↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
최근 거대 언어 모델(LLM)의 효과적인 사전 훈련은 방대한 자원과 복잡한 기술적 과정 때문에 어려움을 겪고 있습니다. 기존의 LLM들은 성능은 우수하지만, 막대한 자원이 필요하여 학계 연구자들이 재현하기 어려운 한계가 있었습니다. 본 논문은 이러한 문제를 해결하기 위해 YuLan-Mini라는 새로운 LLM을 제시합니다.
YuLan-Mini는 24억 개의 매개변수를 가지고 있으며, 비슷한 규모의 다른 모델들에 비해 최고 수준의 성능을 달성했습니다. 이는 개선된 데이터 파이프라인, 강건한 최적화 방법, 그리고 효과적인 어닐링 기법을 통해 가능했습니다. 본 연구는 각 훈련 단계의 데이터 구성에 대한 자세한 정보를 공개하여, 다른 연구자들이 결과를 재현하고 향후 연구를 진행하는 데 도움을 줄 것으로 기대됩니다.
Key Takeaways#
Why does it matter?#
본 논문은 데이터 효율적인 거대 언어 모델(LLM)의 개발에 대한 중요한 통찰력을 제공합니다. 제한된 자원으로 경쟁력 있는 LLM을 개발하는 과제를 해결하며, 특히 학계 연구실에서의 재현 가능성을 높이는 데 기여합니다. 데이터 파이프라인, 최적화 방법, 어닐링 기법 등 세부적인 기술적 세부 사항을 공개하여 다른 연구자들이 유사한 모델을 개발하고 개선하는 데 도움을 줍니다. 또한, 합성 데이터 활용 및 모델 안정성 확보 전략은 향후 LLM 연구의 새로운 방향을 제시할 수 있습니다.
Visual Insights#

🔼 그림 1은 YuLan-Mini 모델의 성능을 비슷한 크기의 다른 기반 모델들과 비교한 그래프입니다. 비교에 사용된 8가지 벤치마크는 GSM8K, MATH-500, HumanEval, MBPP, MMLU, ARC-Challenge, HellaSwag, CEval 입니다. 모델 크기(N)와 데이터셋 크기(D)를 사용하여 Kaplan 등(2020)이 제안한 C=6ND 공식으로 부동소수점 연산(FLOPs)을 추정했습니다. 30억 파라미터가 넘는 모델들은 회색으로 표시되어 있습니다. 즉, YuLan-Mini 모델의 성능을 파라미터 수가 비슷한 다른 모델들과 비교하여, YuLan-Mini의 데이터 효율성을 보여주는 그림입니다.
read the caption
Figure 1: Performance comparison of YuLan-Mini against other base models, based on the average scores across eight benchmarks: GSM8K, MATH-500, HumanEval, MBPP, MMLU, ARC-Challenge, HellaSwag, and CEval. Floating Point Operations (FLOPs) are estimated using the scaling law formula C=6ND𝐶6𝑁𝐷C=6NDitalic_C = 6 italic_N italic_D proposed by Kaplan et al. (2020), where N𝑁Nitalic_N is the model size and D𝐷Ditalic_D is the size of the dataset. The models with a size larger than 3B are plotted in gray.
| Model | nlayers | dmodel | rffn | nheads | nkv_heads |
|---|---|---|---|---|---|
| LLaMA-3.2-3B | 28 | 3,072 | 2.7 | 24 | 8 |
| Phi-3-mini-4k-instruct | 32 | 3,072 | 2.7 | 32 | 32 |
| MiniCPM-2B | 40 | 2,304 | 2.5 | 36 | 36 |
| MiniCPM3-4B | 62 | 2,560 | 2.5 | 40 | 40 |
| Qwen2.5-1.5B | 28 | 1,536 | 5.8 | 12 | 2 |
| MobileLLM-1B | 54 | 1,280 | 2.8 | 20 | 5 |
| YuLan-Mini | 56 | 1,920 | 2.5 | 30 | 6 |
🔼 표 1은 다양한 언어 모델의 초매개변수 설정을 보여줍니다.
rffnsubscript𝑟ffnr_{ffn}은 피드포워드 네트워크의 히든 사이즈와 모델의 히든 사이즈의 비율을 나타냅니다. 이 표는 모델의 레이어 수, 임베딩 차원, 피드포워드 네트워크의 히든 사이즈, 헤드 수, KV 헤드 수 등의 하이퍼파라미터를 보여줍니다. 표 8에 나머지 기호에 대한 정의가 있습니다. 각 모델의 초매개변수 설정을 비교하여 모델 아키텍처의 차이를 이해하는 데 도움이 됩니다.read the caption
Table 1: Hyperparameter settings of diffrent models. rffnsubscript𝑟ffnr_{\text{ffn}}italic_r start_POSTSUBSCRIPT ffn end_POSTSUBSCRIPT is the ratio of the feed-forward network’s hidden size to the model’s hidden size. The definition of the symbols is available at Table 8
In-depth insights#
Data-Efficient LLMs#
데이터 효율적인 거대 언어 모델(LLM)은 제한된 컴퓨팅 자원과 데이터로 최고 성능을 달성하는 것을 목표로 합니다. 이는 대규모 데이터셋 구축 및 막대한 연산 비용이 필요한 기존 LLM의 한계를 극복하기 위한 중요한 연구 방향입니다. 데이터 증강, 효율적인 학습 알고리즘, 그리고 모델 구조 최적화와 같은 다양한 기술이 데이터 효율적인 LLM 개발에 활용됩니다. 특히, 적은 양의 데이터로도 우수한 성능을 보이는 모델을 개발하는 것은 자원 제약이 있는 연구 환경에서 매우 중요하며, 모델의 일반화 능력 향상에도 기여합니다. 합성 데이터 생성 및 전이 학습은 데이터 효율성을 높이는 대표적인 방법이며, 앞으로도 데이터 효율성과 성능 사이의 균형을 맞추는 연구가 지속될 것으로 예상됩니다. 모델 경량화 및 지식 증류를 통해 모델 크기를 줄여 데이터 효율성을 높이는 것 또한 중요한 연구 과제입니다.
Training Stability#
본 논문에서 다룬 ‘훈련 안정성’ 파트는 대규모 언어 모델(LLM) 학습 중 발생하는 불안정성 문제를 해결하기 위한 심층적인 연구를 보여줍니다. 학습 과정의 불안정성은 손실(loss)의 급격한 변동이나 그래디언트 폭발/소멸과 같은 현상으로 나타나며, 모델의 성능 저하 및 학습 실패로 이어질 수 있습니다. 논문은 이러한 불안정성을 야기하는 요인들을 은닉 상태의 변동성, 잔차 연결(residual connection), 레이어 정규화(layer normalization), 그리고 어텐션 점수 폭발 등으로 분석하고, µP(Maximal Update Parametrization)와 WeSaR(re-parametrization) 등의 기법을 통해 안정성을 향상시키는 방법들을 제시합니다. 특히, 데이터 파이프라인 설계 및 최적화, 강건한 최적화 알고리즘 활용, 그리고 어닐링(annealing) 기법을 통한 표적 데이터 선택 및 장문 컨텍스트 학습이 중요하게 언급되어 있으며, 이를 통해 제한된 자원으로도 경쟁력 있는 LLM을 개발할 수 있음을 시사합니다. 최적화 파라미터 및 초기화 방식의 중요성 또한 강조되고, 다양한 안정성 향상 기법들의 실험적 비교분석 결과를 통해, 제안된 방법들의 효과를 검증합니다.
Annealing Strategies#
본 논문에서 제시된 어닐링 전략은 학습률 감소 및 긴 문맥 처리 능력 향상이라는 두 가지 주요 전략을 중심으로 이루어집니다. 학습률 어닐링은 안정적인 학습을 유지하면서 모델 성능을 높이기 위해 1-sqrt 함수를 사용하여 학습 후반부에 학습률을 점진적으로 감소시키는 방법입니다. 문맥 창 확장은 RoPE(Rotary Positional Embedding)의 기저 주파수를 증가시켜 모델이 더 긴 문맥을 처리할 수 있도록 하는 전략입니다. 이를 통해 모델은 긴 문장이나 장문의 텍스트를 더 잘 이해하고 처리할 수 있게 됩니다. 고품질 데이터 선택 또한 어닐링 단계에서 중요한 요소입니다. 합성 추론 데이터를 포함하여 고품질 데이터를 사용함으로써 모델의 성능 향상에 기여합니다. 전반적으로, 제시된 어닐링 전략은 데이터 효율성을 높이고 모델 성능을 향상시키는 데 효과적임을 보여줍니다. 특히, 긴 문맥 처리 능력의 향상은 모델의 활용성을 크게 높이는 중요한 부분입니다.
Synthetic Data Gen#
본 논문에서 다룬 ‘Synthetic Data Gen’ 부분은 데이터 부족 문제 해결을 위한 합성 데이터 생성에 초점을 맞춘 것으로 보입니다. 대규모 언어 모델(LLM) 학습에 필요한 방대한 양의 데이터를 확보하는 데 어려움이 있으므로, 실제 데이터와 유사한 특징을 지닌 합성 데이터를 생성하여 LLM의 성능 향상을 도모하는 전략으로 해석됩니다. 이를 통해 데이터 수집 및 전처리에 드는 비용과 시간을 절감할 수 있으며, 특정 영역이나 희귀 사례에 대한 데이터를 효율적으로 확보하는 데 유용할 것으로 예상됩니다. 합성 데이터 생성 방법론의 자세한 내용은 논문에 제시되었을 것이며, 이 방법론의 효과성과 한계에 대한 심도있는 분석이 필요합니다. 합성 데이터의 질이 실제 데이터와 얼마나 유사한지, 모델의 일반화 성능에 미치는 영향은 어느 정도인지 등을 고려하여 종합적인 평가가 이루어져야 할 것입니다. 또한, 합성 데이터 생성 과정의 투명성과 재현성을 확보하는 것도 중요한 고려 사항일 것입니다.
Future Work#
본 논문에서는 YuLan-Mini라는 데이터 효율적인 언어 모델을 제시하고, 향후 연구 방향으로 지시(instruction) 버전의 YuLan-Mini 출시를 계획하고 있음을 밝혔습니다. 이는 사용자의 명령을 보다 효과적으로 처리하는 모델 개발을 의미하며, 사용자 친화적인 인터페이스 구현과 실제 응용 분야 확장을 위한 중요한 단계가 될 것입니다. 또한, 다양한 아키텍처와 훈련 방법 탐색을 통해 모델 성능을 더욱 향상시키고, 특정 전문 분야(수학, 코딩 등)에 특화된 모델 개발도 계획 중입니다. 이를 통해 YuLan-Mini의 활용성을 극대화하고, 특정 도메인에서 높은 전문성을 요구하는 작업에 적용 가능성을 높일 수 있을 것으로 예상됩니다. 모델의 능력을 심층적으로 연구하여 지속적인 개선을 도모하며, 대규모 언어 모델의 핵심 기술에 대한 이해를 높이는 데 기여할 것으로 기대됩니다. 데이터 효율적인 학습 방법론과 관련된 추가적인 연구 또한 중요한 과제로 언급되었습니다. 개방형 모델의 경쟁력 강화에 초점을 맞추고, 학계 및 산업계에 유용한 자원을 제공하는 목표를 가지고 있습니다.
More visual insights#
More on figures
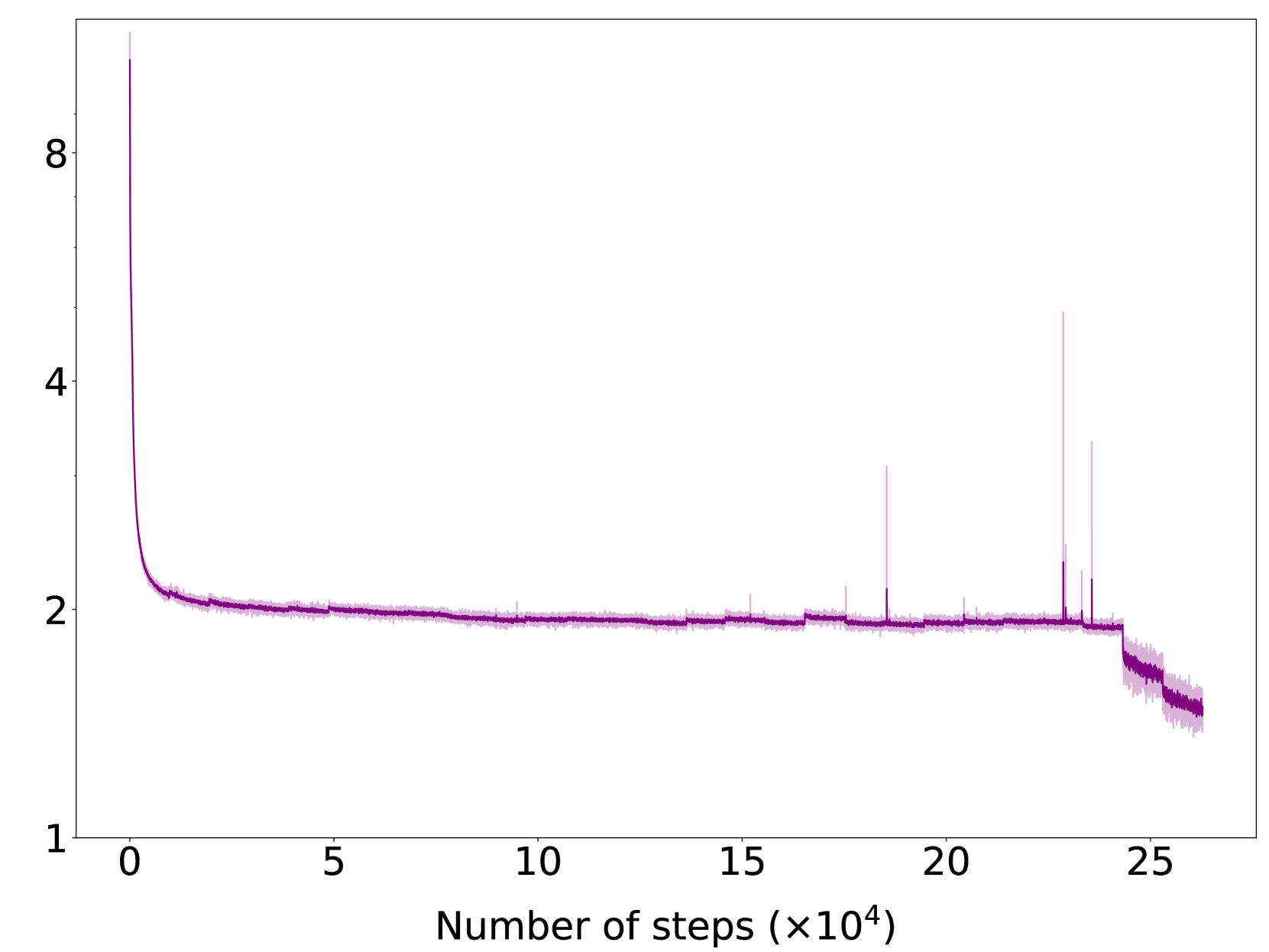
🔼 그림 2(a)는 YuLan-Mini 언어 모델의 사전 훈련 과정 중 훈련 손실(training loss)의 변화를 보여줍니다. x축은 훈련 단계(Number of steps)를 나타내고 y축은 훈련 손실 값을 나타냅니다. 이 그래프는 모델의 학습 진행 상황을 시각적으로 보여주며, 훈련 손실이 감소하는 추세를 확인할 수 있습니다. 훈련 손실의 감소는 모델이 데이터를 잘 학습하고 있다는 것을 의미하며, 모델 성능 향상에 대한 긍정적인 지표입니다. 그래프의 형태는 모델의 학습 안정성과 효율성을 평가하는 데에도 사용될 수 있습니다. 예를 들어, 훈련 손실이 안정적으로 감소하는 것은 모델의 안정적인 학습을 의미하고, 불규칙적인 변동은 학습의 불안정성을 시사할 수 있습니다.
read the caption
(a) Training loss.

🔼 그림 2(b)는 모델의 사전 훈련 과정 동안의 그래디언트 놈(Gradient Norm) 변화를 보여줍니다. 그래디언트 놈은 모델의 손실 함수가 얼마나 빠르게 변하는지를 나타내는 지표로, 그래디언트 놈이 너무 크면 모델의 훈련이 불안정해질 수 있습니다. 이 그림은 훈련 과정에서 그래디언트 놈이 어떻게 변화하는지를 시각적으로 보여주어 모델의 훈련 안정성을 평가하는 데 도움이 됩니다.
read the caption
(b) Gradient norm.

🔼 그림 2는 YuLan-Mini 언어 모델의 사전 훈련 과정에서 손실(loss)과 기울기(gradient)의 변화를 보여줍니다. (a)는 훈련 손실의 추이를, (b)는 기울기의 크기를 나타냅니다. 이 그래프를 통해 훈련의 안정성을 평가하고, 과정에서 발생할 수 있는 문제점(예: 손실 급증 또는 발산)을 감지하는 데 도움이 됩니다. 안정적인 훈련의 경우 손실은 점진적으로 감소하고, 기울기의 크기는 적절한 범위 내에서 유지되어야 합니다.
read the caption
Figure 2: Training loss and gradients during pre-training process.

🔼 그림 3(a)는 트랜스포머 모델 학습 중 발생하는 잠재적인 불안정성을 보여줍니다. 여러 레이어의 히든 상태 분산이 학습 과정에서 기하급수적으로 증가하는 것을 보여줍니다. 이는 손실과 그래디언트 놈의 급격한 증가로 이어질 수 있으며, 학습의 불안정성을 야기하고 모델의 성능 저하로 이어집니다. 히든 상태의 분산이 폭발적으로 증가하는 현상은 모델의 안정적인 학습을 방해하는 중요한 요인임을 시사합니다.
read the caption
(a) Exploding hidden states.

🔼 그림 3(b)는 훈련 과정에서 은닉 상태의 변화를 보여줍니다. 특히, 발산하지 않고 안정적으로 수렴하는 은닉 상태의 경향을 보여줍니다. 이 그림은 훈련 안정성을 평가하는 지표로서 은닉 상태의 분산과 기울기 크기를 모니터링하는 것이 중요함을 시각적으로 보여줍니다. 다양한 레이어에서 은닉 상태의 분산이 증가하지 않고 일정 수준을 유지하는 것을 확인할 수 있으며, 이는 훈련의 안정성을 나타냅니다. 또한, 기울기 크기도 안정적인 범위 내에 머무는 것을 확인할 수 있습니다.
read the caption
(b) Convergent hidden states.

🔼 그림 3(c)는 모델 학습 중 손실 예측 실패를 보여줍니다. 즉, 모델이 학습 과정에서 예상치 못한 손실 변동을 보이며, 안정적인 학습 패턴을 유지하지 못하는 상황을 시각적으로 나타냅니다. 이는 모델의 내부 상태나 매개변수의 갑작스러운 변화로 인해 발생할 수 있으며, 학습의 불안정성을 초래하여 최종 성능 저하로 이어질 수 있습니다. 그림에서는 손실 값의 급격한 변화가 관찰되며, 이러한 변화가 학습 과정의 안정성에 부정적인 영향을 미치는 것을 보여줍니다.
read the caption
(c) Loss prediction failure.

🔼 그림 3은 발산하는 학습 과정과 수렴하는 학습 과정 간의 역동성을 비교한 것입니다. y축은 로그 스케일에서 은닉 상태의 분산과 기울기 규범의 값을 나타냅니다. 두 시도 모두 손실이 일관되지만, 은닉 상태 분산과 기울기 규범의 추세는 다릅니다. 즉, 손실이 비슷하더라도 은닉 상태의 분산과 기울기 규범이 발산하는 경우와 수렴하는 경우가 있음을 보여줍니다. 이는 모델의 학습 안정성에 은닉 상태의 변동성이 미치는 영향을 이해하는 데 중요한 시각을 제공합니다.
read the caption
Figure 3: Comparison of training dynamics between divergent and convergent trial. The y𝑦yitalic_y-axis denotes the value of the hidden states variance and gradient norm on a log-scale. Both trials have consistent loss, but different trends of hidden states variance and gradient norm.

🔼 본 그림은 각 레이어의 레이어 정규화(Layer Normalization, LN) 출력의 분산을 보여줍니다. 훈련 과정에서 각 레이어의 LN 출력값의 분산이 어떻게 변화하는지를 시각적으로 나타내어, 훈련 안정성 분석에 중요한 지표가 되는 LN 출력값의 분산 변화를 보여주는 그림입니다. 레이어가 깊어질수록 분산이 어떻게 변하는지 확인할 수 있습니다.
read the caption
Figure 4: Variance of LN output of each layers.

🔼 본 그림은 레이어 정규화(Layer Normalization, LN) 전에 어텐션 점수가 폭발적으로 증가하는 현상을 보여줍니다. LLM의 학습 안정성에 있어서 레이어 정규화의 중요성을 시각적으로 보여주는 실험 결과입니다. 그림은 학습 단계에 따른 어텐션 점수의 변화를 나타내며, 레이어 정규화 이전에 어텐션 점수가 급격히 증가하여 학습 불안정성을 유발할 수 있음을 시사합니다. 이는 잠재적으로 학습 과정에서 손실(loss)이 급격히 증가하거나 발산하는 현상으로 이어질 수 있습니다.
read the caption
Figure 5: Attention scores explodes before LN.

🔼 그림 6은 학습 안정성 향상 기법에 대한 추가 실험 결과를 보여줍니다. 48개의 A800 GPU 클러스터를 사용하여, 마지막 세 개의 체크포인트에 대한 LAMBADA 정확도 평균과 추정 실행 시간을 보고합니다. 발산하는 그래디언트 놈 또는 급증하는 손실 경로는 빨간색 막대로 표시되고, 수렴하는 학습은 녹색 막대로 표시됩니다. 이 그림은 다양한 안정성 향상 기법(QK LayerNorm 추가, QK LayerNorm 및 가중치 감쇠 제거, Cerebras µP (학습률 0.01), Depth µP, WeSaR)을 적용했을 때의 LAMBADA 정확도와 실행 시간 변화를 보여주어, 각 기법의 효과를 비교 분석하는 데 도움을 줍니다.
read the caption
Figure 6: Ablation experiments on training instability mitigation methods are conducted. We report the average of LAMBADA accuracy of the last three checkpoints of the training and the estimated running time on our 48 A800-GPU cluster. Divergent gradient norm or spiking loss trajectories are shown in red bars, and convergent training is shown in green.

🔼 그림 7a는 레이어 정규화(LN) 출력과 어텐션 값의 분산을 훈련 단계에 따라 보여줍니다. 이 그림은 특히 레이어 정규화 전에 어텐션 점수가 폭발하는 현상을 보여주는 그림 7b와 함께 제시되어 훈련 안정성에 대한 심층 분석을 지원합니다. 레이어 정규화 출력의 분산 변화 추이와 어텐션 점수의 평균값을 통해 모델 훈련 중 발생할 수 있는 불안정성 요인을 시각적으로 보여줍니다.
read the caption
(a) Variance of attention values and LN outputs

🔼 그림 7(b)는 YuLan-Mini 모델의 사전 훈련 과정에서 관찰된 기울기 놈(gradient norm)과 손실(loss)의 추이를 보여줍니다. 특히 QK LayerNorm 적용 전후의 변화를 비교하여 모델의 안정성에 미치는 영향을 시각적으로 보여주는 그래프입니다. x축은 훈련 단계(training steps)이고, y축은 기울기 놈과 손실 값을 나타냅니다. QK LayerNorm을 사용하지 않았을 때는 기울기 놈이 불안정하게 변동하고 손실이 급증하는 반면, QK LayerNorm을 사용했을 때는 기울기 놈이 안정적으로 유지되고 손실 또한 일정하게 감소하는 것을 확인할 수 있습니다. 이는 QK LayerNorm이 모델의 훈련 안정성을 향상시키는 데 효과적임을 시각적으로 보여주는 결과입니다.
read the caption
(b) Gradient norm and loss trajectory

🔼 그림 7은 훈련 과정 동안 어텐션 값과 LN(Layer Normalization) 출력 분산, 그리고 그래디언트 놈과 손실 함수 값의 변화를 보여줍니다. 왼쪽 그래프는 각 레이어의 어텐션 값과 LN 출력 분산의 변화를, 오른쪽 그래프는 그래디언트 놈과 손실 함수의 변화를 나타냅니다. QK LayerNorm을 적용하기 전에는 어텐션 로짓과 그래디언트가 폭발하는 현상이 나타났으나, QK LayerNorm을 적용한 후에는 어텐션 로짓과 그래디언트의 폭발 현상이 방지되었고, LN 출력 값은 1 부근에서 안정적으로 유지되었으며 손실 함수 값도 일관되게 감소하는 것을 확인할 수 있습니다. 이는 QK LayerNorm이 훈련 안정성을 향상시키는 데 효과적임을 보여줍니다.
read the caption
Figure 7: The curves of attention value and LN output variances (left) and gradient norm and loss (right). After using QK LayerNorm, we prevent the explosion of attention logits and gradients, keeping the LN output stable around 1 and the loss consistent.

🔼 그림 8은 논문의 데이터 파이프라인과 추론 데이터의 합성 과정을 보여줍니다. 데이터 필터링 파이프라인은 데이터 수집부터 시작하여 총 6단계로 구성됩니다. 합성 데이터 생성은 사전 학습 데이터(수평선 위)와 지시 데이터(수평선 아래)를 모두 포함합니다. 데이터 수집 후 중복 제거, 휴리스틱 필터링, 주제 기반 텍스트 재구성, 모델 기반 품질 평가, 오염 제거 단계를 거쳐 데이터 필터링이 진행됩니다. 추론 데이터의 합성 과정은 수학, 코딩, 과학 추론 데이터를 생성하는 것을 보여줍니다. 각 영역별 데이터 생성 과정은 해당 영역의 특징을 반영하여 설계되었습니다.
read the caption
Figure 8: Illustration of our data filtering pipeline and synthetic generation for reasoning data. The filtering pipeline consists of six steps starting from data collection. Synthetic data generation includes both pretraining data (above the horizontal line) and instruction data (below the line).
More on tables
| Tokenizer | Vocabulary Size | Web | Chinese | Math | Code |
|---|---|---|---|---|---|
| Gemma2-2B | 256,000 | 4.928 | 3.808 | 2.865 | 3.309 |
| Qwen2.5 | 151,936 | 4.935 | 3.956 | 2.890 | 3.881 |
| LLaMA-3.1 | 128,000 | 4.994 | 3.263 | 3.326 | 3.911 |
| MiniCPM-2.4B | 122,753 | 4.753 | 4.273 | 2.739 | 3.052 |
| Phi-3.5-mini | 100,352 | 4.311 | 1.914 | 2.654 | 3.110 |
| MiniCPM-1.2B | 73,440 | 4.631 | 4.042 | 2.696 | 3.017 |
| YuLan-Mini | 99,000 | 4.687 | 4.147 | 2.716 | 3.033 |
| YuLan-Mini + Dropout | 99,000 | 4.687 | 4.146 | 2.715 | 3.031 |
🔼 표 2는 다양한 토크나이저의 압축률을 보여줍니다. 압축률은 토크나이저가 입력 텍스트를 토큰으로 변환할 때 얼마나 효율적으로 공간을 절약하는지를 나타냅니다. 값이 클수록 더 효과적인 압축을 의미합니다. 이 표는 모델의 어휘 크기, 웹 데이터, 중국어 데이터, 수학 데이터 및 코드 데이터에 대한 각 토크나이저의 압축률을 비교하여 모델의 효율성과 성능에 대한 통찰력을 제공합니다.
read the caption
Table 2: Compression rate of different tokenizers. Higher values indicate more effective compression.
| Method | SI | MiniCPM | CerebrasGPT | YuLan-Mini |
|---|---|---|---|---|
| Scale Embedding Output | 1 | 12 | 10 | 10 |
| Scale MHA equation | $1/\sqrt{d_{head}}$ | $1/\sqrt{d_{head}}$ | $1/d_{head}$ | $1/\sqrt{d_{head}}$ |
| Scale Residual Connection | 1 | $\frac{1.4}{\sqrt{n_{layers}}}$ | 1 | $\frac{1.4}{\sqrt{n_{layers}}}$ |
| QKV Weights LR | $\eta_{base}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ |
| QKV $\sigma$ Init | $\sigma_{base}^{2}$ | $\sigma_{base}^{2}/m_{width}$ | $\sigma_{base}^{2}/m_{width}$ | $\sigma_{base}^{2}/m_{width}$ |
| O Weights LR | $\eta_{base}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ |
| O $\sigma$ Init | $\frac{\sigma_{base}^{2}}{2n_{layers}}$ | $\sigma_{base}^{2}/m_{width}$ | $\sigma_{base}^{2}/m_{width}$ | $\frac{\sigma_{base}^{2}}{2m_{width}\cdot n_{layers}}$ |
| FFN1 Weights LR | $\eta_{base}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ |
| FFN1 $\sigma$ Init | $\sigma_{base}^{2}$ | $\sigma_{base}^{2}/m_{width}$ | $\sigma_{base}^{2}/m_{width}$ | $\sigma_{base}^{2}/m_{width}$ |
| FFN2 Weights LR | $\eta_{base}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ | $\eta_{base}/m_{width}$ |
| FFN2 $\sigma$ Init | $\frac{\sigma_{base}^{2}}{2n_{layers}}$ | $\sigma_{base}^{2}/m_{width}$ | $\sigma_{base}^{2}/m_{width}$ | $\frac{\sigma_{base}^{2}}{2m_{width}\cdot n_{layers}}$ |
| Scale Output logits | 1 | $1/m_{width}$ | $1/m_{width}$ | 1 |
🔼 표 3은 다양한 크기의 언어 모델을 학습할 때 사용되는 초모수 설정을 비교하여 모델 학습 안정성에 대한 이해를 돕는 표입니다. Takase et al.(2023)의 SI 모델, Hu et al.(2024)의 MiniCPM 모델, Dey et al.(2023a)의 CerebrasGPT 모델을 비교 대상으로 포함하여 YuLan-Mini 모델의 초모수 설정을 보다 자세히 살펴봅니다. 각 모델의 임베딩 크기 조정, 잔차 연결, 그리고 다양한 가중치 행렬에 대한 학습률 및 초기화 방식에 대한 세부적인 설정을 비교하여 YuLan-Mini 모델의 학습 안정성을 위한 초모수 설정 전략을 설명합니다. 표에 사용된 변수에 대한 자세한 설명은 본 논문의 표 8에 나와 있습니다.
read the caption
Table 3: Comparison of the used hyperparameter settings for training stability, where the detailed explanation for the variables are in Table 8. We include SI (Takase et al., 2023) for comparison, MiniCPM (Hu et al., 2024), CerebrasGPT (Dey et al., 2023a). The definition of the symbols is available at Table 8 .
| Type | Source | Volume |
|---|---|---|
| Web Pages | FineWeb-Edu, DCLM, Chinese-FineWeb-Edu | 559.76B |
| Math (Pretrain) | AutoMathText, Proof-Pile-2, OpenWebMath Pro | 85.00B |
| Code (Pretrain) | the-stack-v2, StarCoder | 202.44B |
| General Knowledge | arXiv, StackExchange, English News | 121.87B |
| Books | CBook, Gutenberg, LoC-PD-Books | 52.13B |
| Encyclopedia | Wikipedia, Baidu-Baike | 14.80B |
| Open-Source Instruction | SlimOrca, OpenMathInstruct-1, JiuZhang3.0 | 11.64B |
| Synthetic Pretrain Data (Ours) | Synthetic document (seed: AutoMathText, LeetCode) | 8.76B |
| Synthetic Instruction (Ours) | Reasoning (seed: MetaMathQA, DeepMind Math, …) | 23.52B |
| Total | - | 1,080B |
🔼 본 표는 YuLan-Mini 사전 학습에 사용된 전체 데이터의 통계적 정보를 보여줍니다. 총 1.08조 토큰 규모이며, 웹 페이지, 수학, 코드, 일반 지식, 도서, 백과사전, 오픈소스 지시 데이터 등 다양한 출처의 데이터를 포함하고 있습니다. 어닐링 단계의 데이터는 표 5에 자세히 설명되어 있으며, 재현성을 위해 모든 기존 데이터셋은 부록 D에, 생성된 합성 데이터는 공개적으로 제공됩니다.
read the caption
Table 4: Statistical information of the entire pre-training corpus for YuLan-Mini. The data during the annealing process is detailed in Table 5. For model reproducibility, all curated datasets are placed in Appendix D, and the remaining synthetic data we generated is open-sourced.
| Domain | Type | Dataset | Volume |
|---|---|---|---|
| Mix | Pretrain | FineWeb-Edu, CBook, arXiv | 64.65B |
| Math | (1) CoT | Deepmind-Math, MathInstruct | 3.07B |
| (2) Long CoT | Numina, AMPS, Platypus | 0.61B | |
| (3) Formal math | Lean-GitHub, Lean-WorkBook, DeepSeek-Prover-V1 | 0.10B | |
| (4) Curated | Tulu v3, MathInstruct | 1.42B | |
| Code | (1) CoT | OSS-Instruct (seed: the-Stack-v2), OpenCoder-LLM | 6.66B |
| (2) Curated | LeetCode, XCoder-80K | 2.39B | |
| Science | (1) Long CoT | Camel-ai | 0.04B |
| (2) Curated | EvolKit-20k, Celestia, Supernova | 1.06B | |
| Total | - | - | 80B |
🔼 표 5는 YuLan-Mini 언어 모델의 어닐링 단계에서 사용된 학습 데이터에 대한 상세 정보를 보여줍니다. 데이터 유형, 도메인, 데이터셋, 그리고 각 데이터셋의 크기(볼륨)을 보여줍니다. 어닐링 단계는 모델 학습의 마지막 단계로, 고품질 데이터를 사용하여 모델 성능을 향상시키는 데 중점을 둡니다. 이 표는 어닐링 단계에서 사용된 다양한 데이터의 분포를 파악하는 데 도움이 됩니다.
read the caption
Table 5: Detailed information of the training data in the annealing stage.
| Models | Model | Size | # Train Tokens | Context Length | MATH | GSM | Human Eval | MBPP | RACE Middle | RACE High | RULER |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MiniCPM | 2.6B | 1.06T | 4K | 15.00 | 53.83 | 50.00* | 47.31 | 56.61 | 44.27 | N/A | |
| Qwen-2 | 1.5B | 7T | 128K | 22.60 | 46.90* | 34.80* | 46.90* | 55.77 | 43.69 | 60.16 | |
| Qwen2.5 | 0.5B | 18T | 128K | 23.60 | 41.60* | 30.50* | 39.30* | 52.36 | 40.31 | 49.23 | |
| Qwen2.5 | 1.5B | 18T | 128K | 45.40 | 68.50* | 37.20* | 60.20* | 58.77 | 44.33 | 68.26 | |
| Gemma2 | 2.6B | 2T | 8K | 18.30* | 30.30* | 19.50* | 42.10* | - | - | N/A | |
| StableLM2 | 1.7B | 2T | 4K | - | 20.62 | 8.50 | 17.50 | 56.33 | 45.06 | N/A | |
| SmolLM2 | 1.7B | 11T | 8K | 11.80 | - | 23.35 | 45.00 | 55.77 | 43.06 | N/A | |
| Llama3.2 | 3.2B | 9T | 128K | 7.40 | - | 29.30 | 49.70 | 55.29 | 43.34 | 77.06 | |
| YuLan-Mini | 2.4B | 1.04T | 4K | 32.60 | 66.65 | 61.60 | 66.70 | 55.71 | 43.58 | N/A | |
| YuLan-Mini | 2.4B | 1.08T | 28K | 37.80 | 68.46 | 64.00 | 65.90 | 57.18 | 44.57 | 51.48 |
🔼 표 6은 수학, 코드 및 장문 벤치마크에 대한 성능을 보여줍니다. * 표시된 결과는 해당 모델의 공식 논문이나 보고서에서 인용한 것입니다. 가장 좋은 결과와 두 번째로 좋은 결과는 각각 굵은 글씨체와 밑줄로 표시되어 있습니다. 이 표는 YuLan-Mini 모델의 성능을 다른 여러 기준 모델과 비교하여 보여주는 데 초점을 맞추고 있습니다. 특히 수학적 추론, 코드 생성 및 장문 이해와 관련된 벤치마크 작업에 대한 YuLan-Mini의 성능을 강조합니다.
read the caption
Table 6: Performance on math, code, and long context benchmarks. Results marked with * are cited from their official paper or report. The best and second best results are bold and underlined, respectively.
| Model | Size |
|---|
🔼 표 7은 commonsense 추론 벤치마크에 대한 성능을 보여줍니다. 이 표는 다양한 commonsense 추론 능력을 평가하기 위해 사용된 여러 벤치마크에서 YuLan-Mini 모델과 다른 모델들의 성능을 비교 분석합니다. 표에 제시된 결과는 각 모델의 평균 점수를 나타내며, 특히 연구 논문이나 보고서에서 발췌한 결과는 * 표시로 구분되어 있습니다.
read the caption
Table 7: Performance on commonsense reasoning benchmarks. Results marked with * are cited from their official paper or report.
| # Train | |
|---|---|
| Tokens |
🔼 이 표는 초매개변수를 계산하기 위해 사용된 변수들의 정의를 보여줍니다. 각 변수는 모델의 계층 수, 어텐션 헤드 수, 피드포워드 네트워크의 히든 사이즈, 임베딩 차원, 초기화 표준편차, 학습률 등 모델 아키텍처와 훈련 설정에 대한 중요한 정보를 담고 있습니다. 이러한 변수들의 정확한 정의는 하이퍼파라미터 최적화 및 모델 성능에 직접적인 영향을 미칩니다.
read the caption
Table 8: Definition of the variables for computing the hyperparameters.
| Context | Length |
|---|
🔼 표 9는 본 논문에서 훈련 역동성을 탐구하기 위해 사용된 소규모 프록시 모델들을 보여줍니다. 프록시 모델은 계산 비용을 줄이기 위해 실제 모델보다 작은 크기로 만들어졌으며, 주요 하이퍼파라미터(레이어 수, 모델 차원, 피드포워드 네트워크 크기, 헤드 수)를 비교하여 실제 모델과의 차이점을 확인할 수 있습니다. 이를 통해 실제 모델 훈련 과정에서 발생할 수 있는 불안정성을 소규모 모델에서 먼저 관찰하고 분석함으로써 효율적인 훈련 전략을 수립하는 데 도움이 됩니다.
read the caption
Table 9: Small proxy models used to explore the training dynamics.
| MATH | |
|---|---|
| 500 |
🔼 표 10은 YuLan-Mini 모델 사전 훈련에 사용된 모든 오픈소스 데이터셋의 목록입니다. 링크로만 제공되는 데이터셋의 경우, 프로젝트 웹사이트(https://github.com/RUC-GSAI/YuLan-Mini)에서 추가적인 안내를 제공합니다. 이 표는 데이터셋의 종류, 출처, 크기 등의 정보를 담고 있으며, YuLan-Mini 모델의 데이터 기반을 이해하는 데 도움을 줍니다.
read the caption
Table 10: Comprehensive list of all open-source datasets used. For datasets that are only available via links, we also offer additional guidance on our project website https://github.com/RUC-GSAI/YuLan-Mini.
| GSM | 8K |
|---|
🔼 표 12는 YuLan-Mini 모델의 사전 훈련 과정에서 사용된 데이터의 세부 구성을 훈련 커리큘럼 단계별로 보여줍니다. 각 단계(warmup, stable training, annealing)에서 사용된 데이터의 비율을 웹 페이지 데이터, 코드 데이터, 수학 데이터, 그리고 중국어 데이터로 구분하여 나타냅니다. 각 단계는 여러 개의 세부 단계로 나뉘며, 각 세부 단계마다 사용된 데이터셋의 비율이 자세하게 제시되어 있습니다. 이 표는 YuLan-Mini 모델의 데이터 효율적인 사전 훈련 과정을 재현하는 데 필요한 정보를 제공합니다.
read the caption
Table 12: Detailed data composition by training curriculum phases.
Full paper#



















