↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
최근 **다중 모드 대규모 언어 모델(MLLM)**이 다양한 분야에서 괄목할 만한 성과를 거두고 있지만, 시각-공간 지능은 아직 미개척 분야로 남아 있습니다. 기존의 연구들은 주로 정지된 이미지를 사용하여 시각-공간 지능을 평가했지만, 실제 환경에서는 시간에 따른 변화를 포착하는 것이 중요합니다. 따라서, 동영상 데이터를 활용한 시각-공간 지능 평가의 필요성이 대두되고 있습니다.
본 연구에서는 MLLM의 시각-공간 지능을 평가하기 위한 새로운 비디오 기반 벤치마크인 VSI-Bench를 제시합니다. VSI-Bench는 다양한 실내 환경에서 촬영된 5,000개 이상의 질문-답변 쌍을 포함하며, 객체 계수, 상대 거리, 방향, 크기, 경로 계획 등 다양한 시각-공간 지능 과제를 다룹니다. 연구진은 VSI-Bench를 이용하여 다양한 MLLM 모델을 평가하고, 그 결과를 분석하여 MLLM의 시각-공간 지능의 강점과 약점을 밝혔습니다. 특히, 기존의 언어적 추론 기법은 성능 향상에 도움이 되지 않지만, 인지 지도 생성을 통해 공간적 거리 추론 능력이 향상됨을 발견하였습니다.
Key Takeaways#
Why does it matter?#
본 논문은 **다중 모드 대규모 언어 모델(MLLM)**의 공간 지각 능력을 평가하기 위한 새로운 벤치마크인 VSI-Bench를 제시하고, MLLM이 공간을 어떻게 이해하고 기억하는지에 대한 심층적인 분석을 제공합니다. 이는 로봇 공학, 자율 주행, 증강 현실/가상 현실 분야에서의 잠재적 응용과 더불어 시각-공간 지능 연구에 중요한 영향을 미칩니다. 또한, 제시된 벤치마크와 분석 방법은 향후 연구자들의 시각-공간 지능 연구에 귀중한 자료가 될 것입니다.
Visual Insights#

🔼 그림 1은 시각적 공간 지능의 핵심 요소인 공간 인지, 공간 배치 기억, 그리고 요구시 공간 정보를 떠올려 질문에 답하는 능력을 보여줍니다. 최근 다중 모드 거대 언어 모델(Multimodal LLMs)은 일반적인 비디오를 이해할 수 있지만, 환경의 비디오 녹화를 보여주면 ‘공간적으로 생각’할 수 있을까요? 모델이 공간에 대한 질문에 답할 수 있도록 정확하고 암묵적인 ‘인지 지도(cognitive map)‘를 만들 수 있을까요? 그리고 공간 지능을 향상시키기 위해 다중 모드 거대 언어 모델을 사용하는 것의 강점과 한계는 무엇일까요? 본 논문에서는 다중 모드 거대 언어 모델이 시청할 비디오 데이터를 설정하고, 모델의 기억을 확인하기 위한 VQA 벤치마크를 구축하고, 다중 모드 거대 언어 모델이 실제로 무엇을 기억하고 이해하는지 조사함으로써 이러한 질문들을 탐구합니다.
read the caption
Figure 1: Whether at home, in the workplace, or elsewhere, the ability to perceive a space, remember its layout, and retrieve this spatial information to answer questions on demand is a key aspect of visual-spatial intelligence. Recent Multimodal LLMs can understand general videos, but can they “think spatially” when presented with a video recording of an environment? Can they build an accurate, implicit “cognitive map” that allows them to answer questions about a space? What are the strengths and limitations of using MLLMs to enhance spatial intelligence? We dig into these questions by setting up video data for MLLMs to watch, building a VQA benchmark to check their recall, and examining what the MLLMs actually remember and understand.
| Methods | Rank | Avg. | Obj. Count | Abs. Dist. | Obj. Size | Room Size | Rel. Dist. | Rel. Dir. | Route Plan | Appr. Order |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | ||||||||||
| Chance Level (Random) | - | - | - | - | - | - | 25.0 | 36.1 | 28.3 | 25.0 |
| Chance Level (Frequency) | - | 34.0 | 62.1 | 32.0 | 29.9 | 33.1 | 25.1 | 47.9 | 28.4 | 25.2 |
| VSI-Bench (tiny) Perf. | ||||||||||
| Human Level† | - | 79.2 | 94.3 | 47.0 | 60.4 | 45.9 | 94.7 | 95.8 | 95.8 | 100.0 |
| Gemini-1.5 Flash† | - | 45.7 | 50.8 | 33.6 | 56.5 | 45.2 | 48.0 | 39.8 | 32.7 | 59.2 |
| Gemini-1.5 Pro† | - | 48.8 | 49.6 | 28.8 | 58.6 | 49.4 | 46.0 | 48.1 | 42.0 | 68.0 |
| Gemini-2.0 Flash† | - | 45.4 | 52.4 | 30.6 | 66.7 | 31.8 | 56.0 | 46.3 | 24.5 | 55.1 |
| Proprietary Models (API) | ||||||||||
| GPT-4o | 3 | 34.0 | 46.2 | 5.3 | 43.8 | 38.2 | 37.0 | 41.3 | 31.5 | 28.5 |
| Gemini-1.5 Flash | 2 | 42.1 | 49.8 | 30.8 | 53.5 | 54.4 | 37.7 | 41.0 | 31.5 | 37.8 |
| Gemini-1.5 Pro | 1 | 45.4 | 56.2 | 30.9 | 64.1 | 43.6 | 51.3 | 46.3 | 36.0 | 34.6 |
| Open-source Models | ||||||||||
| InternVL2-2B | 11 | 27.4 | 21.8 | 24.9 | 22.0 | 35.0 | 33.8 | 44.2 | 30.5 | 7.1 |
| InternVL2-8B | 5 | 34.6 | 23.1 | 28.7 | 48.2 | 39.8 | 36.7 | 30.7 | 29.9 | 39.6 |
| InternVL2-40B | 3 | 36.0 | 34.9 | 26.9 | 46.5 | 31.8 | 42.1 | 32.2 | 34.0 | 39.6 |
| LongVILA-8B | 12 | 21.6 | 29.1 | 9.1 | 16.7 | 0.0 | 29.6 | 30.7 | 32.5 | 25.5 |
| VILA-1.5-8B | 9 | 28.9 | 17.4 | 21.8 | 50.3 | 18.8 | 32.1 | 34.8 | 31.0 | 24.8 |
| VILA-1.5-40B | 7 | 31.2 | 22.4 | 24.8 | 48.7 | 22.7 | 40.5 | 25.7 | 31.5 | 32.9 |
| LongVA-7B | 8 | 29.2 | 38.0 | 16.6 | 38.9 | 22.2 | 33.1 | 43.3 | 25.4 | 15.7 |
| LLaVA-NeXT-Video-7B | 4 | 35.6 | 48.5 | 14.0 | 47.8 | 24.2 | 43.5 | 42.4 | 34.0 | 30.6 |
| LLaVA-NeXT-Video-72B | 1 | 40.9 | 48.9 | 22.8 | 57.4 | 35.3 | 42.4 | 36.7 | 35.0 | 48.6 |
| LLaVA-OneVision-0.5B | 10 | 28.0 | 46.1 | 28.4 | 15.4 | 28.3 | 28.9 | 36.9 | 34.5 | 5.8 |
| LLaVA-OneVision-7B | 6 | 32.4 | 47.7 | 20.2 | 47.4 | 12.3 | 42.5 | 35.2 | 29.4 | 24.4 |
| LLaVA-OneVision-72B | 2 | 40.2 | 43.5 | 23.9 | 57.6 | 37.5 | 42.5 | 39.9 | 32.5 | 44.6 |
🔼 표 2는 VideoMME라는 비디오 이해 벤치마크의 500개 질문 하위 집합에 대한 Gemini-1.5 Pro 모델의 Chain-of-Thought(CoT) 프롬프팅 성능을 보여줍니다. CoT 프롬프팅을 사용했을 때와 사용하지 않았을 때의 성능 차이를 보여주어, CoT 프롬프팅이 VideoMME 작업에서 Gemini-1.5 Pro 모델의 성능 향상에 미치는 영향을 평가하는 데 도움이 됩니다.
read the caption
Table 1: Gemini-1.5 Pro CoT performance on a 500-questions subset in VideoMME.
In-depth insights#
Spatial Intelligence#
본 논문에서 논의된 공간 지능에 대한 심층적인 생각은 다양한 모달리티(시각, 언어)를 통합하는 대규모 언어 모델(MLLM)의 공간적 사고 능력에 초점을 맞춥니다. 인간의 공간 지능은 단순히 공간적 정보를 인지하는 것을 넘어, 공간적 관계를 이해하고 조작하는 능력을 포함합니다. MLLM은 비디오 데이터를 통해 공간을 학습하지만, 인간 수준의 공간 지능에는 미치지 못하며, 특히 공간적 추론과 배치(allocentric) 및 자기중심적(egocentric) 관점 전환에 어려움을 겪는 것으로 나타났습니다. 흥미롭게도, 언어적 추론 기법은 공간 지능 향상에 도움이 되지 않지만, 인지적 지도 생성은 MLLM의 공간 거리 추론 능력을 향상시키는 것으로 보입니다. 이는 MLLM이 공간을 국소적 모델로 표상하고, 전역적 모델 생성에는 어려움을 겪는다는 점을 시사합니다. 결론적으로, MLLM의 공간 지능은 여전히 발전의 여지가 크며, 향후 연구는 국소적 모델을 전역적 모델로 통합하는 방법론에 초점을 맞춰야 할 것입니다.
VSI-Bench#
VSI-Bench는 비디오 기반 시각적 공간 지능 벤치마크로, 다양한 환경의 실내 공간을 묘사하는 288개의 실제 영상과 5,000개 이상의 질의응답 쌍으로 구성됩니다. 실제 환경 데이터를 사용하여 다양한 시각적 공간 지능 과제를 평가할 수 있다는 점이 핵심입니다. 이는 정적 이미지 기반 벤치마크보다 더욱 풍부한 공간 이해와 추론을 가능하게 합니다. 다양한 유형의 질문 (객체 개수 세기, 상대적 거리, 방향, 경로 계획 등)을 포함하며, 모델의 공간적 추론 능력을 포괄적으로 평가합니다. 정량적 성능 평가를 위한 명확한 지표를 제공함으로써, 다양한 다중 모달 대규모 언어 모델의 시각적 공간 지능 수준을 비교 분석하고, 향후 개선 방향을 제시하는 데 중요한 역할을 수행합니다. 특히, 인간의 성능과의 비교를 통해 모델의 강점과 한계를 명확히 드러내어, 시각적 공간 지능 향상을 위한 연구 방향을 제시합니다.
MLLM Reasoning#
본 논문에서는 **MLLM(다중 모드 대규모 언어 모델)**의 추론 능력에 대한 심층적인 분석을 제시합니다. 특히, 시공간적 지능(visual-spatial intelligence) 측면에서 MLLM이 공간을 어떻게 인지하고, 기억하고, 상기하는지에 초점을 맞춥니다. 비디오 데이터를 기반으로 구축된 VSI-Bench 벤치마크를 통해 MLLM의 성능을 평가하고, 인간 수준의 시공간적 추론 능력과의 차이점을 분석합니다. 흥미롭게도, 언어적 추론 기법(CoT, self-consistency, ToT)은 MLLM의 공간 추론 능력 향상에 큰 효과가 없다는 점을 발견하였습니다. 반면, 인지 지도(cognitive maps) 생성을 통해 MLLM의 공간 거리 추정 능력이 향상되었음을 확인하였습니다. 이는 MLLM이 국지적인 공간 모델은 잘 구축하지만, 전반적인 공간 모델 구축에는 어려움을 겪는다는 것을 시사합니다. 따라서, MLLM의 시공간적 추론 능력 향상을 위해서는 국지적 모델에서 전반적인 공간 모델로의 확장이 중요한 과제임을 강조합니다.
Cognitive Maps#
본 논문에서 인용된 ‘인지 지도(Cognitive Maps)‘는 **다중모드 대규모 언어 모델(MLLM)**이 공간적 정보를 어떻게 표상하고 기억하는지 이해하는 데 중요한 개념입니다. 연구는 MLLM이 단편적인 비디오 프레임에서 전체적인 공간 지도를 생성하기보다는 국소적인 공간 모델을 만들어 연속적인 공간 경험을 재구성한다는 것을 보여줍니다. 이러한 국소적 모델은 인접한 사물들의 위치 관계는 정확하게 파악하지만, 거리가 멀어질수록 정확도가 떨어집니다. 인지 지도 생성은 MLLM의 공간적 추론 능력을 향상시키는 데 도움이 되는 것으로 나타났습니다. 특히, 거리 추정과 같은 과제에서 인지 지도 활용은 성능 개선으로 이어집니다. 이는 MLLM이 공간적 정보를 처리하는 방식에 대한 중요한 통찰력을 제공하며, 보다 정교한 공간적 이해 능력을 갖춘 모델 개발을 위한 방향을 제시합니다.
Future Work#
본 논문의 “미래 연구” 부분은 시각적 공간 지능 향상을 위한 다양한 방향을 제시합니다. MLLM의 공간 추론 능력 향상을 위해 특정 작업에 대한 파인튜닝, 자기 지도 학습 기법 도입, 그리고 시각적 공간 추론에 맞춤화된 프롬프팅 기법 개발 등을 제안합니다. 또한, 비디오 데이터를 활용한 MLLM의 공간 이해 능력에 대한 심층 연구를 통해, 지도 학습과 비지도 학습의 강점을 결합한 새로운 학습 전략을 모색해야 합니다. 공간적 추론 과정의 투명성을 높이는 방법도 중요한 연구 과제입니다. 실제 로봇과의 상호 작용을 통해 MLLM의 공간 지능을 평가하고 발전시키는 연구가 필요합니다. 궁극적으로, 인간 수준의 시각적 공간 지능을 가진 MLLM을 개발하기 위한 연구가 지속되어야 합니다.
More visual insights#
More on figures

🔼 그림 2는 시각-공간 지능 능력의 계층 구조를 보여줍니다. 시각적 지각, 공간 추론, 시간적 처리, 언어적 지능의 네 가지 주요 영역이 있습니다. 공간 추론은 관계적 추론과 자기중심-타중심 변환이라는 두 가지 주요 기능으로 나뉩니다. 관계적 추론은 거리와 방향을 통해 객체 간의 관계를 파악하는 능력을 의미합니다. 또한, 크기, 거리 등의 시각적 상식에 기반하여 객체 사이의 거리를 추론하는 것을 포함합니다. 자기중심-타중심 변환은 자기중심적 관점(자신의 위치를 중심으로 한 관점)과 타중심적 관점(환경을 중심으로 한 관점)을 전환하는 능력입니다. 이러한 전환은 다양한 관점에서 공간을 이해하고 새로운 관점을 시각화하고, 경로 계획과 같은 작업에 필수적인 공간적 정신 지도를 만드는 데 필요합니다. 시각적 작업 기억은 정보를 처리하고 사용할 수 있는 능력을 나타내며, 원근 시각화는 객체의 위치와 방향을 이해하는 데 도움이 됩니다. 또한, 시각-공간 지능은 거리, 방향, 시각적 공간 상식과 같은 시각적 공간 상식에 대한 이해를 포함합니다.
read the caption
Figure 2: A taxonomy of visual-spatial intelligence capabilities.

🔼 그림 3은 VSI-Bench의 8가지 과제를 보여줍니다. 각 과제는 다양한 유형의 시공간 추론 능력을 평가하도록 설계되었습니다. 예를 들어, ‘물체 개수 세기’는 공간 내 물체의 수를 파악하는 능력을, ‘상대 거리 측정’은 물체 간의 상대적 거리를 추론하는 능력을, ‘상대 방향 파악’은 물체의 상대적 위치를 파악하는 능력을, ‘외관 순서’는 시간적 순서에 따른 물체의 출현 순서를 기억하는 능력을, ‘상대적 방향’은 주어진 위치에서 다른 물체의 방향을 파악하는 능력을, ‘절대 거리 측정’은 물체 간의 절대적 거리를 측정하는 능력을, ‘방 크기’는 방의 크기를 추정하는 능력을, ‘경로 계획’은 주어진 환경에서 목표 위치까지의 경로를 계획하는 능력을 평가합니다. 각 과제에 대한 질문은 명확성과 간결성을 위해 약간 간략화되었습니다.
read the caption
Figure 3: Tasks demonstration of VSI-Bench. Note: the questions above are simplified slightly for clarity and brevity.

🔼 그림 4는 VSI-Bench 데이터셋 제작 과정을 보여줍니다. 다양한 데이터셋들을 표준화된 형식과 의미 공간으로 통합하여 일관된 처리가 가능하도록 합니다. QA 쌍은 사람의 주석과 질문 템플릿을 통해 생성됩니다. 품질을 보장하기 위해 저품질 비디오, 주석 및 모호한 QA 쌍을 걸러내기 위해 모든 단계에서 사람의 검증이 이루어집니다.
read the caption
Figure 4: Benchmark curation pipeline. The pipeline first unifies diverse datasets into a standardized format and semantic space for consistent processing. QA pairs are then generated through both human annotation and question templates. To ensure quality, human verification is implemented at all key stages for filtering low-quality videos, annotations, and ambiguous QA pairs.
🔼 그림 5는 VSI-Bench 데이터셋의 통계를 보여줍니다. 위쪽 그래프는 세 가지 주요 범주(구성, 측정, 시공간)에 걸쳐 작업의 분포를 보여주는 막대 그래프입니다. 각 범주 내에는 여러 하위 작업이 포함되어 있으며, 각 하위 작업의 데이터셋 내 비율이 표시됩니다. 아래쪽 그래프는 각 데이터셋(ScanNet, ScanNet++, ARKitScenes)에 따른 비디오 길이 분포를 나타내는 히스토그램입니다. 이 히스토그램을 통해 각 데이터셋의 비디오 길이 분포 특징을 파악할 수 있으며, 데이터셋의 다양성을 평가하는 데 도움이 됩니다.
read the caption
Figure 5: Benchmark Statistics. Top: The distribution of tasks across three main categories. Bottom: The video length statistic.

🔼 그림 6은 VSI-Bench에 대한 평가 결과를 보여줍니다. 왼쪽 그래프는 모든 모델 중 최고 성능을 어두운 회색으로, 오픈소스 모델 중 최고 성능을 밝은 회색으로 표시합니다. †는 축소된 VSI-Bench(tiny) 데이터셋에 대한 결과를 나타냅니다. 오른쪽 그래프는 상위 3개의 오픈소스 모델을 포함한 결과를 보여줍니다. 각 과제에 대한 모델의 성능을 정량적으로 비교하여 시각적 공간 지능의 강점과 약점을 보여줍니다.
read the caption
Figure 6: Evaluation on VSI-Bench. Left: Dark gray indicates the best result among all models and light gray indicates the best result among open-source models. † indicates results on VSI-Bench (tiny) set. Right: Results including the top-3 open-source models.

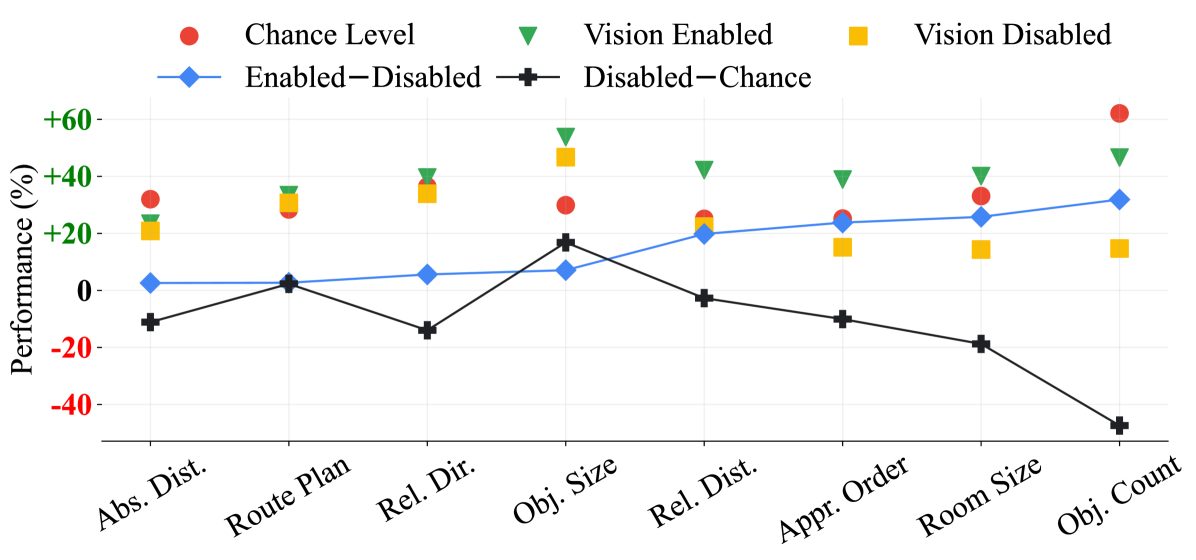
🔼 그림 6은 비전 활성화(비디오 포함), 비전 비활성화(비디오 없음), 그리고 우연 수준(빈도) 간의 성능 비교를 보여줍니다. 활성화-비활성화는 비전 활성화와 비전 비활성화 간의 차이를 나타내고, 비활성화-우연은 비전 비활성화와 우연 수준(빈도) 간의 차이를 보여줍니다. 과제는 활성화-비활성화에 따라 정렬되어 이해도를 높였습니다. 이 그림은 다양한 시각적 공간 지능 과제에서 비디오 데이터의 중요성과 모델의 한계를 보여줍니다.
read the caption
Figure 7: Performance comparisons between Vision Enabled (w/ video), Vision Disabled (w/o video) and Chance Level (Freq.). Enabled−--Disabled indicates the gap between Vision Enabled and Vision Disabled, and Disabled−--Chance betokens the gap between Vision Disabled and Chance Level (Freq.). Tasks are sorted by Enable−--Disable for better understanding.

🔼 그림 7은 다중 모드 대규모 언어 모델(MLLM)이 자체 설명에서 어떻게 생각하는지를 보여주는 예시입니다. MLLM은 비디오 이해 및 언어적 추론 능력이 뛰어나지만, 공간적 추론 능력은 아직 개발 중임을 보여줍니다. 즉, 그림은 MLLM이 질문에 답변하기 위해 사용하는 사고 과정을 보여주는 자체 설명의 예시를 제시합니다. 각 예시는 시각적 정보(비디오)와 언어적 정보(질문, 답변, 추론 과정)를 함께 보여줌으로써 MLLM의 사고 과정을 자세히 분석하고, 강점과 약점을 파악하는 데 도움을 줍니다. 특히, MLLM의 시각적 정보 처리 능력과 언어적 추론 능력은 뛰어나지만, 공간적인 관계나 위치를 정확하게 이해하고 추론하는 데는 어려움이 있음을 보여줍니다.
read the caption
Figure 8: Examples of how a MLLM thinks as seen in self-explanations. While a MLLM exhibits strong video understanding and linguistic reasoning capabilities, its spatial reasoning capabilities are still developing.

🔼 그림 8은 다양한 유형의 실수에 대한 인간이 수행한 분석을 보여줍니다. 각 과제 유형별로 모델이 어떤 종류의 오류를 범했는지 시각적으로 보여주는 막대 그래프와 원 그래프가 함께 제시됩니다. 분석 결과에 따르면, 70%가 넘는 오류가 공간 추론 능력의 결함에서 비롯된다는 것을 알 수 있습니다. 이는 모델이 공간적 관계를 이해하고 이를 사용하여 질문에 답하는 데 어려움을 겪는다는 것을 시사합니다. 이는 단순히 개체를 인식하는 것 이상으로 공간적 사고 능력이 부족하다는 점을 강조합니다.
read the caption
Figure 9: Human-conducted analysis of errors by type. Over 70% of errors stem from faulty spatial reasoning capabilities.

🔼 그림 10은 제시된 벤치마크(VSI-Bench)에서 세 가지 주요 언어적 프롬프팅 기법(제로샷 체인 오브 스레드, 자기 일관성, 트리 오브 스레드)의 성능 향상 정도를 기준 성능과 비교하여 보여줍니다. 세 가지 방법 모두 평균적으로 벤치마크에서 실패했으며, 경우에 따라 적용 후 작업 성능이 훨씬 저하되는 경우도 있었습니다. 이는 VSI-Bench가 단순히 언어적 능력만 향상시켜서는 해결할 수 없다는 점을 시사합니다. 즉, 시각적 공간 지능은 언어적 추론만으로는 해결될 수 없으며, 시각적 정보 처리 및 공간적 추론 능력의 향상 또한 필요하다는 것을 보여줍니다.
read the caption
Figure 10: Relative improvements of CoT, self-consistency and Tree-of-Thought compared to the baseline. All three prevailing prompting techniques fail on average on our benchmark, and, in some cases, task performance becomes much worse after applying them. This implies that VSI-Bench cannot be solved by solely improving linguistic capabilities.

🔼 그림 11은 다양한 실내 환경에 대한 MLLM(다중 모드 대규모 언어 모델)과 GT(Ground Truth)의 인지 지도를 시각적으로 비교한 것입니다. 각 지도는 방 안의 물체들의 위치를 10x10 격자 좌표로 표현하여, MLLM이 실제 공간을 얼마나 정확하게 이해하고 있는지를 보여줍니다. MLLM의 예측 결과는 GT와 비교하여, MLLM이 공간적 관계를 얼마나 잘 파악하는지, 그리고 어떤 오차가 발생하는지를 보여줍니다. 특히, 가까운 물체들의 위치는 상대적으로 정확하게 예측하지만, 먼 물체일수록 정확도가 떨어지는 경향이 그림에서 나타납니다.
read the caption
Figure 11: Visualization of cognitive maps from MLLM and GT.

🔼 본 그림은 MLLM이 예측한 인지 지도에서 거리 정확도가 객체 간의 거리가 증가함에 따라 크게 감소함을 보여줍니다. 즉, MLLM은 가까운 객체들의 위치는 상대적으로 정확하게 예측하지만, 멀리 떨어진 객체들의 위치는 정확도가 급격히 떨어짐을 시각적으로 보여줍니다. 이는 MLLM이 공간을 표현할 때, 전체 공간에 대한 하나의 통합된 지도를 생성하는 것이 아니라, 국부적인 영역에 대한 여러 개의 부분적인 지도를 형성하는 경향이 있음을 시사합니다.
read the caption
Figure 12: Locality of the MLLM’s predicted cognitive maps. The MLLM’s map-distance accuracy decreases dramatically with increasing object distance.

🔼 그림 13은 VSI-Bench의 질문 유형 예시를 보여줍니다. 다양한 유형의 질문 (물체 개수 세기, 상대적 거리, 방향, 외형 순서, 크기, 절대적 거리, 방 크기, 경로 계획) 이 제시되며 각 질문 유형에 대한 여러가지 예시 질문과 답변이 함께 제공됩니다. 이를 통해 모델이 공간적 지각, 기억, 상기 능력을 어떻게 평가하는지 보여줍니다. 각각의 예시는 다양한 실내 공간을 보여주는 비디오 클립과 연관되어 있어, 모델이 실제 환경에서 얼마나 잘 작동하는지 이해하는 데 도움이 됩니다.
read the caption
Figure 13: VSI-Bench Examples (Part 1).

🔼 그림 14는 VSI-Bench의 질문 유형 예시 중 일부를 보여줍니다. 각 질문 유형(개체 수 세기, 상대 거리, 개체 크기, 방 크기, 상대 방향, 경로 계획, 외관 순서)에 대해 2개의 예시를 제공하여 다양한 시각적 공간적 추론 능력을 평가하는 방법을 보여줍니다. 각 예시는 질문과 그에 해당하는 이미지, 정답을 포함합니다. 이 그림은 논문의 3장, VSI-Bench 벤치마크 소개 부분에 포함되어 있습니다.
read the caption
Figure 14: VSI-Bench Examples (Part 2).

🔼 그림 15는 모델의 오류 분석 사례들을 추가적으로 보여줍니다. 시각적 인식 오류, 언어적 지능 오류, 관계적 추론 오류, 그리고 자기 중심적-타중심적 변환 오류 등 네 가지 주요 오류 유형을 보여주는 다양한 질문과 답변 예시들이 제시됩니다. 각 오류 유형에 대한 설명과 함께, 모델이 어떤 부분에서 오류를 범했는지에 대한 자세한 분석이 포함되어 있습니다. 특히, 모델이 질문에 대한 답변을 생성하는 과정에서 시각적 정보를 어떻게 처리하고 해석하는지, 그리고 어떤 유형의 추론 과정을 거치는지에 대한 통찰력을 제공합니다.
read the caption
Figure 15: Additional Error Analysis Examples.

🔼 그림 16은 제로샷 체인 오브 스레드(Zero-Shot Chain of Thought) 기법을 사용한 질의응답 예시를 보여줍니다. 세 가지 다른 유형의 질문(개체 수 세기, 개체 크기, 방 크기)에 대한 모델의 응답과 추론 과정을 단계별로 보여줍니다. 각 질문 유형에 대해 모델이 어떻게 질문을 이해하고, 관련 정보를 추출하고, 최종 답변에 도달하는지 자세히 설명합니다. 이는 모델의 추론 과정을 시각적으로 보여주어 모델의 성능과 한계를 이해하는 데 도움을 줍니다.
read the caption
Figure 16: Zero-Shot CoT Examples.

🔼 그림 17은 ‘Self-Consistency with Chain-of-Thought’ 프롬프팅 기법을 사용한 모델의 추론 과정을 보여줍니다. 세 가지 과제(개체 수 세기, 개체 크기 추정, 방 크기 추정)에 대해, 모델이 질문에 대한 답을 도출하는 다섯 가지 다른 시도의 예시를 보여줍니다. 각 시도는 중간 단계의 추론 과정과 최종 답변을 포함하며, 각 과제에 대해 다수결 투표로 최종 답변을 결정하는 과정을 보여줍니다. 이는 모델이 주어진 비디오 데이터를 기반으로 어떻게 추론하고 답변을 생성하는지, 그리고 Self-Consistency 기법이 모델의 성능에 어떻게 영향을 미치는지를 보여주는 시각적인 설명입니다.
read the caption
Figure 17: Self-Consistency w/ CoT Examples.
More on tables
| Case | Performance |
|---|---|
| Gemini-1.5 Pro (w/o CoT) | 77.2 |
| Gemini-1.5 Pro (w/ CoT) | 79.8 |
🔼 표 (a)는 인지 지도 프롬프팅에 대한 실험 결과를 보여줍니다. ‘Cog. Map Src’는 인지 지도 생성에 사용된 소스(MLLM 또는 GT)를 나타내고, ‘Size’는 인지 지도의 크기를 나타냅니다. ‘Rel. Dist Acc’는 상대 거리 정확도를 의미하며, 인지 지도를 사용했을 때와 사용하지 않았을 때의 상대 거리 질문에 대한 MLLM의 정확도를 비교합니다. 결과는 인지 지도를 사용하면 MLLM의 상대 거리 추론 능력이 향상됨을 보여줍니다.
read the caption
(a) Cognitive map prompting.
| Case | Rel. Dist Acc. |
|---|---|
| w/o Cog. map | 46.0 |
| w/ Cog. map | 56.0 |
| w/ Cog. map (GT) | 66.0 |
🔼 표 (b)는 MLLM이 공간을 기억하는 방식을 조사하기 위해 사용된 인지 지도의 크기가 성능에 미치는 영향을 보여줍니다. 10x10 크기의 격자와 20x20 크기의 격자를 비교하여, MLLM의 상대적 거리 추론 정확도에 대한 영향을 분석합니다. 즉, MLLM이 공간을 표현하는 데 사용하는 격자 크기가 다를 때 상대적 거리 인식 성능이 어떻게 변하는지 보여주는 실험 결과입니다.
read the caption
(b) Cognitive map canvas size.
| Cog. Map Src. | Size | Rel. Dist Acc. |
|---|---|---|
| MLLM | 10 × 10 | 56.0 |
| MLLM | 20 × 20 | 54.0 |
| GT | 10 × 10 | 66.0 |
| GT | 20 × 20 | 78.0 |
🔼 표 2는 모델이 공간적 정보를 기억하는 방식을 평가하기 위해 사용된 ‘인지 지도’ 접근법에 대한 실험 결과를 보여줍니다. 특히, 인지 지도를 활용했을 때 상대적 거리 추론 과제에서 모델의 성능 향상 여부를 보여줍니다. ‘인지 지도 생성’ 크기(10x10 또는 20x20)를 달리하여 실험한 결과도 포함되어 있습니다. 기준 모델(MLLM)과 인지 지도를 사용한 모델의 성능을 비교하여 인지 지도의 효과를 정량적으로 분석합니다.
read the caption
Table 2: Relative distance task with cognitive map.
| Task | Question Template |
|---|---|
| Object Counting | How many {category}(s) are in this room? |
| Relative Distance | Measuring from the closest point of each object, which of these objects ({choice a}, {choice b}, {choice c}, {choice d}) is the closest to the {category}? |
| Relative Direction | To create a comprehensive test of relative direction, three difficulty levels were created: |
- Easy: If I am standing by the {positioning object} and facing the {orienting object}, is the {querying object} to the left or the right of the {orienting object}?
- Medium: If I am standing by the {positioning object} and facing the {orienting object}, is the {querying object} to my left, right, or back? An object is to my back if I would have to turn at least 135 degrees in order to face it.
- Hard: If I am standing by the {positioning object} and facing the {orienting object}, is the {querying object} to my front-left, front-right, back-left, or back-right? Directions refer to the quadrants of a Cartesian plane (assuming I am at the origin and facing the positive y-axis). | | Appearance Order | What will be the first-time appearance order of the following categories in the video: {choice a}, {choice b}, {choice c}, {choice d}? | | Object Size | What is the length of the longest dimension (length, width, or height) of the {category}, measured in centimeters? | | Absolute Distance | Measuring from the closest point of each object, what is the direct distance between the {object 1} and the {object 2} (in meters)? | | Room Size | What is the size of this room (in square meters)? If multiple rooms are shown, estimate the size of the combined space. | | Route Plan | You are a robot beginning at {the bed facing the tv}. You want to navigate to {the toilet}. You will perform the following actions (Note: for each [please fill in], choose either ‘turn back,’ ‘turn left,’ or ‘turn right.’): {1. Go forward until the TV 2. [please fill in] 3. Go forward until the shower 4. [please fill in] 5. Go forward until the toilet.}. You have reached the final destination.|
🔼 이 표는 VSI-Bench(Video-based Spatial Intelligence Benchmark)의 각 과제에 대한 질문 템플릿을 보여줍니다. VSI-Bench는 다양한 실내 환경의 비디오를 사용하여 다중 모달 대규모 언어 모델(MLLM)의 시각-공간 지능을 평가하기 위한 벤치마크입니다. 표에는 개체 계수, 상대 거리, 상대 방향, 경로 계획, 외형 순서, 개체 크기, 절대 거리, 방 크기 등 8가지 과제에 대한 질문 템플릿이 나열되어 있습니다. 각 템플릿에는 특정 요소(예: 개체 범주, 선택지)를 해당 장면에 맞게 바꿔서 사용하도록 되어 있습니다. 경로 계획 과제의 경우 완벽한 예시 질문이 제공됩니다. 이 표는 VSI-Bench 데이터셋을 구성하는 방법과 MLLM 평가 방식에 대한 이해를 돕습니다.
read the caption
Table 3: Question Templates for tasks in VSI-Bench. We replace the highlighted part in the question template from scene to scene to construct our benchmark. Note that a complete example question is provided for Route Plan.
| Order | Avg. |
|---|---|
| Video first | 48.8 |
| Question first | 46.3 |
🔼 표 5는 비디오 입력 순서와 반복에 따른 비교 실험 결과를 보여줍니다. (a) 비디오 입력 순서는 비디오를 먼저 보여주는 방식과 질문을 먼저 보여주는 방식을 비교합니다. (b) 비디오 반복 횟수는 비디오를 한 번 보여주는 것과 두 번 보여주는 것을 비교합니다. 실험 결과, 비디오를 먼저 보여주는 방식이 질문을 먼저 보여주는 방식보다 평균 정확도가 약 2.5% 높았고, 비디오를 두 번 보여주는 방식이 한 번 보여주는 방식보다 평균 정확도가 약 2.1% 높았습니다. 이는 사람이 시각적 정보를 여러 번 검토하여 문제 해결 능력을 향상시키는 것과 유사합니다. 이러한 결과는 MLLM이 비디오 이해에 있어 단순히 시각적 정보를 처리하는 것을 넘어, 반복적인 검토를 통해 추론 능력을 향상시킬 수 있음을 시사합니다.
read the caption
(a) Input Sequence
| # Times | Avg. |
|---|---|
| 1 | 48.8 |
| 2 | 50.9 |
🔼 표 5(b)는 비디오 반복 횟수에 따른 모델 성능 변화를 보여줍니다. 비디오를 한 번만 보여주었을 때와 두 번 보여주었을 때의 Gemini-1.5 Pro 모델 성능을 비교하여, 비디오를 반복해서 보여주는 것이 모델 성능 향상에 미치는 영향을 분석한 결과입니다. 구체적으로는, 평균 정확도를 비교하여 비디오 반복이 모델 성능 향상에 어떤 영향을 주는지 확인합니다. 단순히 비디오를 여러 번 보여주는 것만으로도 성능이 향상될 수 있는지, 그리고 그 정도는 어느 정도인지 보여주는 실험 결과입니다.
read the caption
(b) Video Repetition Times
| Methods | # of Frames |
|---|---|
| Proprietary Models (API) | |
| GPT-4o | 16 |
| Gemini-1.5 Flash | - |
| Gemini-1.5 Pro | - |
| Open-source Models | |
| InternVL2-2B | 8 |
| InternVL2-8B | 8 |
| InternVL2-40B | 8 |
| LongVILA-8B | 32 |
| VILA-1.5-8B | 32 |
| VILA-1.5-40B | 32 |
| LongVA-7B | 32 |
| LLaVA-NeXT-Video-7B | 32 |
| LLaVA-NeXT-Video-72B | 32 |
| LLaVA-OneVision-0.5B | 32 |
| LLaVA-OneVision-7B | 32 |
| LLaVA-OneVision-72B | 32 |
🔼 표 5는 비디오 입력 순서 및 반복에 대한 추가 실험 결과를 보여줍니다. 먼저, 비디오를 먼저 보여주는 방식(Video first)과 질문을 먼저 보여주는 방식(Question first)을 비교한 결과, 비디오 먼저 방식이 평균 2.5% 더 높은 성능을 보였습니다. 이는 시각적 정보를 먼저 제공하는 것이 모델의 이해도 향상에 도움이 된다는 것을 시사합니다. 다음으로, 비디오 반복 횟수에 따른 성능 변화를 분석한 결과, 비디오를 두 번 반복해서 보여준 경우 평균 2.1% 더 높은 성능을 기록했습니다. 이는 모델이 비디오를 여러 번 분석할 수 있는 기회를 제공하면 더 나은 성능을 낼 수 있음을 보여주는 결과입니다. 즉, 시각 정보의 순서와 반복 횟수가 모델의 시각적 추론 능력에 영향을 미침을 보여주는 실험입니다.
read the caption
Table 4: Ablations on the video input sequence and repetition.
| Models | QA. Type | Prompt |
|---|---|---|
| Pre-Prompt | - | These are frames of a video. |
| Post-Prompt | Open-source Models | NA |
| MCA | ||
| Post-Prompt | Proprietary Models | NA |
| MCA |
🔼 표 6은 평가에 사용된 비디오 프레임 수를 보여줍니다. 각 모델에 대해 비디오의 전체 프레임 수가 아니라, 실제 평가에 사용된 프레임의 수를 나타냅니다. 이는 모델의 성능 평가에 사용된 비디오 데이터의 양적 차이를 보여주는 정보입니다. 특히, 일부 모델의 경우 비디오 전체를 사용하지 않고 일부만 사용했음을 알 수 있습니다. 비디오 프레임의 수는 모델의 유형과 매개변수 크기 등에 따라 다릅니다. 이 표는 모델별로 사용된 비디오 데이터 양의 차이를 고려해야 할 필요가 있음을 시사합니다.
read the caption
Table 5: Number of frames used in evaluation.
| Methods | Avg. | Obj. Count | Abs. Dist. | Obj. Size | Room Size | Rel. Dist. | Rel. Dir. | Route Plan | Appr. Order |
|---|---|---|---|---|---|---|---|---|---|
| Proprietary Models (API) | |||||||||
| GPT-4o | 35.6 | 36.2 | 4.6 | 47.2 | 40.4 | 40.0 | 46.2 | 32.0 | 38.0 |
| Gemini-1.5 Flash | 45.7 | 50.8 | 33.6 | 56.5 | 45.2 | 48.0 | 39.8 | 32.7 | 59.2 |
| Gemini-1.5 Pro | 48.8 | 49.6 | 28.8 | 58.6 | 49.4 | 46.0 | 48.1 | 42.0 | 68.0 |
| Gemini-2.0 Flash | 45.4 | 52.4 | 30.6 | 66.7 | 31.8 | 56.0 | 46.3 | 24.5 | 55.1 |
| Open-source Models | |||||||||
| InternVL2-2B | 25.5 | 30.6 | 20.4 | 26.0 | 29.6 | 28.0 | 39.2 | 28.0 | 2.0 |
| InternVL2-8B | 32.9 | 26.4 | 25.4 | 43.8 | 41.6 | 30.0 | 32.2 | 20.0 | 44.0 |
| InternVL2-40B | 37.6 | 40.8 | 23.8 | 48.0 | 26.0 | 46.0 | 30.1 | 42.0 | 44.0 |
| LongVILA-8B | 19.1 | 23.4 | 10.8 | 11.4 | 0.0 | 20.0 | 33.1 | 28.0 | 26.0 |
| VILA-1.5-8B | 31.4 | 12.2 | 23.4 | 51.4 | 18.6 | 36.0 | 41.5 | 42.0 | 26.0 |
| VILA-1.5-40B | 32.3 | 14.6 | 21.0 | 48.0 | 20.6 | 42.0 | 22.0 | 40.0 | 50.0 |
| LongVA-7B | 31.8 | 41.2 | 17.4 | 39.6 | 25.4 | 30.0 | 52.8 | 34.0 | 14.0 |
| LLaVA-NeXT-Video-7B | 35.7 | 49.0 | 12.8 | 48.6 | 21.4 | 40.0 | 43.5 | 34.0 | 36.0 |
| LLaVA-NeXT-Video-72B | 39.3 | 41.4 | 26.6 | 55.6 | 31.6 | 36.0 | 25.6 | 42.0 | 56.0 |
| LLaVA-OneVision-0.5B | 27.7 | 44.0 | 23.0 | 18.8 | 28.4 | 30.0 | 33.4 | 36.0 | 8.0 |
| LLaVA-OneVision-7B | 33.8 | 48.2 | 22.0 | 44.4 | 14.0 | 44.0 | 31.9 | 34.0 | 32.0 |
| LLaVA-OneVision-72B | 41.6 | 38.0 | 31.6 | 54.4 | 35.2 | 44.0 | 39.7 | 32.0 | 58.0 |
🔼 표 7은 본 논문의 실험에서 사용된 프롬프트들을 보여줍니다. 각 모델(오픈소스 모델과 독점 모델)과 질문 유형(수치형 답변, 다중 선택형 답변)에 따라 다른 프롬프트가 사용되었음을 알 수 있습니다. 수치형 답변의 경우 숫자만으로 답변하도록 지시하고, 다중 선택형 답변의 경우 제시된 선택지 중 하나의 문자를 답으로 제출하도록 지시합니다. 이는 모델의 응답 형식을 일관성 있게 유지하고, 결과 분석의 정확성을 높이기 위한 것입니다.
read the caption
Table 6: Prompts used in evaluation. NA and MAC indicates questions with Numerical Answer and Multiple Choice Answer respectively.
| Methods | Avg. | Obj. Count | Abs. Dist. | Obj. Size | Room Size | Rel. Dist. | Rel. Dir. | Route Plan | Appr. Order |
|---|---|---|---|---|---|---|---|---|---|
| Proprietary Models (API) | |||||||||
| GPT-4o | 14.5 | 0.1 | 5.2 | 36.7 | 0.0 | 10.8 | 23.2 | 26.9 | 13.1 |
| Gemini-1.5 Flash | 19.9 | 25.0 | 30.3 | 52.5 | 0.0 | 0.0 | 21.2 | 29.9 | 0.2 |
| Gemini-1.5 Pro | 32.3 | 30.6 | 11.5 | 51.5 | 33.1 | 33.8 | 44.6 | 33.5 | 20.2 |
| Open-source Models | |||||||||
| InternVL2-2B | 17.8 | 5.4 | 23.7 | 9.2 | 0.0 | 26.9 | 41.2 | 27.9 | 7.9 |
| InternVL2-8B | 27.6 | 31.9 | 26.8 | 38.3 | 0.7 | 27.1 | 39.2 | 33.0 | 23.6 |
| InternVL2-40B | 24.4 | 5.4 | 29.1 | 39.2 | 0.7 | 30.3 | 37.7 | 27.9 | 24.7 |
| LongVILA-8B | 20.2 | 47.4 | 12.6 | 8.7 | 0.6 | 24.3 | 27.0 | 27.4 | 13.9 |
| VILA-1.5-8B | 21.5 | 7.4 | 7.6 | 45.7 | 0.0 | 25.4 | 39.1 | 29.4 | 17.6 |
| VILA-1.5-40B | 25.5 | 5.3 | 27.6 | 46.5 | 0.7 | 30.2 | 37.1 | 31.5 | 25.0 |
| LongVA-7B | 21.9 | 5.1 | 18.1 | 27.4 | 26.1 | 23.4 | 39.8 | 26.9 | 8.7 |
| LLaVA-NeXT-Video-7B | 25.2 | 14.8 | 14.6 | 32.5 | 26.1 | 26.8 | 45.0 | 33.0 | 8.5 |
| LLaVA-NeXT-Video-72B | 29.1 | 19.0 | 25.4 | 46.3 | 26.1 | 29.0 | 38.8 | 33.0 | 15.5 |
| LLaVA-OneVision-0.5B | 28.6 | 38.4 | 30.1 | 32.0 | 24.3 | 22.0 | 41.8 | 34.5 | 5.4 |
| LLaVA-OneVision-7B | 25.3 | 13.8 | 8.5 | 45.5 | 26.1 | 28.6 | 41.2 | 27.9 | 11.1 |
| LLaVA-OneVision-72B | 28.9 | 8.2 | 23.8 | 54.1 | 26.1 | 30.4 | 38.1 | 33.0 | 17.1 |
🔼 표 7은 본 논문에서 제시된 VSI-Bench (tiny) 데이터셋에 대한 15가지 다양한 비디오 지원 다중 모달 대규모 언어 모델(MLLM)의 성능 평가 결과를 보여줍니다. 표에는 각 모델의 평균 정확도와 함께, 개체 수 세기, 상대 거리, 개체 크기, 방 크기, 상대 방향, 경로 계획, 외관 순서 등 8가지 시각적 공간 지능 작업에 대한 세부 정확도 점수가 포함되어 있습니다. 이 표는 다양한 MLLM의 시각적 공간 추론 능력을 비교하고, 강점과 약점을 분석하는 데 도움이 됩니다.
read the caption
Table 7: Complete VSI-Bench (tiny) evaluation results.
| Methods | Avg. | Obj. Count | Abs. Dist. | Obj. Size | Room Size | Rel. Dist. | Rel. Dir. | Route Plan | Appr. Order |
|---|---|---|---|---|---|---|---|---|---|
| Proprietary Models (API) | |||||||||
| GPT-4o | 19.5 | 46.1 | 0.1 | 7.1 | 38.2 | 26.2 | 18.0 | 4.6 | 15.4 |
| Gemini-1.5 Flash | 22.2 | 24.9 | 0.5 | 1.0 | 54.4 | 37.7 | 19.9 | 1.5 | 37.7 |
| Gemini-1.5 Pro | 13.0 | 25.5 | 19.5 | 12.6 | 10.6 | 17.5 | 1.7 | 2.5 | 14.4 |
| Open-source Models | |||||||||
| InternVL2-2B | 9.6 | 16.4 | 1.2 | 12.8 | 35.0 | 6.9 | 3.0 | 2.5 | -0.8 |
| InternVL2-8B | 7.0 | -8.8 | 1.9 | 9.9 | 39.1 | 9.7 | -8.5 | -3.0 | 16.0 |
| InternVL2-40B | 11.6 | 29.6 | -2.2 | 7.3 | 31.1 | 11.8 | -5.5 | 6.1 | 14.9 |
| LongVILA-8B | 1.4 | -18.2 | -3.5 | 7.9 | -0.6 | 5.3 | 3.7 | 5.1 | 11.5 |
| VILA-1.5-8B | 7.3 | 10.0 | 14.2 | 4.6 | 18.8 | 6.7 | -4.4 | 1.5 | 7.2 |
| VILA-1.5-40B | 5.7 | 17.1 | -2.8 | 2.2 | 22.0 | 10.4 | -11.4 | 0.0 | 7.9 |
| LongVA-7B | 7.2 | 32.9 | -1.5 | 11.5 | -3.9 | 9.7 | 3.5 | -1.5 | 7.1 |
| LLaVA-NeXT-Video-7B | 10.5 | 33.8 | -0.6 | 15.2 | -1.9 | 16.7 | -2.7 | 1.0 | 22.1 |
| LLaVA-NeXT-Video-72B | 11.7 | 29.9 | -2.6 | 11.1 | 9.2 | 13.3 | -2.0 | 2.0 | 33.0 |
| LLaVA-OneVision-0.5B | -0.5 | 7.8 | -1.7 | -16.6 | 4.0 | 6.9 | -5.0 | 0.0 | 0.3 |
| LLaVA-OneVision-7B | 7.0 | 33.9 | 11.7 | 1.9 | -13.9 | 13.9 | -6.0 | 1.5 | 13.3 |
| LLaVA-OneVision-72B | 11.4 | 35.4 | 0.1 | 3.5 | 11.4 | 12.1 | 1.8 | -0.5 | 27.4 |
🔼 표 8은 비전 데이터를 사용하지 않고(즉, 비전이 비활성화된 상태에서) 다양한 모델이 VSI-Bench(tiny) 데이터셋에서 달성한 성능을 보여줍니다. 다양한 모델의 평균 정확도와 각 작업(개체 수 세기, 절대 거리, 개체 크기, 방 크기, 상대 거리, 상대 방향, 경로 계획, 외관 순서)에 대한 세부 정확도를 보여주어 모델의 시각적 공간 지능 능력을 비교 분석하는 데 도움이 됩니다. 특히, 다양한 모델 유형과 크기(매개변수 수) 간의 성능 차이를 파악하고, 개방형 모델과 독점 모델 간의 성능을 비교 분석할 수 있습니다.
read the caption
Table 8: Complete blind evaluation results.
Full paper#



















