↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
멀티모달 대규모 언어 모델(MLLM)은 복잡한 추론 문제를 해결하는 데 어려움을 겪고 있습니다. 기존의 빔 서치 방식은 다양한 모달리티 간의 상호작용을 효과적으로 처리하지 못하며, 추론 과정의 신뢰성과 정확성을 저해할 수 있습니다. 또한, 기존의 보상 모델은 결과에 대한 피드백만 제공하여 세부적인 추론 과정을 검증하는 데 한계가 있습니다.
본 논문에서는 이러한 문제를 해결하기 위해 능동적 검색(AR)과 몬테 카를로 트리 탐색(MCTS)을 결합한 새로운 프레임워크인 AR-MCTS를 제안합니다. AR-MCTS는 멀티모달 데이터셋에서 추론에 필요한 정보를 능동적으로 검색하고, MCTS 알고리즘을 통해 단계별로 추론 과정을 검증합니다. 실험 결과, AR-MCTS는 다양한 멀티모달 모델의 성능을 향상시키고, 추론 과정의 정확성과 신뢰성을 높이는 것으로 나타났습니다. 특히, 복잡한 추론 문제에 대한 처리 능력을 향상시키고, 샘플링의 다양성과 정확성을 최적화하여 안정적인 멀티모달 추론을 가능하게 합니다.
Key Takeaways#
Why does it matter?#
본 논문은 다단계 추론 과정에서의 신뢰성 문제를 해결하기 위해 능동적 검색과 몬테 카를로 트리 탐색을 결합한 새로운 프레임워크인 AR-MCTS를 제시합니다. 이는 다양한 모달리티를 가진 복잡한 추론 문제에 효과적으로 적용될 수 있으며, 추론 과정의 투명성 및 신뢰성을 높이는 데 크게 기여합니다. 또한, 다양한 벤치마크에서 기존 방법들을 능가하는 성능을 보임으로써, 다양한 분야의 연구자들에게 중요한 시사점을 제공합니다. 특히, 멀티모달 분야의 연구자들에게는 새로운 추론 프레임워크를 제공하고, 효율적인 샘플링 전략을 통해 추론 성능을 향상시킬 수 있는 실질적인 방법을 제시합니다.
Visual Insights#

🔼 본 논문의 그림 1은 멀티모달 추론을 위한 하이브리드 모달 검색 풀의 통계를 보여줍니다. 그림에는 다양한 데이터 소스(위키피디아 영어/중국어 버전, COIG, GSM8K, MATH, MATHVISTA, MathVerse, MathVision, WE-MATH)에서 수집한 데이터의 개수와 비율이 표시되어 있습니다. 이는 텍스트 기반 데이터와 멀티모달 데이터(텍스트와 이미지)의 양적 비율을 보여주어, 검색 풀의 구성과 규모를 정확히 파악하는 데 도움이 됩니다. 특히, 수학 관련 추론 데이터와 일반 추론 데이터의 비중을 비교하여, 본 연구에서 사용된 검색 풀의 특징을 효과적으로 설명합니다.
read the caption
Figure 1: The statistics of our hybrid-modal retrieval corpus.
🔼 표 1은 MathVista와 We-Math 테스트 mini 세트를 사용하여 다양한 다중 모드 대규모 언어 모델(MLLM)의 수학적 추론 성능을 평가한 결과를 보여줍니다. MathVista의 경우 원래 12개 범주 중 6개(전체 정확도, 기하 문제 해결, 수학 어휘 문제, 대수적 추론, 기하 추론, 통계적 추론)를 선택했고, We-Math의 경우 8개 범주(1단계 문제, 2단계 문제, 3단계 문제, 평균 점수, 지식 부족, 일반화 부족, 완벽한 숙달, 암기)를 선택했습니다. 각 모델의 최고 점수는 굵게 표시되어 있습니다. 이 표는 다양한 MLLM의 수학적 추론 능력을 비교 분석하는 데 유용하게 활용될 수 있습니다.
read the caption
Table 1: Mathematical reasoning assessment on different MLLMs using MathVista and We-Math testmini Sets. In the case of MathVista, we picked 6 categories from the original 12: ALL (overall accuracy), GPS (geometry problem solving), MWP (math word problems), ALG (algebraic reasoning), GEO (geometry reasoning), and STA (statistical reasoning). For We-Math, we selected 8 categories: S1 (one-step problems), S2 (two-step problems), S3 (three-step problems), AVG (strict overall average scores), IK (insufficient knowledge), IG (inadequate generalization), CM (complete mastery), and RM (rote memorization). The top scores for each model are highlighted in bold.
In-depth insights#
Active Retrieval MCTS#
능동적 검색 MCTS는 다단계 추론 과정에서 필요한 정보를 동적으로 검색하여 활용하는 새로운 접근 방식입니다. 기존의 MCTS 알고리즘을 확장하여 각 추론 단계마다 관련 정보를 검색하고, 이를 활용하여 추론 경로를 생성하고 평가합니다. 이는 추론의 정확성과 다양성을 향상시키는 데 중요한 역할을 합니다. 기존의 빔 서치 기반 접근 방식보다 다양하고 신뢰할 수 있는 추론 공간을 제공합니다. 또한, 단계별 보상 모델을 통해 추론 과정을 자동으로 검증할 수 있어, 멀티모달 추론의 신뢰성을 높입니다. 능동적 검색 MCTS는 멀티모달 대규모 언어 모델의 추론 능력을 향상시키는 데 효과적이며, 특히 복잡한 추론 문제 해결에 유용합니다. 하이브리드 모달 검색 코퍼스를 통해 다양한 정보원을 활용하고, MCTS 알고리즘과 능동적 검색 메커니즘을 결합함으로써 다양한 추론 경로를 생성하고 평가할 수 있게 합니다. 하지만, 계산 비용이 높아질 수 있다는 점과 검색된 정보의 질에 대한 의존성이 크다는 점은 향후 연구에서 개선되어야 할 부분입니다.
Hybrid Corpus Use#
본 논문에서 제시된 핵심 개념인 ‘하이브리드 말뭉치 활용’은 다양한 모달리티(텍스트, 이미지)의 데이터를 통합하여 활용하는 전략을 의미합니다. 이는 단일 모달리티에 의존하는 기존 방식의 한계를 극복하고, 보다 풍부하고 정확한 추론을 가능하게 하는 혁신적인 접근 방식입니다. 텍스트 기반의 지식과 이미지 기반의 지식을 결합함으로써, 모델이 더욱 포괄적인 정보에 접근하고, 복잡한 추론 문제를 해결하는 능력을 향상시킬 수 있습니다. 특히, 수학적 추론과 같은 복잡한 문제에 있어서, 하이브리드 말뭉치의 활용은 다양한 모달리티 간의 상호작용 및 관계를 파악하고, 해결 과정을 보다 명확하게 제시하는 데 효과적입니다. 이러한 하이브리드 접근 방식은 기존의 텍스트 전용 또는 이미지 전용 접근 방식보다 훨씬 높은 성능을 달성할 가능성이 높습니다. 하지만, 하이브리드 말뭉치 구축 및 관리의 어려움, 다양한 모달리티 데이터 간의 호환성 문제와 같은 과제들을 해결해야 하는 것이 중요합니다. 본 논문은 이러한 과제를 효과적으로 해결하는 방법을 제시하고, 하이브리드 말뭉치 활용을 통한 멀티모달 추론 성능 향상을 실험적으로 증명합니다.
Multimodal Reasoning#
다양한 모드(텍스트, 이미지, 오디오 등)의 정보를 통합하여 추론하는 멀티모달 추론은 인공지능 분야의 중요한 과제입니다. 본 논문에서는 멀티모달 추론의 어려움과 한계를 극복하기 위한 혁신적인 방법들을 제시하고 있습니다. 특히, **능동적 검색(Active Retrieval)**과 **몬테 카를로 트리 탐색(Monte Carlo Tree Search)**을 결합하여 모델의 추론 능력을 향상시키는 프레임워크를 제안합니다. 이는 단순히 기존의 빔 서치 방식을 넘어, 추론 과정의 각 단계마다 필요한 정보를 능동적으로 검색하고 활용함으로써 추론 과정의 다양성과 신뢰성을 높이는 데 기여합니다. 또한, **단계별 보상 모델(Process Reward Model)**을 도입하여 추론 과정을 자동으로 검증하고, 모델의 추론 성능을 향상시키는 방법을 제시합니다. 실험 결과는 제안된 프레임워크의 우수성을 다양한 벤치마크에서 확인하며, 특히 복잡한 멀티모달 추론 과제에서 뛰어난 성능을 보입니다. 하지만, 계산 비용 최적화 및 멀티모달 모델 기반의 PRM 개선 등은 향후 연구 과제로 남아있습니다.
PRM Optimization#
본 논문에서 PRM(Process Reward Model) 최적화는 다단계 추론 과정의 신뢰성을 높이는 핵심 전략입니다. 단순히 결과만 평가하는 기존의 ORM(Outcome Reward Model)과 달리, PRM은 추론의 각 단계별로 보상을 제공, 더욱 세분화된 피드백을 통해 모델의 추론 능력을 향상시킵니다. 이를 위해 논문에서는 **능동적 검색(Active Retrieval)**과 MCTS(Monte Carlo Tree Search) 알고리즘을 결합한 AR-MCTS 프레임워크를 제시합니다. 능동적 검색은 각 단계마다 필요한 정보를 효율적으로 검색, 추론 과정의 다양성과 신뢰성을 높이고, MCTS는 다양한 경로를 탐색하여 최적의 추론 경로를 찾습니다. 단계별 보상 모델은 DPO(Direct Preference Optimization)와 SFT(Supervised Fine-tuning)를 통해 점진적으로 학습, 모델의 추론 능력을 지속적으로 개선합니다. 단계별 주석을 자동으로 생성, 인간의 개입 없이도 신뢰할 수 있는 다단계 추론을 가능하게 합니다. 결과적으로 PRM 최적화는 추론의 정확성과 효율성을 향상시켜, 다양한 다중 모드 모델의 성능을 개선하는 데 크게 기여합니다.
Future Work#
본 논문은 능동적 검색과 몬테 카를로 트리 탐색을 이용한 점진적 다중 모드 추론 프레임워크인 AR-MCTS를 제시합니다. 향후 연구 방향으로는 계산 비용 최적화를 위한 효율적인 기법 탐색, 다중 모드 모델 기반 PRM의 심층 통합을 통한 이미지와 텍스트 간 상호작용 강화, 검색 및 추론의 심층 통합을 통한 효율적인 추론 시스템 구축 등이 제시될 수 있습니다. 특히, 다중 모달 모델에서의 피드백 기반 동적 지식 보충 연구는 중요한 과제입니다. 다양한 다중 모달 데이터셋에 대한 적용성 검증 또한 중요한 후속 연구 과제가 될 것입니다. AR-MCTS의 확장성 및 일반화 능력을 높이는 연구와 함께 다양한 추론 과제에 대한 적용 가능성을 탐구하는 것도 중요합니다. 실제 응용 분야에서의 AR-MCTS 활용 방안 모색을 통해 연구의 실용성을 높일 수 있을 것입니다.
More visual insights#
More on figures

🔼 그림 2는 논문에서 제안하는 통합 다중 모드 검색 모듈의 파이프라인을 보여줍니다. 다중 모드 질의(텍스트와 이미지)가 입력되면, 텍스트 전용 코퍼스와 다중 모드 코퍼스로부터 관련 정보를 검색하는 두 가지 검색 과정이 수행됩니다. 텍스트 검색은 텍스트 기반의 질의에 대해서만 작동하며, 다중 모드 검색은 텍스트와 이미지를 모두 고려합니다. 검색된 정보는 지식 개념 필터링 모듈을 거쳐, 질의와 관련된 핵심 정보만 추출됩니다. 최종적으로 추출된 핵심 정보는 다운스트림 작업에 사용됩니다. 이 그림은 다중 모달 질의에 대한 핵심 정보를 효율적이고 정확하게 검색하는 모듈의 구조를 자세히 설명합니다.
read the caption
Figure 2: The pipeline of our unified multimodal retrieval module.

🔼 그림 3은 본 논문에서 제안하는 AR-MCTS 프레임워크의 전체적인 구조를 보여줍니다. AR-MCTS는 먼저 통합된 검색 모듈을 사용하여 MCTS 프로세스의 각 단계에서 관련 정보를 검색합니다. 검색된 정보는 MCTS의 상태를 강화하여 MLLM의 가능한 동작 공간을 확장하는 데 사용됩니다. 특히, 그림에 나와있는 S1,3 및 S2,3과 같이 각 단계의 특정 상태에서는 추가적인 정보가 제공되지 않고, MLLM의 직접적인 출력으로 상태가 결정되는 경우도 있습니다. 즉, AR-MCTS는 단순히 정보를 추가하는 것이 아니라 MCTS의 각 단계에서 필요한 정보를 동적으로 검색하고 활용하여 MLLM의 추론 능력을 향상시키는 것을 목표로 합니다. 이 그림은 AR-MCTS의 작동 방식을 시각적으로 이해하는 데 도움을 줍니다.
read the caption
Figure 3: The overall framework of AR-MCTS: The retrieval module actively retrieves key insights at each step of the MCTS process. Then, the states of the MCTS is enhanced with different insights to expand the possible action space of the MLLM. Notably, one state of each step, such as state S1,3superscript𝑆13S^{1,3}italic_S start_POSTSUPERSCRIPT 1 , 3 end_POSTSUPERSCRIPT and S2,3superscript𝑆23S^{2,3}italic_S start_POSTSUPERSCRIPT 2 , 3 end_POSTSUPERSCRIPT in this figure, no insights are provided, and the state is a direct output of the MLLM.
🔼 그림 4는 추론 샘플링에 대한 스케일링 분석 결과를 보여줍니다. x축은 문제당 샘플링되는 솔루션의 수(1~32개)를 나타내고, y축은 정확도를 나타냅니다. ‘Random Choice’는 1부터 32까지 무작위로 샘플링했을 때의 평균 정확도를 의미합니다. 각 그래프는 서로 다른 방법(Random Choice, Self-Consistency, ORM, AR-MCTS)을 사용했을 때 세 가지 벤치마크(MATHVISTA 전체, We-Math S1, We-Math S3)에서의 정확도 변화를 보여줍니다. 이 그림을 통해 AR-MCTS가 샘플링 수가 증가함에 따라 더 나은 성능을 보이며 다른 방법들보다 우수한 성능을 보임을 확인할 수 있습니다.
read the caption
Figure 4: Scaling analysis on inference samplings. Random Choice denotes the average result of randomly sampling from 1 to 32.

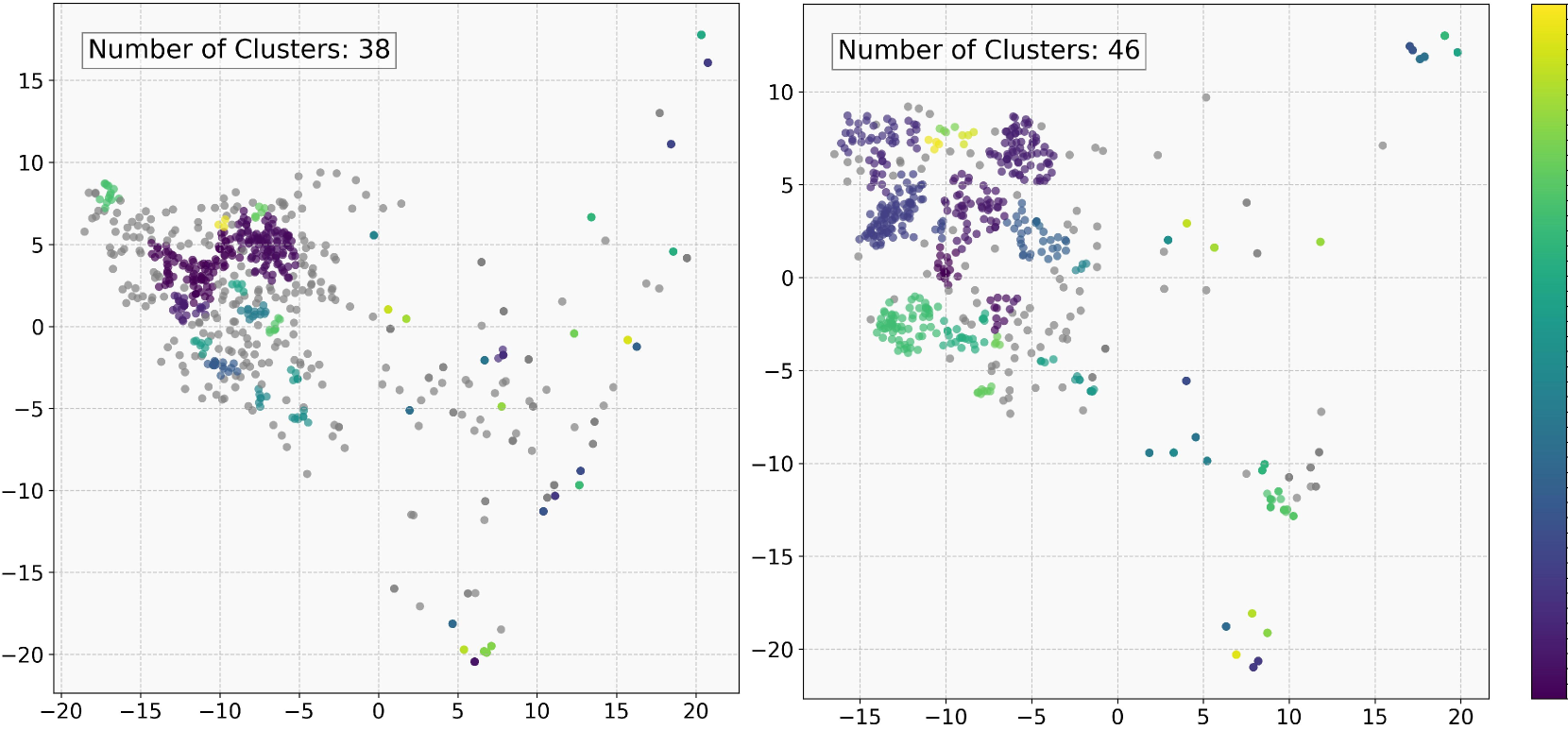
🔼 그림 5는 다양한 모델에서 생성된 후보 추론 경로들을 시각화한 것입니다. 각 점은 하나의 추론 경로를 나타내며, 색상은 사용된 모델 또는 방법론(예: Beam Search, AR-MCTS)을 나타냅니다. 점들의 분포는 추론 경로의 다양성을 보여줍니다. 밀집되어 있는 경우는 다양성이 낮고, 넓게 분포되어 있는 경우 다양성이 높음을 의미합니다. 이 그림은 AR-MCTS가 기존의 Beam Search에 비해 더 다양한 추론 경로들을 생성함을 보여주는 증거로 제시되었습니다. 이는 AR-MCTS의 활성 검색(Active Retrieval) 메커니즘이 추론 과정의 다양성을 개선하는 데 효과적임을 시각적으로 보여줍니다.
read the caption
Figure 5: The visualization of the cadidate reasoning paths.
More on tables
| Model | Method | Overall | Mathematics | Chinese | Physics | Chemistry | Biology | History | Geography | Politics |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | Zero-shot | 45.6 | 50.0 | 33.0 | 9.6 | 35.7 | 50.0 | 60.0 | 73.1 | 100.0 |
| Self-Consistency | 47.8 | 50.0 | 33.0 | 13.5 | 42.9 | 50.0 | 60.0 | 73.1 | 100.0 | |
| AR-MCTS | 52.2 | 62.5 | 33.3 | 21.2 | 42.9 | 50.0 | 80.0 | 73.1 | 100.0 | |
| Qwen2-VL-7B | Zero-shot | 30.2 | 25.0 | 33.3 | 21.2 | 42.9 | 50.0 | 40.0 | 26.9 | 40.0 |
| Self-Consistency | 33.0 | 50.0 | 33.0 | 15.4 | 50.0 | 25.0 | 20.0 | 38.5 | 40.0 | |
| AR-MCTS | 37.4 | 37.5 | 33.3 | 19.2 | 35.7 | 50.0 | 40.0 | 46.2 | 80.0 |
🔼 표 2는 중국 대입 시험인 GAOKAO의 다중 모드 문제 풀이 데이터셋(GAOKAO-MM)을 사용하여 다양한 다중 모드 대규모 언어 모델(MLLM)의 성능을 비교 분석한 표입니다. 다양한 MLLM 모델들에 대해 GAOKAO-MM 데이터셋에서의 전반적인 성능(총점), 수학, 중국어, 물리, 화학, 생물, 역사, 지리, 정치 과목별 정확도를 보여줍니다. 각 모델의 최고 점수는 굵은 글씨체로 강조 표시되어 있습니다. 이 표는 AR-MCTS 프레임워크의 일반적인 추론 능력 향상 효과를 다양한 과목에 걸쳐 평가하는 데 사용됩니다.
read the caption
Table 2: The Performance of MLLMs on GAOKAO-MM. The top scores for each model are highlighted in bold.
| Models | MathVista (ALL) | We-Math (S3) | GAOKAO-MM(ALL) |
|---|---|---|---|
| AR-MCTS | 64.1 | 40.6 | 37.4 |
| w/o PRM | 61.0 (-3.1) | 37.7 (-2.9) | 33.2 (-4.2) |
| w/o Filtering | 62.8 (-1.3) | 39.5 (-1.1) | 34.5 (-2.9) |
| w/o Active Retrieval | 61.9 (-2.2) | 38.7 (-1.9) | 33.4 (-4.0) |
🔼 이 표는 Qwen2-7B 모델을 사용하여 다양한 구성 요소를 제거했을 때의 성능 변화를 보여주는 ablation study 결과를 나타냅니다. AR-MCTS 프레임워크의 각 구성 요소(PRM, 필터링, 능동적 검색)가 모델의 성능에 미치는 영향을 정량적으로 분석합니다. 각 구성 요소를 제거했을 때의 MATHVISTA(ALL), WE-MATH(S3), GAOKAO-MM(ALL) 세 가지 벤치마크에서의 성능 저하 정도를 수치로 제시하여 각 구성 요소의 중요성을 강조합니다.
read the caption
Table 3: Ablation study with Qwen2-7B. 'Filtering' denotes the knowledge concept filtering module.
| Dataset | Count | Percentage |
|---|---|---|
| Wikipedia(zh-CN) | 4.7B | 23.9% |
| Wikipedia(en-US) | 15B | 73.6% |
| COIG | 178K | 0.1% |
🔼 본 표는 논문의 4장, 방법론 섹션에 포함되어 있으며, 일반적인 추론 지식의 통계 정보를 보여줍니다. 세부적으로는 Wikipedia(중국어), Wikipedia(영어), COIG 데이터셋의 각 데이터 수와 전체 데이터셋에서 차지하는 비율을 나타냅니다. 이 표는 본 논문에서 사용된 하이브리드 모달 검색 코퍼스의 구성 요소를 보여주는 데 도움이 됩니다.
read the caption
Table 4: The statistics of General Reasoning Knowledge.
| Dataset | Count | Percentage |
|---|---|---|
| Text-only Datasets | ||
| GSM8K | 8,792 | 24.6% |
| MATH | 12,500 | 36.2% |
| Multimodal Datasets | ||
| MathVista | 6,141 | 17.8% |
| MathVerse | 2,612 | 7.6% |
| MathVision | 3,040 | 8.8% |
| We-Math | 1,740 | 5.0% |
🔼 표 5는 논문에서 사용된 수학적 추론 데이터셋의 통계를 보여줍니다. 본 표는 본 논문의 실험에 사용된 다양한 종류의 수학적 추론 데이터셋의 크기와 비율을 제시하며, 특히 텍스트 기반 데이터셋과 멀티모달 데이터셋을 구분하여 각 데이터셋의 구성 비율을 명확히 보여줍니다. 이는 다양한 데이터셋의 통계적 특징을 파악하는 데 도움이 되어, 실험 결과의 해석 및 모델 성능 비교에 유용한 정보를 제공합니다.
read the caption
Table 5: The statistics of Mathematics-Specific Reasoning Knowledge.
| Model | Method | ALL | GPS | MWP | ALG | GEO | STA |
|---|---|---|---|---|---|---|---|
| GPT-4V | Zero-shot | 53.7 | 59.6 | 53.8 | 59.8 | 58.2 | 58.5 |
| Self-Consistency | 56.2 | 65.4 | 53.2 | 63.7 | 63.2 | 58.8 | |
| Self-Correction | 50.4 | 56.3 | 50.2 | 55.9 | 56.1 | 57.4 | |
| ORM | 56.6 | 65.3 | 53.1 | 65.2 | 63.2 | 59.0 | |
| AR-MCTS | 57.4 | 66.1 | 53.9 | 64.8 | 63.2 | 59.5 | |
| LLaVA-NEXT | Zero-shot | 22.5 | 22.3 | 13.4 | 24.4 | 24.7 | 22.3 |
| Self-Consistency | 23.1 | 22.6 | 16.7 | 26.0 | 24.3 | 24.3 | |
| Seld-Correction | 22.5 | 22.6 | 17.2 | 24.9 | 22.6 | 25.2 | |
| ORM | 24.4 | 22.6 | 17.5 | 27.9 | 24.3 | 29.9 | |
| AR-MCTS | 25.6 | 23.0 | 17.4 | 28.1 | 28.6 | 31.5 |
🔼 표 6은 MathVista 테스트 mini 세트에 대한 수학적 평가 결과를 보여줍니다. MathVista의 원래 12개 수학 범주 중 6개(전체 정확도, 기하 문제 해결, 수학 용어 문제, 대수적 추론, 기하 추론, 통계적 추론)를 선택했습니다. 각 모델의 결과에서 가장 높은 정확도 점수는 굵게 표시되어 있습니다. 이 표는 다양한 모델과 방법(제로샷, 자기 일관성, 자기 수정, ORM, AR-MCTS)의 성능을 비교하여 MathVista 데이터셋에서의 다양한 모델의 수학적 추론 능력을 평가합니다.
read the caption
Table 6: Mathematical evaluation on MathVista testmini sets. We select 6 out of the original 12 mathematical categories in MathVista: ALL (overall accuracy), GPS (geometry problem solving), MWP (math word problems), ALG (algebraic reasoning), GEO (geometry reasoning), and STA (statistical reasoning). In the results for each model, the best accuracy scores are highlighted in bold.
| Dataset | MathVista | We-Math |
|---|---|---|
| Text-only Datasets | ||
| COIG | 0.1% | 0.1% |
| Wikipedia(en-US) | 0.6% | 1.1% |
| GSM8K | 4.5% | 2.0% |
| MATH | 4.5% | 1.8% |
| Multimodal Datasets | ||
| MathVerse | 0.7% | 2.9% |
| MathVision | 0.3% | 0.9% |
| We-Math | 0.5% | - |
| MathVista-testmini | - | 4.2% |
🔼 표 7은 하이브리드 모달 검색 풀에서 데이터 오염 분석 결과를 보여줍니다. 본 논문에서는 하이브리드 모달 검색 풀(텍스트 전용 데이터셋과 멀티모달 데이터셋의 결합)을 사용하며, 테스트 세트와의 데이터 중복을 방지하기 위해 오염 분석을 수행합니다. 표는 다양한 데이터 소스에서 가져온 상위 50개의 검색 결과와 테스트 세트 간의 중복 정도(n-gram threshold 13 사용)를 백분율로 나타냅니다. 이 분석을 통해 테스트 세트와 검색 풀 간의 데이터 오염이 거의 없음을 확인합니다.
read the caption
Table 7: The contamination analysis on hybrid-modal retrieval corpus.
| Model | ALL | GPS | MWP | ALG | GEO | STA |
|---|---|---|---|---|---|---|
| Qwen2-VL-7B | 58.8 | 45.5 | 60.5 | 45.5 | 47.9 | 70.8 |
| + BM25 | 60.2 | 54.8 | 57.9 | 53.3 | 54.6 | 72.1 |
| + Contriever | 59.9 | 53.9 | 58.5 | 53.3 | 54.1 | 72.4 |
🔼 본 표는 다양한 text retriever를 사용했을 때의 실험 결과를 보여줍니다. 구체적으로는, Qwen2-VL-7B 모델을 기반으로 BM25와 Contriever라는 두 가지 text retriever를 사용하여 MATHVISTA 데이터셋에 대한 실험을 진행하였습니다. 각 retriever를 사용했을 때의 전체 정확도(ALL), 기하 문제 풀이(GPS), 수학적 단어 문제(MWP), 대수적 추론(ALG), 기하 추론(GEO), 통계적 추론(STA) 성능을 비교 분석하여, 어떤 text retriever가 multimodal reasoning 성능 향상에 더 효과적인지 보여줍니다. 표의 수치는 해당 지표에 대한 정확도(%)를 나타냅니다.
read the caption
Table 8: The ablations of different text retrievers.
| Model | S1 | S2 | S3 |
|---|---|---|---|
| Qwen2-VL-7B | 53.4 | 37.2 | 33.9 |
| + CLIP-ViT-L/14 | 54.9 | 38.7 | 34.5 |
| + Jina-CLIP-v1 | 54.4 | 36.9 | 34.1 |
🔼 본 표는 다양한 다중 모드 검색 기법을 사용했을 때의 성능 차이를 보여줍니다. 특히, Qwen2-VL-7B 모델을 기준으로, CLIP-ViT-L/14 및 Jina-CLIP-v1과 같은 다중 모드 검색 방법을 추가했을 때의 WE-MATH 데이터셋(S1, S2, S3)에 대한 성능 변화를 보여줍니다. 각 검색 방법의 추가가 모델의 추론 성능에 미치는 영향을 정량적으로 비교 분석하여, 어떤 다중 모드 검색 방법이 가장 효과적인지를 제시합니다.
read the caption
Table 9: The ablations of different multimodal retrievers.
| Model | ALL | GPS | MWP | ALG | GEO | STA |
|---|---|---|---|---|---|---|
| PRM (Hard) | 62.9 | 63.3 | 71.5 | 59.4 | 62.2 | 71.0 |
| PRM (Soft) | 64.1 | 63.9 | 72.6 | 60.9 | 63.6 | 72.4 |
🔼 표 10은 다양한 PRM(Process Reward Model) 학습 목표의 성능 비교 결과를 보여줍니다. ‘PRM(Hard)‘는 하드 레이블을 사용한 PRM 학습 결과를, ‘PRM(Soft)‘는 소프트 레이블을 사용한 PRM 학습 결과를 나타냅니다. 각각의 방법에 대한 MATHVISTA 데이터셋에서의 전체 정확도(ALL) 및 하위 범주별(GPS, MWP, ALG, GEO, STA) 성능이 제시되어 있습니다. 이 표는 소프트 레이블을 사용한 PRM 학습이 하드 레이블을 사용한 학습보다 더 나은 성능을 보임을 보여주는 실험 결과를 요약한 것입니다.
read the caption
Table 10: The comparison of different training objectives for PRMs.
Full paper#



















