↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
기존의 다중 모드 대규모 언어 모델(MLLM)은 세부적인 이미지 캡션을 생성하는 데 탁월하지만, 종종 환각(hallucination) 현상을 일으켜 부정확한 정보를 생성하는 문제가 있습니다. 기존의 환각 감지 방법들은 세부적인 캡션에 대해서는 효과적이지 못하며, MLLM이 생성된 텍스트에 지나치게 의존하기 때문입니다. 이러한 문제는 캡션 길이가 길어질수록 더욱 심화됩니다.
본 논문에서는 이러한 문제를 해결하기 위해, LLM과 MLLM의 협업을 통해 캡션을 수정하는 다중 에이전트 시스템(CapMAS)을 제안합니다. 또한, 기존의 캡션 평가 지표가 세부적인 캡션의 사실성을 정확하게 평가하지 못하는 점을 지적하고, 사실성과 포괄성을 이중으로 평가하는 새로운 프레임워크와 벤치마크 데이터셋을 제시합니다. 실험 결과, CapMAS는 기존 방법보다 캡션의 사실성을 크게 향상시키는 것으로 나타났습니다. 특히, GPT-4V와 같은 최첨단 모델의 캡션도 개선하는 것을 보여주었습니다. 본 연구는 VQA 중심의 벤치마킹의 한계점을 보여주고, 향후 연구를 위한 새로운 방향을 제시합니다.
Key Takeaways#
Why does it matter?#
본 논문은 세부적인 이미지 캡션 생성의 어려움과 한계점을 다루면서, 다중 에이전트 접근 방식과 이중 평가 지표를 제시하여 이미지 캡션의 사실성과 포괄성을 향상시키는 방법을 제안합니다. 이는 현재의 VQA 중심 벤치마킹의 한계를 지적하고, 새로운 평가 프레임워크와 벤치마크 데이터셋을 제공하여 연구자들에게 중요한 시사점을 제공합니다. 향후 연구를 위한 새로운 방향을 제시하고, 보다 정확하고 포괄적인 이미지 캡션 생성 모델 개발에 기여할 수 있습니다.
Visual Insights#

🔼 이 그림은 논문에서 제시된 상세 이미지 캡션 생성 작업에서 환각(hallucination) 검출 방법을 평가하기 위한 데이터 샘플 생성 과정을 보여줍니다. LLaVA-NeXT 모델이 생성한 캡션을 사람이 검토하여 이미지에 없는 객체를 포함한 환각 부분을 식별하고 라벨링합니다. 즉, LLaVA-NeXT 모델이 이미지를 보고 생성한 캡션에서 실제 이미지에는 없는 내용(환각)이 있는지 사람이 확인하고 표시하는 과정을 시각적으로 나타낸 것입니다. 이를 통해, 환각 검출 방법의 성능을 체계적으로 평가할 수 있는 데이터셋을 구축하는 과정을 보여줍니다.
read the caption
Figure 1: The process of generating a data sample for evaluating hallucination detection methods in detailed image captioning tasks. Human annotators identify and label object hallucinations within the caption generated by LLaVA-NeXT (Liu et al., 2024a) for an image.
| Method | AUROC ↑ | FPR95 ↓ |
|---|---|---|
| Confidence | 57.5 | 95.1 |
| Consistency | 73.5 | 75.6 |
| Object Detector | 61.5 | 95.7 |
| Isolation | 81.4 | 71.7 |
🔼 표 1은 논문의 그림 1에 해당하는 데이터셋을 기반으로, 다양한 환각 검출 방법들의 성능을 비교 분석한 결과를 보여줍니다. 구체적으로, Confidence, Consistency, Object Detector, Isolation 네 가지 방법의 AUROC (Area Under the Receiver Operating Characteristic curve)와 FPR95 (False Positive Rate at 95% true positive rate) 값을 제시하여 각 방법의 환각 검출 정확도와 오탐율을 비교합니다. Isolation 방법이 다른 방법들보다 더 높은 AUROC 값과 낮은 FPR95 값을 보이며 가장 우수한 성능을 나타내는 것을 확인할 수 있습니다.
read the caption
Table 1: Performance comparison of hallucination detection methods for the dataset of Figure 1.
In-depth insights#
MLLM Hallucination#
MMLLM(다중 모드 대규모 언어 모델) 환각은 모델이 입력 이미지에 없는 객체나 속성을 묘사하거나, 객체 간의 관계를 잘못 표현하는 등의 부정확한 정보를 생성하는 현상을 말합니다. 이러한 환각은 모델이 이미지의 시각적 정보보다는 자체적으로 생성한 텍스트에 더 많이 의존하기 때문에 발생하며, 특히 긴 서술을 요구하는 과제에서 더욱 심각해집니다. 따라서, 자세한 이미지 캡션 생성에서는 이러한 환각 문제를 해결하는 것이 매우 중요합니다. 기존의 환각 감지 및 완화 기법들은 짧은 캡션에는 효과적이지만, 긴 세부적인 캡션에서는 성능이 저하되는 경향이 있습니다. 본 논문에서는 이 문제에 대한 해결책을 제시하고, 새로운 다중 에이전트 접근 방식과 이중 평가 지표를 통해 이 문제를 효과적으로 해결할 수 있는 방법을 제안합니다. 즉, LLM과 MLLM 간의 협업을 통해 생성된 캡션의 정확성을 높이고, 사실성과 적용범위를 모두 고려하는 새로운 평가 방법론을 제시하여 보다 효과적인 환각 감지 및 완화를 실현합니다.
Multiagent Approach#
본 논문에서 제시된 다중 에이전트 접근 방식은 **대규모 언어 모델(LLM)**과 다중 모달 대규모 언어 모델(MLLM) 간의 협업을 통해 이미지 캡션의 정확성을 높이는 방식입니다. LLM은 캡션을 원자적 명제로 분해하고, MLLM은 이미지 정보를 바탕으로 각 명제의 진위 여부를 판별합니다. 이를 통해 LLM은 캡션을 수정하고, 최종적으로 사실적이고 포괄적인 캡션을 생성합니다. 이러한 접근 방식은 기존의 단일 모델 방식보다 할루시네이션 문제를 효과적으로 해결할 수 있으며, 특히 세부적인 정보가 풍부한 캡션 생성에 유용합니다. LLM과 MLLM의 상호작용을 통해 모델의 한계를 극복하고, 인간의 개입 없이 자동으로 캡션을 개선하는 자율적인 시스템 구축이 가능하다는 점에서 큰 의의를 지닙니다. 다만, 이 접근 방식은 LLM과 MLLM의 성능에 의존적이며, 모델 간의 효율적인 협업을 위한 설계가 중요합니다. 또한, 원자적 명제 분해 및 진위 판별의 정확성이 전체 시스템의 성능을 좌우하기 때문에, 이 부분에 대한 지속적인 개선이 필요합니다.
Dual Evaluation Metrics#
논문에서 제시된 “이중 평가 지표"는 **사실성(Factuality)**과 **포괄성(Coverage)**이라는 두 가지 측면에서 상세한 이미지 캡션의 질을 평가하기 위한 혁신적인 접근 방식을 제안합니다. 기존의 단순 일치 기반 평가 방식의 한계를 극복하고, 인간의 판단과 더욱 잘 부합하는 평가를 가능하게 합니다. 사실성 지표는 캡션을 원자적 명제로 분해하고, 이미지 정보와의 일치 여부를 통해 사실성을 정량화합니다. 포괄성 지표는 이미지의 시각적 정보를 충분히 반영하는지 평가하기 위해, 이미지에 대한 다양한 질문에 캡션만을 이용해서 정확하게 답할 수 있는지를 측정합니다. 이러한 이중 지표는 단순히 캡션의 정확성 뿐 아니라, 이미지에 대한 풍부하고 포괄적인 정보 전달 여부까지 고려하여, 보다 균형 있고 정교한 평가를 제공합니다. 결과적으로, 이중 평가 지표는 MLLM 기반 이미지 캡션 시스템의 성능 개선에 중요한 역할을 할 것으로 기대됩니다.
CapMAS Framework#
본 논문에서 제시된 CapMAS 프레임워크는 다중 에이전트 접근 방식을 통해 상세한 이미지 캡션의 정확성을 향상시키는 데 초점을 맞추고 있습니다. 핵심은 LLM과 MLLM의 협업을 통해 캡션의 사실성을 검증하고 수정하는 것입니다. LLM은 캡션을 원자적 명제로 분해하고, MLLM은 이미지 정보를 바탕으로 각 명제의 진위 여부를 판별합니다. 오류 검출 및 수정 과정은 기존의 단일 모델 기반 방법론과 달리, 다양한 유형의 착시를 포괄적으로 다룰 수 있는 유연성을 제공합니다. 또한, 제시된 이중 평가 지표 (사실성 및 적용 범위)는 상세 캡션 평가의 어려움을 해결하고자 합니다. 기존 지표의 한계를 극복하여 인간의 판단과 더욱 잘 일치하는 평가를 가능하게 합니다. GPT-4V와 같은 최첨단 모델의 성능을 개선하는 데에도 효과적임을 보여주는 실험 결과는 CapMAS 프레임워크의 실용성과 잠재력을 보여줍니다. 하지만, VQA 벤치마킹의 한계 또한 지적하고 있어, 향후 연구에서 MLLM의 실제 활용성을 더욱 폭넓게 평가해야 함을 시사합니다.
VQA Benchmark Issue#
본 논문에서 제기하는 VQA 벤치마크 문제는 MLLM(다중 모드 대규모 언어 모델)의 VQA 성능과 실제 상세 이미지 캡셔닝 능력 간의 상관관계 부족에 있습니다. VQA 벤치마크는 주로 짧고 간결한 응답을 요구하지만, 실제 이미지 캡셔닝, 특히 상세한 캡셔닝은 훨씬 더 긴 답변과 복잡한 시각적 정보 이해를 필요로 합니다. 따라서 VQA에서 좋은 성능을 보이는 MLLM이 상세 이미지 캡셔닝에서도 뛰어난 성능을 보인다는 보장이 없다는 점을 강조하고 있습니다. 이는 기존의 VQA 중심 벤치마킹의 한계를 보여주는 것으로, 상세 이미지 캡셔닝 평가를 위한 새로운 벤치마크 및 평가 지표의 필요성을 시사합니다. 단순히 VQA 성능만으로 MLLM의 실제 응용 능력을 판단하는 것은 부족하며, 상세 이미지 캡셔닝과 같은 실제 작업에서의 성능을 평가하는 것이 중요함을 강조하고 있습니다. 따라서 새로운 평가 방법론을 통해 MLLM의 실질적인 성능을 보다 정확하게 평가하고 개선하는 방안을 모색해야 함을 제시합니다.
More visual insights#
More on figures
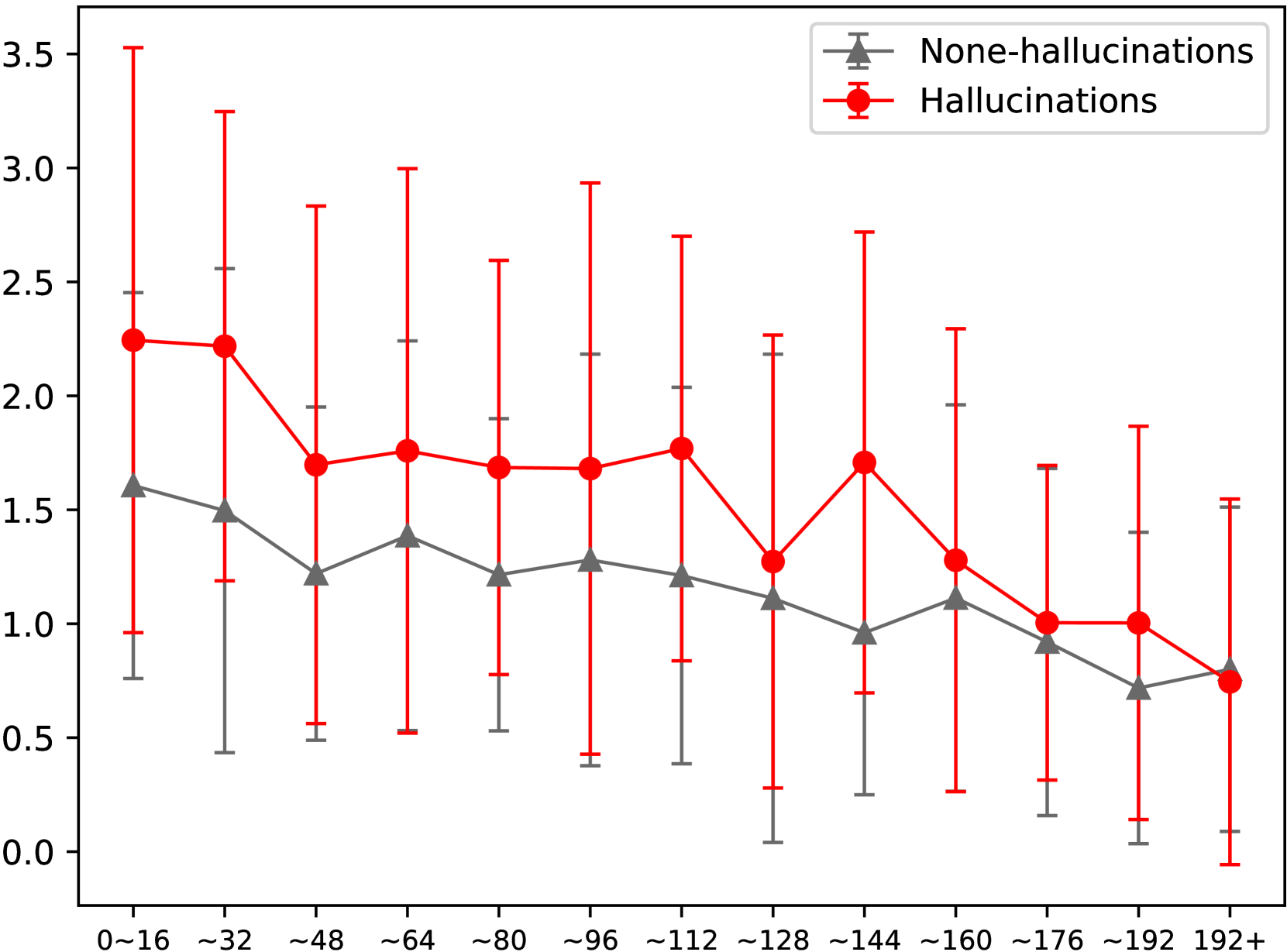
🔼 그림 2(a)는 세부적인 캡션 내 개체의 위치에 따른 신뢰도 기반 방법의 환각 점수를 보여줍니다. 가로축은 캡션 내 토큰의 인덱스를 나타내며, 큰 토큰 인덱스는 캡션의 끝에 가까운 위치를 나타냅니다. 세로축은 각 구간 내 환각 점수의 평균과 표준 편차를 나타냅니다. 탐욕적 디코딩 중 생성된 환각은 192번째 토큰 이후에는 신뢰도 방법으로 감지할 수 없습니다.
read the caption
(a) Confidence-Token Index
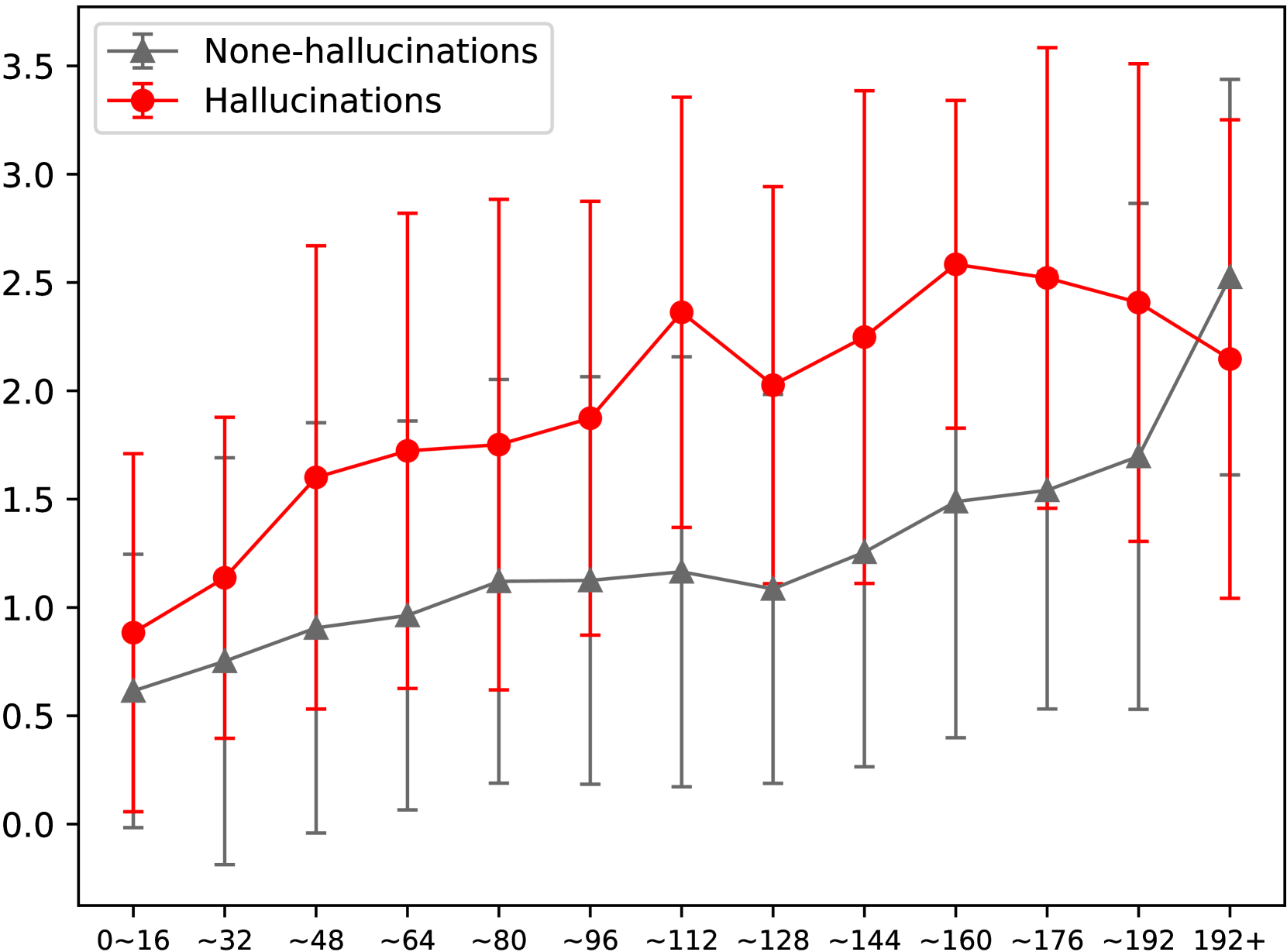
🔼 그림 2(b)는 자세한 캡션 내 개체 위치에 따른 일관성 방법의 환각 점수를 보여줍니다. 가로축은 캡션 내 개체 토큰 색인의 구간을 나타내고, 세로축은 각 구간 내 환각 점수의 평균과 표준 편차를 나타냅니다. 토큰 색인이 클수록 캡션의 끝에 가까워짐을 의미합니다. 그림은 192번째 토큰 이후에 생성된 환각은 일관성 방법으로는 탐지할 수 없음을 보여줍니다.
read the caption
(b) Consistency-Token Index
More on tables
| Caption | CIDEr | CLIP-S | RefCLIP-S | CLAIR | ALOHa | Ours |
|---|---|---|---|---|---|---|
| Clean | 6.4 | 81.3 | 75.5 | 86.9 | 36.2 | 62.8 |
| Object | 4.8 | 81.0 | 75.3 | 85.2 | 31.5 | 52.3 |
| Attribution | 6.2 | 80.9 | 75.2 | 80.0 | 34.3 | 60.9 |
| Relation | 6.7 | 81.4 | 75.6 | 83.5 | 36.9 | 51.9 |
🔼 본 표는 다양한 캡션 평가 방법에 대한 메타 평가 결과를 보여줍니다. DOCCI 데이터셋과 합성적 환각 캡션을 사용하여 메타 평가를 수행했습니다. 각 방법에 대해 가장 높은 점수를 받은 캡션은 굵게 표시되어 있으며, 전체 표는 부록 D에 있습니다. 표는 깨끗한 캡션, 객체 오류 캡션, 속성 오류 캡션, 관계 오류 캡션의 네 가지 유형에 대해 BLEU, ROUGE, METEOR, CIDEr, CLIP-S, RefCLIP-S, CLAIR, ALOHA 및 제안된 새로운 방법의 점수를 비교 분석합니다.
read the caption
Table 2: Meta-evaluation results across various caption evaluation methods. DOCCI and its synthetic hallucinatory captions are used for the meta-evaluation. The highest-rated caption for each method is highlighted in bold. The full table is in Appendix D.
| Metric | FAITHSCORE | FACTSCORE | Ours |
|---|---|---|---|
| Spearman’s ρ | 62.5 | 67.9 | 70.2 |
🔼 본 표는 사람이 평가한 내용과 자동화된 지표 간의 상관관계를 비교 분석한 표입니다. 자동화된 지표는 이미지 캡션의 사실성을 평가하는 데 사용됩니다. 구체적으로, FAITHSCORE, FACTSCORE, 그리고 논문에서 제안된 새로운 지표 세 가지를 비교하여 사람의 평가와 얼마나 잘 일치하는지 보여줍니다. 이는 제안된 새로운 지표의 신뢰성을 평가하는 데 중요한 역할을 합니다.
read the caption
Table 3: Comparison of correlations between human preferences and automated metrics in terms of factuality.
| Captioner | CapMAS | Metric | ||||
|---|---|---|---|---|---|---|
| LLM | MLLM | CLAIR | Factuality | Coverage | Avg. | |
| LLaVA-NeXT-7B | - | - | 68.8 | 59.9 | 47.9 | 58.9 |
| LLaMA-3-8B | LLaVA-NeXT-7B | 74.1 | 72.2 | 46.9 | 64.4 | |
| GPT-4 | LLaVA-NeXT-7B | 74.6 | 73.4 | 46.2 | 64.7 | |
| LLaVA-NeXT-13B | - | - | 70.2 | 62.1 | 48.5 | 60.3 |
| LLaMA-3-8B | LLaVA-NeXT-13B | 75.5 | 77.9 | 45.8 | 66.4 | |
| GPT-4 | LLaVA-NeXT-13B | 73.4 | 79.3 | 45.1 | 65.9 | |
| InternVL-Chat-V1.5 | - | - | 74.9 | 65.5 | 48.2 | 62.9 |
| LLaMA-3-8B | InternVL-Chat-V1.5 | 78.2 | 75.9 | 47.3 | 67.1 | |
| GPT-4 | InternVL-Chat-V1.5 | 77.8 | 75.7 | 47.3 | 66.9 | |
| GPT-4V | - | - | 82.4 | 77.1 | 53.5 | 71.0 |
| LLaMA-3-8B | LLaVA-NeXT-7B | 83.3 | 83.3 | 50.8 | 72.4 | |
| LLaMA-3-8B | LLaVA-NeXT-13B | 81.9 | 85.3 | 48.4 | 71.9 | |
| LLaMA-3-8B | InternVL-Chat-V1.5 | 84.6 | 82.1 | 53.5 | 73.4 |
🔼 본 표는 제안된 CapMAS 방법의 다양한 캡션 생성 모델에 대한 효과를 보여줍니다. CapMAS 열에서 LLM은 캡션 분해 및 수정을 담당하고 MLLM은 사실 확인을 담당합니다. 평균(Avg.)은 CLAIR, 사실성, 적용 범위의 평균값을 나타냅니다. 다양한 LLM과 MLLM 조합에 따른 CLAIR 점수, 사실성 점수, 적용 범위 점수 및 평균 점수를 보여줍니다.
read the caption
Table 4: Effectiveness of our proposed method across various captioning models. In the CapMAS column, the LLM represents the decomposer and corrector, while the MLLM represents the fact-checker. Avg. denotes the average of CLAIR, Factuality, and Coverage.
| Method | CLAIR | Factuality | Coverage | Avg. |
|---|---|---|---|---|
| Base | 62.1 | 52.8 | 34.3 | 49.7 |
| VCD (Leng et al., 2024) | 59.7 | 44.6 | 39.3 | 47.9 |
| OPERA (Huang et al., 2024) | 59.1 | 53.0 | 34.1 | 48.7 |
| LURE (Zhou et al., 2024) | 57.2 | 51.9 | 27.6 | 45.6 |
| Volcano (Lee et al., 2024) | 63.9 | 53.7 | 37.7 | 51.7 |
| LRV (Liu et al., 2023a) | 39.7 | 29.1 | 37.8 | 35.5 |
| CapMAS (ours) | 66.3 | 63.4 | 33.1 | 54.3 |
🔼 표 5는 제안된 방법과 다른 방법들을 비교하여 상세한 이미지 캡션 생성 성능을 보여줍니다. 기준(Base)은 LLaVA-v1.5-7B 모델의 기본 이미지 캡션 생성 결과입니다. 표에는 제안된 방법과 기존의 여러 캡션 생성 방법들(VCD, OPERA, LURE, Volcano, LRV)의 성능을 CLAIR 점수, 사실성 점수, 적용범위 점수, 그리고 평균 점수를 사용하여 비교 분석한 결과가 제시되어 있습니다. 이를 통해 제안된 방법의 우수성을 보여주고자 합니다.
read the caption
Table 5: Performance comparison between our proposed method and other methods regarding detailed image captioning. Base refers to the default image captioning of LLaVA-v1.5-7B.
| Model | CLAIR | OpenCompass | ||||||
|---|---|---|---|---|---|---|---|---|
| Detailed Image Captioning | Visual Question Answering | |||||||
| CLAIR | Factuality | Coverage | Avg. | OpenCompass | MME | POPE | Avg. | |
| InstructBLIP-7B | 57.2 | 44.4 | 30.3 | 43.9 | 31.1 | 1391.4 | 86.1 | 38.4 |
| LLaVA-v1.5-7B | 61.1 | 56.3 | 30.5 | 49.3 | 36.9 | 1808.4 | 86.1 | 44.6 |
| LLaVA-NeXT-7B | 63.8 | 58.5 | 42.2 | 54.8 | 44.7 | 1769.1 | 87.5 | 50.8 |
| LLaVA-NeXT-13B | 64.5 | 62.8 | 43.0 | 56.8 | 47.6 | 1745.6 | 87.8 | 53.1 |
| Idefics2-8B | 58.1 | 85.2 | 13.4 | 52.2 | 53.0 | 1847.6 | 86.2 | 57.6 |
| InternVL-Chat-V1.5 | 72.4 | 67.6 | 46.0 | 62.0 | 61.7 | 2189.6 | 87.5 | 65.9 |
| MiniCPM-V-2.6 | 73.1 | 68.9 | 43.6 | 61.9 | 65.2 | 2268.7 | 83.2 | 68.6 |
| GPT-4V | 82.4 | 78.6 | 52.6 | 71.2 | 63.5 | 2070.2 | 81.8 | 66.4 |
🔼 표 6은 다양한 다중 모달 대규모 언어 모델(MLLM)의 상세 이미지 캡션 생성 및 VQA 성능을 보여줍니다. OpenCompass(Duan et al., 2024)는 MMBench v1.1(Liu et al., 2023c), MMStar(Chen et al., 2024a), MMMU val(Yue et al., 2024), MathVista(Lu et al., 2024), OCRBench(Liu et al., 2024d), AI2D(Kembhavi et al., 2016), HallusionBench(Guan et al., 2024), MMVet(Yu et al., 2023)를 포함합니다. POPE(Li et al., 2023b)의 경우 세 가지 범주(적대적, 일반적, 무작위)에 걸친 평균 F1 점수를 보고하며, MME(Yin et al., 2023b)는 인지 및 인식 점수의 합계를 보고합니다. 각 지표에 대한 최고 점수는 굵게 표시되어 있습니다.
read the caption
Table 6: Detailed image captioning and VQA performance of various MLLMs. OpenCompass (Duan et al., 2024) includes MMBench v1.1 (Liu et al., 2023c), MMStar (Chen et al., 2024a), MMMU val (Yue et al., 2024), MathVista (Lu et al., 2024), OCRBench (Liu et al., 2024d), AI2D (Kembhavi et al., 2016), HallusionBench (Guan et al., 2024), and MMVet (Yu et al., 2023). For POPE (Li et al., 2023b), we report the average F1 score across the three categories: adversarial, popular, and random. We report the sum of the perception and cognition scores for MME (Yin et al., 2023b). The best results for each metric are shown in bold.
| Task | FACTSCORE | Ours |
|---|---|---|
| LLaVA-v1.5-7B vs. InstructBLIP | 67.9 | 70.2 |
| HUMAN vs. LLaVA-v1.5-7B vs. InstructBLIP | 18.3 | 61.4 |
🔼 본 표는 사람의 평가와 자동화된 지표 간의 상관관계를 비교하여 문장의 사실성을 평가하는 방법을 보여줍니다. LLaVA-v1.5-7B와 InstructBLIP 두 모델의 문장에 대한 인간의 사실성 평가와, FAITHSCORE, FACTSCORE 및 제안된 지표의 상관관계를 스피어만 상관계수(Spearman’s ρ)를 사용하여 측정하였습니다. 이를 통해 제안된 지표가 기존 지표보다 인간의 판단과 더 높은 상관관계를 보임을 보여줍니다.
read the caption
Table 7: Comparison of correlations between human preferences and automated metrics in terms of factuality.
| Captioner | CapMAS | Metric | ||||
|---|---|---|---|---|---|---|
| LLM | MLLM | π | CLAIR | Factuality | Coverage | |
| LLaVA-NeXT-7B | - | - | - | 68.8 | 59.9 | 47.9 |
| LLaMA-3-8B | LLaVA-NeXT-7B | 1.0 | 74.1 | 72.2 | 46.9 | |
| LLaMA-3-8B | LLaVA-NeXT-7B | 0.5 | 73.6 | 76.9 | 43.7 | |
| LLaMA-3-8B | LLaVA-NeXT-7B | 0.3 | 72.2 | 76.8 | 40.0 | |
| LLaVA-NeXT-13B | - | - | - | 70.2 | 62.1 | 48.5 |
| LLaMA-3-8B | LLaVA-NeXT-13B | 1.0 | 75.5 | 77.9 | 45.8 | |
| LLaMA-3-8B | LLaVA-NeXT-13B | 0.5 | 74.8 | 79.9 | 42.1 | |
| LLaMA-3-8B | LLaVA-NeXT-13B | 0.3 | 72.6 | 80.5 | 39.6 | |
| InternVL-Chat-V1.5 | - | - | - | 74.9 | 65.5 | 48.2 |
| LLaMA-3-8B | InternVL-Chat-V1.5 | 1.0 | 78.2 | 75.9 | 47.3 | |
| LLaMA-3-8B | InternVL-Chat-V1.5 | 0.5 | 79.0 | 78.8 | 46.0 | |
| LLaMA-3-8B | InternVL-Chat-V1.5 | 0.3 | 77.7 | 81.7 | 42.5 |
🔼 표 8은 제안된 CapMAS 방법의 다양한 캡션 생성 모델에 대한 효과를 보여줍니다. π 값을 변화시키면서(π는 CapMAS에서 환각 요소를 구분하는 임계값 역할) LLM(분해기 및 수정기)과 MLLM(사실 확인기)의 성능을 비교 분석합니다. 다양한 모델(LLaVA-NeXT-7B, LLaVA-NeXT-13B, InternVL-Chat-V1.5)과 LLM(LLaMA-3-8B, GPT-4) 조합에 따른 CLAIR 점수, 사실성 점수, 적용범위 점수의 변화를 π 값의 변화에 따라 보여주는 표입니다. π값이 감소할수록 사실성은 증가하지만 적용범위는 감소하는 경향을 보여주는 사실성과 적용범위 간의 상관관계를 분석하는 데 사용됩니다.
read the caption
Table 8: Effectiveness of our proposed method across various captioning models as a function of π𝜋\piitalic_π. In the CapMAS column, the LLM represents the decomposer and corrector, while the MLLM represents the fact-checker.
| Caption | BLEU | ROUGE | METEOR | CIDEr | CLIP-S | RefCLIP-S | CLAIR | ALOHa | Ours |
|---|---|---|---|---|---|---|---|---|---|
| Clean | 4.2 | 22.0 | 13.7 | 6.4 | 81.3 | 75.5 | 86.9 | 36.2 | 62.8 |
| Object | 4.9 | 22.3 | 14.5 | 4.8 | 81.0 | 75.3 | 85.2 | 31.5 | 52.3 |
| Attribution | 4.1 | 21.8 | 13.6 | 6.2 | 80.9 | 75.2 | 80.0 | 34.3 | 60.9 |
| Relation | 4.1 | 21.8 | 13.7 | 6.7 | 81.4 | 75.6 | 83.5 | 36.9 | 51.9 |
🔼 표 9는 다양한 캡션 평가 방식에 대한 메타 평가 결과를 보여줍니다. DOCCI 데이터셋과 합성 환각 캡션을 사용하여 메타 평가를 수행했습니다. 각 방식에 대해 가장 높은 점수를 받은 캡션은 굵게 표시되어 있습니다. BLEU, ROUGE, METEOR, CIDEr, CLIP-S, RefCLIP-S, CLAIR, ALOHA 및 제안된 방식을 포함한 여러 캡션 평가 지표를 사용하여 깨끗한 캡션, 개체(Object), 속성(Attribution), 관계(Relation) 등 네 가지 유형의 캡션을 평가했습니다.
read the caption
Table 9: Meta-evaluation results across various caption evaluation methods. DOCCI and its synthetic hallucinatory captions are used for the meta-evaluation. The highest-rated caption for each method is highlighted in bold.
Full paper#















