 보여줍니다.
read the caption
Figure 16: Reweighting example of Video Editing.

🔼 그림 17은 비디오 편집의 워드 스왑 예시를 보여줍니다. 짧은 설명으로는 부족하기 때문에 보다 자세히 설명하겠습니다. 이 그림은 제안된 DiTCtrl 방법을 사용하여 비디오 콘텐츠를 변경하는 방법을 보여주는 여러 비디오 클립을 포함하고 있습니다. 각 클립은 동일한 기본 시나리오를 따르지만, ‘큰 곰’, ‘큰 사자’ 와 같이 특정 단어를 바꿔서 비디오에 서술적 변화를 주었습니다. 이를 통해 DiTCtrl이 단어 변경을 통해 비디오 내용에 세밀한 변화를 줄 수 있음을 시각적으로 보여줍니다. 이는 단순히 문장의 길이를 늘리는 것이 아니라, 주요 단어의 변화가 비디오 내용에 미치는 영향을 효과적으로 보여주는 예시입니다.
read the caption
Figure 17: Word Swap example of Video Editing.

🔼 그림 18은 마스크 기반 KV 공유 결과에 대한 절제 연구를 보여줍니다. 첫 번째 줄은 마스크 기반 KV 공유 없이 모델을 보여주고, 두 번째 줄은 마스크 기반 KV 공유를 사용한 전체 모델을 보여줍니다. (a)의 프롬프트는 ‘강력한 말이 들판을 가로질러 질주한다…‘에서 ‘눈에 띄는 얼룩말이 무리를 이끌고 들판을 가로질러 간다…‘로 전환됩니다. (b)의 프롬프트는 ‘흰색 SUV가 흙길을 달린다…‘에서 ‘흰색 SUV가 눈길을 헤쳐 나간다…‘로 전환됩니다.
read the caption
Figure 18: Ablation study of mask-guided KV-sharing results. First row shows our model without mask-guided KV-sharing, while the second row demonstrates our full model with mask-guided KV-sharing. The prompt for (a) transitions from “A powerful horse gallops across a field…” to “A striking zebra leads its herd across the field…”. The prompt for (b) evolves from “A white SUV drives a dirt road…” to “A white SUV powers through snow…”
More on tables
| Method | Overall preference | Motion Consistency | Temporal Alignment | Text Pattern |
|---|---|---|---|---|
| Gen-L-Video | 1.15 | 1.14 | 1.08 | 1.25 |
| FreeNoise | 3.02 | 2.90 | 2.99 | 3.08 |
| FreeNoise+DiT | 3.81 | 3.93 | 3.75 | 3.78 |
| Video-Infinity | 2.90 | 2.85 | 2.91 | 2.98 |
| DiTCtrl(Ours) | 4.11 | 4.17 | 4.26 | 3.91 |
🔼 표 2는 사용자 연구 결과를 보여줍니다. 다양한 비디오 생성 방법에 대한 여러 측면(전반적인 선호도, 동작 패턴, 시간적 일관성, 텍스트 정렬)에 대한 사용자 평가 점수를 1점에서 5점까지(5점이 가장 높음)의 척도로 나타낸 표입니다. 각 지표에 대한 최고 점수는 굵게 표시되어 있습니다. 이 표는 제시된 비디오 생성 방법들의 장단점을 비교 분석하여, 제시된 여러 측면에서 각 방법의 성능을 정량적으로 보여주는 데 사용됩니다.
read the caption
Table 2: User study. Human evaluation of different video generation methods across multiple aspects. Scores range from 1 to 5, with higher scores indicating better performance. Bold values represent the best performance within each metric.
| Hyperparameters | |
|---|---|
| base model | CogVideoX-2B |
| sampler | VPSDEDPMPP2MSampler |
| sample step | 50 |
| guidance scale | 6 |
| resolution | 480 × 720 |
| sampling num frames | 13 |
| overlap size | 6 |
| kv-sharing steps | [2,25] |
| kv-sharing layers | [25,30] |
| threshold | 0.3 |
| λ of CSCV | 10 |
🔼 이 표는 논문의 DiTCtrl 구현에 사용된 하이퍼파라미터들을 보여줍니다. 모델 기반, 샘플러, 샘플링 단계, 안내 스케일, 해상도, 샘플링 프레임 수, 겹치는 영역 크기, KV 공유 단계, KV 공유 계층, 임계값, CSCV의 알파 값 등 DiTCtrl의 다양한 설정 값들이 상세히 나열되어 있습니다. 이 정보는 DiTCtrl 모델의 재현성과 성능 분석에 중요한 역할을 합니다.
read the caption
Table 3: Hyperparameters of DiTCtrl.
| Method | CSCV | Motion smoothness | Text-Image similarity |
|---|---|---|---|
| Isolated | 72.37% | 97.78% | 32.05% |
| DiTCtrl(w/o kv-sharing) | 81.79% | 97.35% | 31.37% |
| DiTCtrl(w/o mask-guided) | 84.92% | 97.76% | 30.66% |
| DiTCtrl(full) | 84.90% | 97.80% | 30.68% |
🔼 표 4는 DiTCtrl 모델의 주요 구성 요소(잠재 혼합 전략, KV 공유 메커니즘, 마스크 기반 생성)를 제거했을 때의 성능을 비교 분석한 결과를 보여줍니다. 각 구성 요소별로 CSCV(Clip Similarity Coefficient of Variation), 동작 부드러움, 텍스트-이미지 유사도 세 가지 지표를 사용하여 정량적으로 평가하였습니다. 이를 통해 각 구성 요소가 DiTCtrl 모델의 전반적인 성능에 미치는 영향을 명확히 파악할 수 있습니다.
read the caption
Table 4: Comparison of metrics for ablation.
Full paper#


















