↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
네덜란드어와 같은 저자원 언어에 대한 자연어 처리 모델 개발은 영어 중심 모델의 성능 저하로 인해 어려움을 겪고 있습니다. 기존의 대규모 언어 모델(LLM)은 주로 영어 데이터로 학습되어 다른 언어에 대한 성능이 떨어집니다. 이러한 문제를 해결하기 위해 다양한 전략들이 연구되었지만, 각 전략은 한계를 가지고 있습니다. 이 논문에서는 이러한 문제점들을 설명합니다.
본 논문에서는 네덜란드어를 위한 소형 언어 모델인 Fietje를 제시합니다. Fietje는 오픈 소스이며, 모델 가중치, 데이터셋, 학습 및 평가 코드를 모두 공개하여 투명성과 재현성을 확보했습니다. Fietje는 다양한 벤치마크에서 대형 모델과 경쟁력 있는 성능을 보여주었고, 특히 다국어 사전 학습의 중요성을 강조했습니다. 본 연구는 자원이 부족한 언어에 대한 LLM 개발에 크게 기여하며, 향후 연구 방향을 제시합니다.
Key Takeaways#
Why does it matter?#
이 논문은 소규모 언어 모델의 성능을 향상시키는 데 있어서 다국어 사전 학습의 중요성을 강조하며, 자원이 부족한 언어에 대한 연구를 위한 새로운 방향을 제시합니다. 또한, 모델의 투명성과 재현성을 강조하여 다른 연구자들이 연구 결과를 쉽게 활용하고 발전시킬 수 있도록 합니다. 이는 자원이 부족한 언어 처리 연구에 큰 영향을 미칠 수 있습니다.
Visual Insights#

🔼 그림 1(a)는 논문의 4.4절 결과 섹션에 있는 그림으로, 다양한 언어 모델의 크기와 중간 성능 간의 관계를 보여줍니다. 이 그림은 모델 크기가 클수록 성능이 항상 좋아지는 것은 아님을 시각적으로 보여줍니다. 특히, 특정 언어에 맞춰 조정되지 않은 모델들만 비교했을 때, 더 큰 모델보다 더 작은 모델들이 더 나은 성능을 보이는 경우가 있습니다. 이는 모델의 크기보다는 다른 요소들(예: 데이터 품질, 훈련 방법, 출시일 등)이 모델 성능에 더 큰 영향을 미칠 수 있음을 시사합니다.
read the caption
(a) All models
| name | date | size | type | Dutch-specific | data transparency | training transparency | finetuned from | wiki fertility | wiki tps | wiki s |
|---|---|---|---|---|---|---|---|---|---|---|
| fietje-2b | 4/24 | 2.8B | base | yes | yes | yes | phi-2 | 9501.41 ± 0.66 | 2.05 | 440.41 ± 0.03 |
| fietje-2b-chat | 4/24 | 2.8B | chat | yes | yes | yes | fietje-2b-instruct | 9501.41 ± 0.66 | 2.05 | 440.41 ± 0.03 |
| fietje-2b-instruct | 4/24 | 2.8B | instruct | yes | yes | yes | fietje-2b | 9501.70 ± 4.72 | 2.05 | 440.40 ± 0.22 |
| GEITje-7B-ultra | 1/24 | 7.2B | chat | yes | yes | yes | GEITje-7B | 4035.27 ± 0.64 | 1.97 | 999.42 ± 0.16 |
| Llama-3.2-3B-Instruct | 9/24 | 3.2B | instruct | no | partly | partly | Llama-3.2-3B | 7884.63 ± 0.36 | 1.74 | 451.97 ± 0.02 |
| phi-2 | 12/23 | 2.8B | base | no | no | no | none | 9631.95 ± 16.12 | 2.05 | 434.44 ± 0.73 |
| Phi-3.5-mini-instruct | 8/24 | 3.8B | instruct | underspecified | no | no | none | 6633.85 ± 0.68 | 1.89 | 584.14 ± 0.06 |
| Mistral-7B-Instruct-v0.1 | 9/23 | 7.2B | instruct | no | unclear16 | no | none | 4027.81 ± 1.14 | 1.97 | 1001.27 ± 0.28 |
| Mistral-7B-v0.1 | 9/23 | 7.2B | base | no | no | no | Mistral-7B-v0.1 | 4046.46 ± 0.67 | 1.97 | 996.66 ± 0.16 |
| Qwen2.5-3B-Instruct | 9/24 | 3.1B | instruct | underspecified | no | no | Qwen2.5-3B | 8094.26 ± 0.53 | 1.82 | 459.94 ± 0.03 |
| GEITje-7B | 12/23 | 7.2B | base | yes | partly | yes | Mistral-7B-v0.1 | 4021.61 ± 1.64 | 1.97 | 1002.82 ± 0.41 |
| tweety-7b-dutch-v24a | 5/24 | 7.4B | base | yes | yes | partly | Mistral-7B-v0.1 | 3979.88 ± 2.12 | 1.41 | 728.56 ± 0.39 |
| Boreas-7B | 4/24 | 7.2B | base | yes | partly | partly | Mistral-7B-v0.1 | 4032.05 ± 15.28 | 1.97 | 1000.23 ± 3.78 |
| Boreas-7B-chat | 4/24 | 7.2B | instruct | yes | partly | partly | Boreas-7B | 4034.36 ± 0.69 | 1.97 | 999.65 ± 0.17 |
🔼 표 1은 벤치마킹에 사용된 언어 모델들을 개괄적으로 보여줍니다. 각 모델의 특징과 성능 지표를 비교 분석하여, 네덜란드어에 특화된 모델 여부, 데이터 및 학습 과정의 투명성, 토큰 효율성(wiki fertility), 초당 토큰 처리량(wiki tps), Wikipedia 처리 시간(wiki s) 등을 제시합니다. wiki tps 와 wiki s 는 단일 RTX 3090 GPU를 사용하여 bfloat16 형식과 Flash Attention 2를 활성화한 상태에서 측정되었고, 배치 크기는 1이며, 모든 모델의 최대 문맥 길이 또는 최대 8192 토큰을 사용했습니다. 보고된 평균 지표와 신뢰 구간은 세 번의 실행 결과를 기반으로 합니다.
read the caption
Table 1: Overview of benchmarked models. Dutch-specific: did the model undergo (re-)training specifically for Dutch? data/training transparency: are the data and training procedure described in detail (reproducible) and is the data and training code publicly available? wiki fertility: how many tokens are needed on average to encode one word, calculated on full Dutch Wikipedia. Lower = more efficient. wiki tps: Tokens-per-second throughput on first 10,000 Wikipedia documents. How many tokens can the model process per second. wiki s: Processing time of first 10,000 Wikipedia documents. Lower = faster. wiki tps and wiki s were calculated on an isolated RTX 3090 in bfloat16 with Flash Attention 2 enabled. Batch size was 1 and all models’ maximum context length was used, or 8192 at most. The reported mean metrics and their CI are based on the results of three runs.
In-depth insights#
Open LLM for Dutch#
본 논문은 네덜란드어를 위한 오픈 소스 대규모 언어 모델(LLM) 개발에 대한 심도있는 논의를 제공합니다. 네덜란드어 LLM의 개발은 영어 중심적인 LLM의 편향성을 극복하고, 네덜란드어 자원의 부족 문제를 해결하기 위한 중요한 시도입니다. 논문에서는 모델의 아키텍처, 학습 데이터, 성능 평가 결과를 상세히 제시하며, 투명성과 재현성을 강조합니다. 특히, 공개된 모델 가중치, 데이터셋, 코드 등은 다른 연구자들의 후속 연구를 촉진하는데 기여할 것입니다. 다양한 벤치마크 평가 결과를 통해, 소규모 모델임에도 불구하고 기존의 대형 모델들과 경쟁력 있는 성능을 보임을 확인합니다. 모델의 한계점과 향후 연구 방향에 대한 논의 또한 포함되어 있으며, 이는 네덜란드어 LLM 연구의 지속적인 발전에 중요한 이정표가 될 것입니다. 오픈 소스 접근 방식은 다른 언어 모델 개발에도 긍정적인 영향을 줄 것으로 예상되며, 소외된 언어에 대한 기술 접근성 향상에 크게 기여할 것입니다. 학습 데이터의 품질과 모델의 효율성을 개선하기 위한 노력이 지속되어야 하며, 다양한 언어 모델 평가 프레임워크 개발도 중요한 과제입니다.
Phi-2 Adaptation#
본 논문에서 다루는 ‘Phi-2 Adaptation’ 부분은 Phi-2 모델을 네덜란드어에 적용하는 과정에 대한 심층적인 분석을 제공합니다. 이는 단순한 언어 모델의 이식이 아니라, 네덜란드어 특성에 맞춰 모델을 개선하는 노력을 보여줍니다. 이를 위해 대규모 네덜란드어 데이터셋을 활용한 추가 학습이 진행되었으며, 이 과정에서 데이터의 품질과 전처리에 대한 세심한 고려가 있었음을 알 수 있습니다. 모델의 투명성과 재현성을 강조하며, 사용된 데이터와 코드를 공개함으로써 학계의 후속 연구에 기여하고자 하는 의도 또한 명확하게 드러납니다. 결과적으로 Phi-2의 네덜란드어 적용은 단순한 언어 지원 확장을 넘어, 소규모 언어 모델의 성능 향상 및 연구 발전에 기여하는 중요한 사례로 볼 수 있습니다. 특히 제한된 자원 환경에서도 효율적이고 성능 좋은 언어 모델을 구축할 수 있음을 보여주는 중요한 시사점을 제공합니다. 다만, 데이터 품질의 중요성과 지속적인 모델 개선의 필요성도 함께 제기됩니다.
Benchmark Analysis#
본 논문은 다양한 언어 모델의 성능을 벤치마크 분석을 통해 비교 평가합니다. 특히, 소규모 언어 모델임에도 불구하고 우수한 성능을 보이는 모델들을 중점적으로 다루며, 모델 크기와 성능 간의 관계에 대한 심층적인 분석을 제공합니다. 다양한 벤치마크 작업에서 모델의 강점과 약점을 명확히 제시하고, 모델의 출시 시점과 성능 간의 상관관계를 밝힘으로써 언어 모델 발전의 동향을 파악합니다. 또한, 기존 벤치마크의 한계점을 지적하고 보다 개선된 평가 방식에 대한 제언을 제시합니다. 다국어 모델의 중요성을 강조하고, 다양한 언어에 대한 벤치마크 데이터셋 구축의 필요성을 강조하며 연구의 미래 방향을 제시합니다. 결론적으로, 이 연구는 벤치마크 분석을 통해 언어 모델의 성능을 종합적으로 평가하고 그 결과를 바탕으로 향후 연구 방향을 제시하는 데 큰 의의가 있습니다.
Multilingual Impact#
본 논문은 다국어 언어 모델의 영향에 대해 심도있는 분석을 제공합니다. 특히 영어 중심 모델에서 다국어 모델로의 전환이 네덜란드어 처리 성능에 미치는 영향을 자세히 살펴봅니다. 다국어 학습을 통해 규모가 작은 모델도 이전보다 더 큰 모델과 경쟁력을 갖추게 되었고, 네덜란드어와 같은 저자원 언어에도 적용될 수 있음을 보여줍니다. 모델의 크기보다는 출시일이 성능에 더 큰 영향을 미치는 것으로 나타나며, 최신 모델이 다국어 기능을 향상시킨 결과, 네덜란드어 특화 모델보다 성능이 뛰어난 경우도 있습니다. 하지만 다국어 모델의 성능은 과제의 종류에 따라 차이가 있으며, 특정 과제에서는 다국어 모델의 성능이 저조할 수 있다는 점도 지적합니다. 따라서 다국어 모델의 영향을 정확히 평가하려면 다양한 과제와 벤치마크를 포괄적으로 고려해야 합니다. 투명성과 재현성을 강조하여, 데이터와 코드를 공개하여 연구의 신뢰도를 높였습니다. 결론적으로, 다국어 모델의 발전은 저자원 언어 처리의 접근성을 높이는 데 기여하며, 앞으로 다국어 모델 개발과 평가에 대한 더 많은 연구가 필요함을 시사합니다.
Future Directions#
본 논문은 네덜란드어를 위한 소형 언어 모델인 Fietje의 개발에 중점을 두고 있습니다. 미래 방향에 대한 고찰은 Fietje의 한계점을 극복하고 성능을 향상시키기 위한 여러 가지 전략을 제시해야 합니다. 더욱 방대한 고품질 데이터셋 확보는 모델의 정확성과 유창성 향상에 필수적이며, 다국어 사전 학습 및 세분화된 지도 학습을 통해 Fietje의 성능을 더욱 개선할 수 있을 것입니다. 다양한 평가 지표 개발 또한 중요한데, 특히 유창성, 문맥 이해 및 뉘앙스와 같은 질적인 측면을 포괄하는 지표가 필요합니다. 나아가, 네덜란드어 특유의 어휘 및 문법적 특징을 반영한 모델 개선이 필요하며, 다양한 사용자 요구를 충족하는 맞춤형 모델 개발도 중요한 미래 방향입니다. 마지막으로, 모델의 투명성 및 재현성을 유지하면서 지속적인 개선을 위한 연구가 필요합니다. 이는 오픈소스 기반의 개발과 공유를 통해 가능합니다.
More visual insights#
More on figures

🔼 그림 1(b)는 특정 언어에 맞춰 수정되지 않은 모델들만을 대상으로 모델 크기와 중간 성능 간의 관계를 보여줍니다. 이는 모델 크기가 클수록 성능이 항상 향상되는 것은 아니며, 최신 모델들이 더 나은 성능을 보이는 경향이 있음을 보여주는 추가 분석입니다. 모델의 크기가 성능과 직접적인 상관관계가 없다는 점을 시각적으로 보여주는 중요한 그림입니다.
read the caption
(b) Without modified models

🔼 이 그림은 모델 크기와 중간 성능 간의 관계를 보여줍니다. 그림 (a)는 논문에서 분석된 모든 모델을 포함하고, 그림 (b)는 특정 언어에 맞춰 조정되지 않은 모델만을 보여줍니다. 이 그림을 통해 모델 크기가 반드시 성능과 비례하지 않음을 알 수 있습니다. 특히, 최근에 출시된 소형 모델들이 이전의 대형 모델보다 성능이 더 뛰어난 경우가 있음을 보여줍니다. 이는 모델의 크기보다는 모델의 훈련 데이터와 아키텍처의 발전이 더 중요하다는 것을 시사합니다.
read the caption
Figure 1: Model size vs. median performance

🔼 그림 1(a)는 논문의 4.4절 “결과” 섹션에 있는 그림으로, 다양한 언어 모델의 크기와 중간 성능 간의 관계를 보여줍니다. 이 그림은 모델 크기가 클수록 성능이 항상 향상되는 것은 아님을 시각적으로 보여주는 역할을 합니다. 모델의 크기는 X축에 표시되고, Y축은 다양한 벤치마크에 대한 중간 성능을 나타냅니다. 이 그림은 여러 모델을 비교하여 모델 크기가 성능에 미치는 영향을 분석하는 데 사용됩니다. 모델 크기와 성능 간의 관계가 선형적이지 않다는 점을 보여줍니다. 일부 소형 모델은 대형 모델보다 성능이 우수합니다. 이것은 모델의 크기가 성능의 유일한 지표는 아니라는 것을 강조합니다.
read the caption
(a) All models

🔼 그림 1(b)는 특정 언어(네덜란드어)에 맞춰 수정되지 않은 언어 모델들만을 대상으로 모델 크기와 중간 성능 간의 관계를 보여줍니다. 네덜란드어에 특화된 모델들을 제외하여 모델 크기와 성능 간의 상관관계를 더 명확하게 보여주는 것입니다. 이를 통해 네덜란드어에 대한 특별한 최적화 없이도 최신 모델이 더 큰 모델보다 성능이 더 뛰어날 수 있다는 점을 시각적으로 보여줍니다.
read the caption
(b) Without modified models

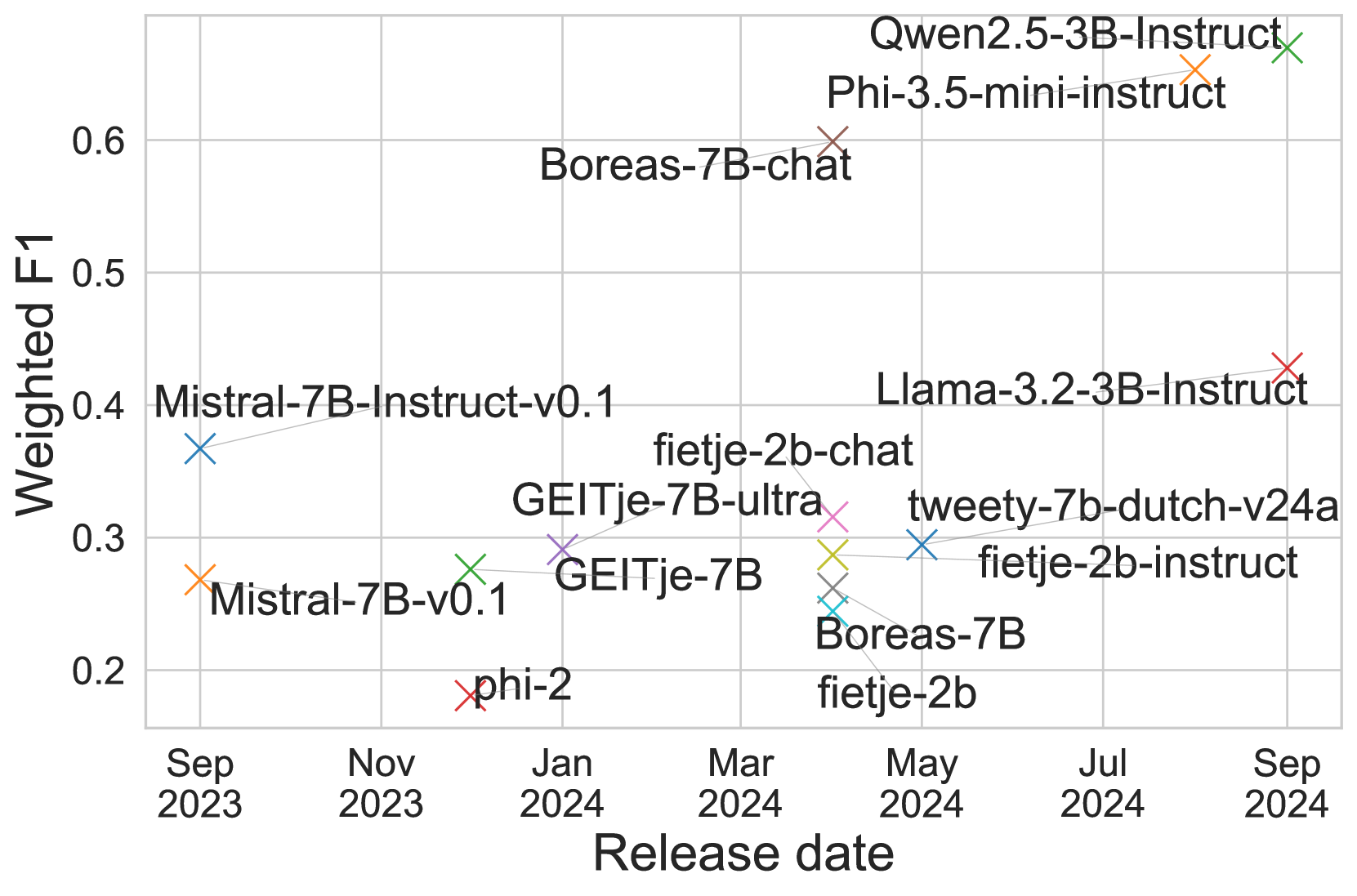
🔼 이 그림은 모델의 출시일과 중간 성능 간의 관계를 보여줍니다. 그림 (a)는 논문에서 다룬 모든 모델을 포함하며, 그림 (b)는 특별히 더치어에 맞춰 수정되지 않은 모델만을 보여줍니다. 이 그림을 통해 최신 모델이 이전 모델보다 성능이 더 우수하다는 점을 알 수 있습니다. 특히 더치어에 맞춰 조정되지 않은 모델들만 비교해보면 그 경향이 더욱 분명하게 나타납니다. 모델의 크기보다는 출시일이 성능에 더 큰 영향을 미치는 것으로 보입니다.
read the caption
Figure 2: Model release date vs. median performance
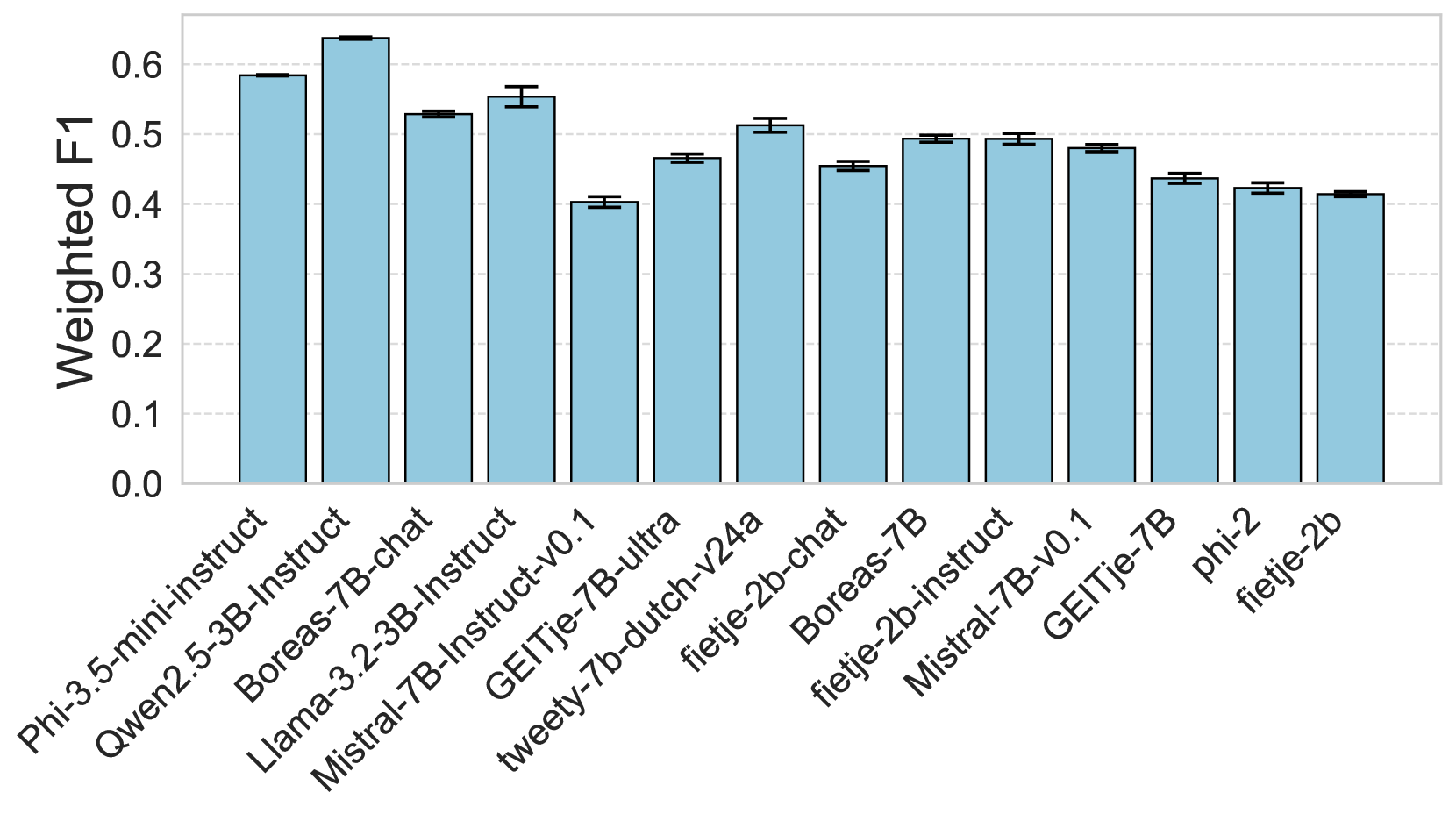
🔼 그림 4(a)는 AI2 추론 챌린지(ARC) 벤치마크에서 다양한 언어 모델의 성능을 비교한 막대 그래프입니다. ARC는 초등학생 수준의 과학 문제를 해결하는 능력을 평가하는 벤치마크로, 모델의 추론 능력을 측정합니다. 그래프는 각 모델의 가중 F1 점수를 보여주며, Fietje 모델의 성능을 다른 모델들과 비교하여 Fietje의 추론 능력을 평가하는 데 사용되었습니다. 모델 이름과 가중 F1 점수 외에도 신뢰 구간이 표시되어 모델 성능의 불확실성을 나타냅니다.
read the caption
(a) ARC

🔼 그림 (b)는 네덜란드어 도서 리뷰 데이터 세트(DBRD)를 기반으로 한 감정 분석 결과를 보여줍니다. 이 그래프는 다양한 언어 모델의 성능을 비교하여 각 모델의 가중치 F1 점수와 95% 신뢰 구간을 보여줍니다. 이를 통해 모델의 감정 분석 정확도와 신뢰도를 평가할 수 있습니다. 모델의 크기, 출시일, 네덜란드어에 대한 특화 여부 등 다양한 요소가 감정 분석 성능에 어떻게 영향을 미치는지 확인할 수 있습니다.
read the caption
(b) DBRD

🔼 그림 (c)는 논문의 4.4절(결과)에서 다루는 벤치마크 결과 중 하나로, Dutch CoLA 데이터셋을 사용한 모델 평가 결과를 보여줍니다. Dutch CoLA는 네덜란드어 문법적 수용성을 평가하기 위한 데이터셋으로, 모델이 문법적으로 올바른 문장과 그렇지 않은 문장을 얼마나 잘 구분하는지 측정합니다. 이 그림은 다양한 크기와 출시 시점의 여러 언어 모델들의 성능을 비교하여, 모델의 크기와 출시 시점이 네덜란드어 문법적 수용성 평가에 어떤 영향을 미치는지 보여주는 시각 자료입니다.
read the caption
(c) Dutch CoLA

🔼 그림 (d)는 Global-MMLU 벤치마크 결과를 보여줍니다. Global-MMLU는 다양한 학문 분야(STEM, 인문학, 사회과학 등)의 지식을 평가하는 다중 과제 언어 이해 벤치마크입니다. 이 그림은 다양한 크기와 출시일을 가진 여러 언어 모델의 Global-MMLU 성능을 비교하여 모델의 지식 범위와 문제 해결 능력을 보여줍니다. 모델의 크기와 출시일이 성능에 미치는 영향을 분석하는 데 도움이 됩니다.
read the caption
(d) Global-MMLU

🔼 그림 (e)는 XLWIC 벤치마크 결과를 보여줍니다. XLWIC는 단어의 의미를 구분하는 작업(Word-in-Context)을 평가하는 벤치마크입니다. 이 그래프는 다양한 언어 모델의 XLWIC 성능을 비교하여 모델의 단어 의미 파악 능력을 보여줍니다. 특히, 이 그림에서는 네덜란드어에 특화된 모델과 다국어 모델의 성능을 비교 분석하여, 어떤 종류의 모델이 네덜란드어 단어 의미 구분 작업에서 더 나은 성능을 보이는지 보여줍니다.
read the caption
(e) XLWIC

🔼 그림 3은 논문에서 사용된 다섯 가지 벤치마크(ARC 추론, DBRD 감성 분석, Dutch CoLA 문법적 수용성, Global MMLU 언어 이해 및 세계 지식, XLWIC-NL 단어 의미 분석)별 모델 성능을 보여줍니다. 각 벤치마크에 대한 가중 F1 점수를 표시하며, 모델의 강점과 약점을 파악하는 데 도움이 됩니다. 예를 들어, Fietje의 instruct 및 chat 버전은 기본 모델보다 성능이 훨씬 뛰어나고 일부 벤치마크에서 더 큰 모델보다 성능이 더 우수함을 보여줍니다. 또한, 최신 모델이 이전 모델보다 성능이 뛰어나고 모델 크기가 성능을 결정하는 유일한 요소가 아님을 시사합니다.
read the caption
Figure 3: Results per benchmark

🔼 그림 4는 다섯 가지 벤치마크 작업(ARC, DBRD, Dutch CoLA, Global MMLU, XLWIC)에서 모델 크기에 따른 다양한 언어 모델의 성능을 보여줍니다. 각 그래프는 특정 벤치마크 작업에 대한 가중 F1 점수를 보여주며, x축은 모델 크기(십억 매개변수), y축은 가중 F1 점수를 나타냅니다. 모델의 크기와 성능 간의 상관관계를 명확히 보여주기 위한 시각자료입니다. 모델의 크기가 클수록 더 나은 성능을 보일 것이라는 기대와 달리, 일관된 추세는 관찰되지 않습니다.
read the caption
(a) ARC

🔼 그림 (b)는 네덜란드어 도서 리뷰 데이터셋(DBRD)에 대한 모델의 성능을 보여줍니다. DBRD는 네덜란드어로 된 도서 리뷰 2,224개를 긍정적 또는 부정적으로 레이블링한 감정 분석 데이터셋입니다. 이 그림은 각 모델이 DBRD에서 달성한 가중 F1 점수를 나타냅니다. 가중 F1 점수는 정밀도와 재현율의 조화 평균을 측정하는 지표로, 불균형 데이터셋에서 모델의 성능을 평가하는 데 효과적입니다. 그림은 다양한 크기와 출시일을 가진 여러 모델의 DBRD 성능을 비교하여 모델 크기와 성능 간의 관계, 모델 출시일과 성능 간의 관계 등을 분석하는 데 사용될 수 있습니다.
read the caption
(b) DBRD
🔼 그림 (c)는 네덜란드어 CoLA(Dutch CoLA) 벤치마크에 대한 모델 성능을 보여줍니다. 이 벤치마크는 문법적 수용성(grammatical acceptability)을 평가하는 데 사용되며, 문장이 문법적으로 올바른지(correct) 아닌지(incorrect)를 판단하는 모델의 능력을 측정합니다. 이 그림은 다양한 모델의 성능을 비교하여 네덜란드어 처리에 대한 각 모델의 강점과 약점을 보여줍니다.
read the caption
(c) Dutch CoLA

🔼 그림 4(d)는 Global-MMLU 벤치마크 결과를 보여줍니다. Global-MMLU는 다양한 학문 분야(STEM, 인문학, 사회 과학 등)에 걸친 광범위한 지식을 평가하는 다중 과제 언어 이해 벤치마크입니다. 이 그림에서는 여러 언어 모델의 Global-MMLU 성능을 가로축에 모델 크기(십억 매개변수), 세로축에 가중 F1 점수로 나타내어 비교합니다. 이를 통해 모델의 크기와 Global-MMLU 성능 간의 관계를 분석하고, 다양한 모델의 상대적인 성능을 파악할 수 있습니다. 각 점은 특정 언어 모델을 나타내며, 오차 막대는 신뢰 구간을 나타냅니다.
read the caption
(d) Global-MMLU

🔼 그림 (e)는 XLWIC 벤치마크 결과를 보여줍니다. XLWIC는 단어 의미 분류 작업을 평가하는 벤치마크입니다. 이 그림은 다양한 언어 모델의 XLWIC 성능을 비교하여 모델의 단어 의미를 이해하는 능력을 보여줍니다. 각 모델의 성능은 가로축에 표시되며, 모델의 크기는 세로축에 표시됩니다. 이 그림을 통해 모델 크기와 XLWIC 성능 간의 상관관계를 분석할 수 있습니다.
read the caption
(e) XLWIC

🔼 그림 4는 논문에서 다룬 모든 벤치마크에 대한 모델 크기별 성능을 보여줍니다. 모델의 크기가 클수록 성능이 좋을 것이라는 기대와 달리, 모델 크기와 성능 간의 상관관계는 명확하지 않습니다. 특히, 특정 언어에 최적화되지 않은 모델들(그림 4b)에서는 이러한 경향이 더욱 두드러집니다. 일부 소형 모델은 대형 모델보다 성능이 더 뛰어납니다. 이는 모델의 크기보다는 모델의 출시일, 즉 최신 모델이 더 나은 성능을 보이는 경향이 있음을 시사합니다. 각 벤치마크별 모델 크기 대비 성능을 자세히 살펴보려면 부록 D.1을 참조하십시오.
read the caption
Figure 4: Performance vs. size across all benchmarks

🔼 그림 (a)는 AI2 추론 챌린지(ARC) 벤치마크에 대한 모델 성능을 보여줍니다. ARC는 다양한 추론 능력을 평가하기 위해 초등학생 수준의 과학 문제를 사용합니다. 이 그림은 다양한 크기와 출시일을 가진 여러 언어 모델의 ARC 점수를 비교하여, 모델의 크기가 항상 성능과 비례하지 않음을 보여줍니다. 일부 소형 모델은 더 큰 모델보다 더 나은 성능을 보여주는 경우도 있습니다. 이는 모델 아키텍처, 훈련 데이터, 그리고 언어 모델의 지속적인 발전을 반영합니다.
read the caption
(a) ARC
Full paper#



















