↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
단일 이미지에서 novel view synthesis(NVS)는 AR/VR 및 로봇 공학과 같은 다양한 분야에서 중요한 작업입니다. 기존의 확산 기반 방법은 단일 객체에 효과적이지만, 멀티 객체 장면에서는 객체 배치 및 일관성 유지에 어려움을 겪습니다. 특히, 구조적 인식 부족으로 인해 novel view에서 객체가 사라지거나 왜곡되고, 위치와 방향이 잘못되는 문제가 발생합니다.
이 논문은 실내 장면의 멀티 객체 NVS를 위한 구조 인식 뷰 조건 확산 모델인 MOVIS를 제안합니다. 깊이 및 객체 마스크를 입력으로 사용하여 구조적 정보를 통합하고, novel view 객체 마스크 예측을 보조 작업으로 활용합니다. 또한, 전역 객체 배치와 세부 정보 복구 간의 학습 균형을 맞추기 위해 구조 유도 timestep 샘플링 스케줄러를 도입합니다. 마지막으로, 합성된 novel view 이미지의 타당성을 평가하기 위해 교차 뷰 일관성과 novel view 객체 배치에 대한 새로운 지표를 제안합니다. 실험 결과, MOVIS는 여러 데이터셋에서 기존 방법보다 우수한 성능을 보이며, 특히 일관된 객체 배치, 형상 및 외관 복구 능력이 뛰어납니다. 또한, 보이지 않는 데이터셋에 대한 강력한 일반화 능력을 보여줍니다.
Key Takeaways#
Why does it matter?#
멀티-객체 NVS는 실내 장면 재구성과 같은 여러 애플리케이션에서 중요합니다. 이 논문은 구조적 인식 능력을 향상시킨 새로운 접근 방식을 제시하며, 이는 복잡한 장면에서 일관성 있는 객체 배치와 형상, 외관을 생성하는 데 매우 중요합니다. 제안된 평가 지표는 멀티-객체 NVS 모델을 더 잘 이해하고 미래 연구 방향을 제시합니다.
Visual Insights#

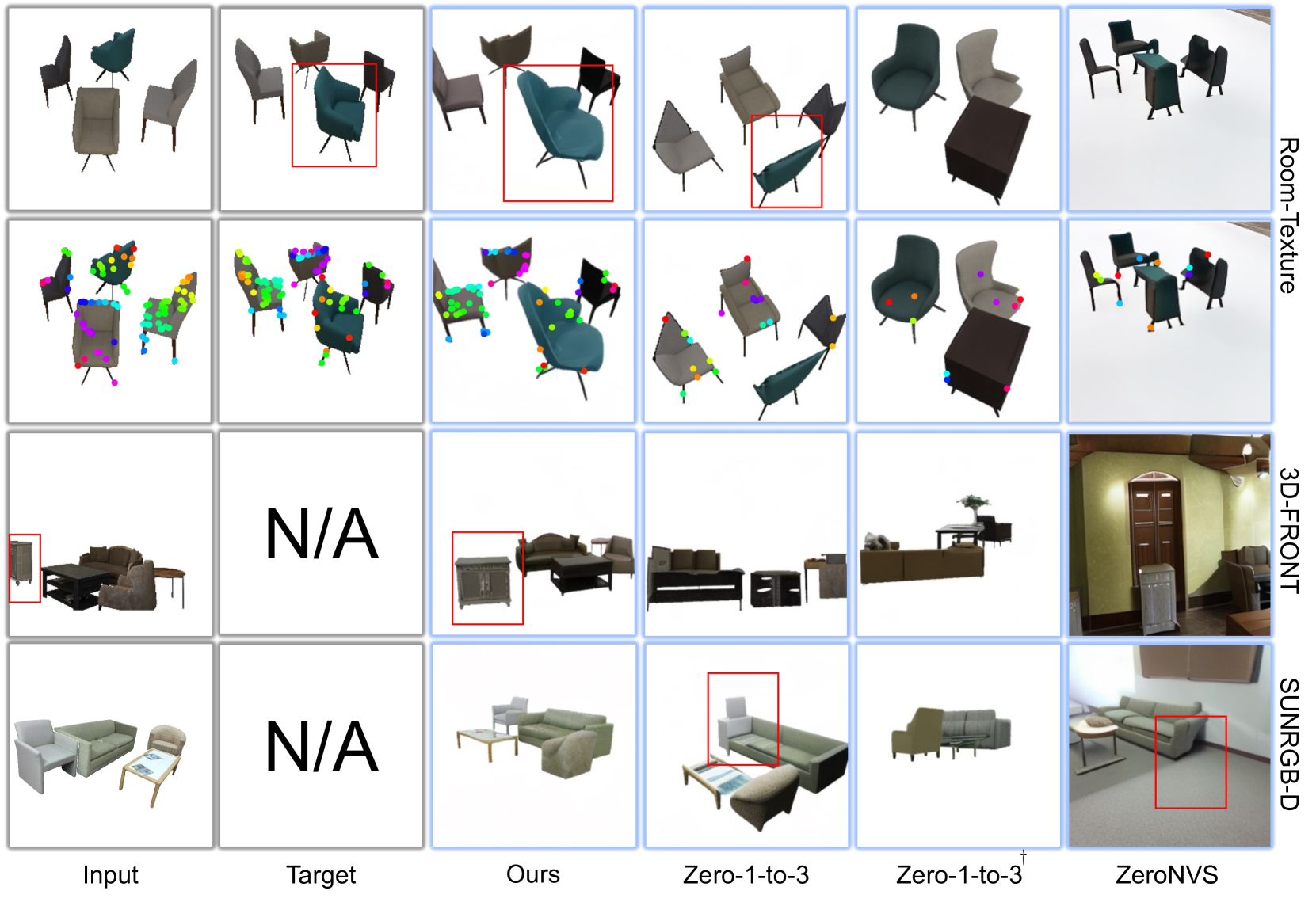
🔼 이 그림은 MOVIS(제안된 방법)가 다양한 데이터셋(Objaverse, 3D-FRONT, SUNRGB-D)에서 새로운 시점 합성(NVS) 작업을 어떻게 수행하는지 보여줍니다. 각 데이터셋에 대해 입력 이미지, 타겟 이미지(Ground Truth), MOVIS의 출력, Zero-1-to-3의 출력, Zero-1-to-3+의 출력, ZeroNVS의 출력을 시각화했습니다. 또한, 입력 이미지와 Ground Truth 및 각 모델의 예측 이미지 간의 교차 시점 일치 시각화를 통해 교차 시점 일관성을 보여줍니다. MOVIS는 Ground Truth와 매우 유사하게 정확한 객체 배치, 모양 및 외관을 가진 새로운 시점 이미지를 생성하며, Zero-1-to-3 및 다른 기준선보다 Ground Truth에 더 가깝게 일치하는 많은 점을 생성합니다.
read the caption
Figure 1: \Aclnvs and cross-view image matching. The first row shows that MOVIS generalizes to different datasets on NVS. We also show visualizations of cross-view consistency compared with Zero-1-to-3 [31] and ground truth by applying image-matching. MOVIS can match a significantly greater number of points, closely aligned with the ground truth.
| Dataset | Method | Novel View Synthesis | Placement | Cross-view Consistency |
|---|---|---|---|---|
| PSNR(↑) | SSIM(↑) | LPIPS(↓) | ||
| — | — | — | — | — |
| C3DFS | ZeroNVS | 10.704 | 0.533 | 0.481 |
| C3DFS | Zero-1-to-3 | 14.255 | 0.771 | 0.302 |
| C3DFS | Zero-1-to-3† | 14.811 | 0.794 | 0.283 |
| C3DFS | Ours | 17.432 | 0.825 | 0.171 |
| Room-Texture | ZeroNVS | 8.217 | 0.647 | 0.487 |
| Room-Texture | Zero-1-to-3 | 9.860 | 0.712 | 0.406 |
| Room-Texture | Zero-1-to-3† | 8.342 | 0.657 | 0.452 |
| Room-Texture | Ours | 10.014 | 0.718 | 0.366 |
| Objaverse | ZeroNVS | 10.557 | 0.513 | 0.486 |
| Objaverse | Zero-1-to-3 | 15.850 | 0.810 | 0.259 |
| Objaverse | Zero-1-to-3† | 15.433 | 0.815 | 0.273 |
| Objaverse | Ours | 17.749 | 0.840 | 0.169 |
🔼 이 표는 다중 객체 신규 시점 합성(NVS), 객체 배치 및 교차 시점 일관성에 대한 정량적 결과를 보여줍니다. 저자들은 C3DFS 테스트 세트에서 평가를 수행했으며, Room-Texture와 Objaverse에서 일반화 실험을 추가로 진행했습니다. ‘†’ 기호는 C3DFS에서 재학습되었음을 나타냅니다. 표에는 PSNR, SSIM, LPIPS와 같은 NVS 품질 측정 지표와 객체 배치 정확도를 나타내는 IoU, 그리고 입력 시점과의 교차 시점 일관성을 평가하는 Hit Rate와 Dist. 지표가 포함되어 있습니다. 각 데이터 세트에 대해 여러 가지 방법(ZeroNVS, Zero-1-to-3, Zero-1-to-3+, Ours)의 성능을 비교하고 있습니다.
read the caption
Table 1: Quantitative results of multi-object NVS, Object Placement, and Cross-view Consistency. We evaluate on C3DFS test set, along with generalization experiments on Room-Texture [35] and Objaverse [10]. † indicates re-training on C3DFS.
In-depth insights#
Structure in NVS#
구조적 정보는 NVS의 핵심입니다. 객체 배치, 형태, 외형은 장면의 구조적 이해 없이는 정확히 재현될 수 없습니다. 본 논문은 깊이 맵과 객체 마스크를 활용하여 구조적 정보를 모델에 제공합니다. 이는 전역적 객체 배치뿐만 아니라 세부적인 객체 형상까지 학습하는 데 도움을 줍니다. 또한, 새로운 시점의 마스크 예측 보조 작업은 객체 간의 관계를 명확히 하고 일관된 시점 합성을 가능하게 합니다. 즉, 구조적 정보의 효과적인 활용이 NVS 성능 향상의 핵심 요소임을 보여줍니다.
Diffusion for Multi-Obj#
**다중 객체 신규 시점 합성(NVS)**은 단일 이미지에서 사실적인 3D 장면 이해가 부족하여 어려움을 겪습니다. 확산 모델은 단일 객체 NVS에서 성공을 거두었지만, 여러 객체로 확장하면 객체 배치, 형상 및 외관 불일치 문제가 발생합니다. MOVIS는 **구조 인식 기능(깊이 및 객체 마스크)**을 입력하여 계층적 장면 구조를 학습합니다. 또한 신규 시점 객체 마스크 예측 보조 작업은 전역 객체 배치 학습을 돕습니다. 구조 기반 timestep 샘플링 스케줄러를 통해 세부적인 형상 복구가 가능합니다. MOVIS는 기존 지표보다 교차 시점 일관성과 일반화 능력에서 우수한 성능을 보여줍니다.
Cross-View Consistency#
**교차 뷰 일관성(Cross-View Consistency)**은 단일 이미지에서 새로운 시점의 장면을 생성하는 NVS(Novel View Synthesis)에서 핵심적인 과제입니다. 이는 생성된 여러 시점의 이미지들이 서로 일관된 장면을 묘사해야 함을 의미합니다. 다시 말해, 물체의 모양, 위치, 그리고 상대적인 관계가 모든 시점에서 변함없이 유지되어야 합니다. 이러한 일관성을 확보하는 것은 어려운 문제인데, 2D 이미지에서 3D 장면에 대한 완벽한 정보를 얻을 수 없기 때문입니다. 특히, 가려짐(occlusion)이나 빛과 그림자의 변화와 같은 요소들이 교차 뷰 일관성을 유지하는 데 어려움을 더합니다. 본 논문에서는 이러한 문제를 해결하기 위해 구조 인식 기능(structure-aware features)을 활용하고, 새로운 시점 마스크 예측(novel view mask prediction)을 보조 작업으로 사용하는 방법을 제안합니다. 또한, **구조 기반 타임스텝 샘플링 스케줄러(structure-guided timestep sampling scheduler)**를 통해 전역 객체 배치 학습과 세부적인 디테일 복구 학습 사이의 균형을 맞춥니다. 실험 결과, 제안된 방법은 기존 방법들보다 교차 뷰 일관성 측면에서 우수한 성능을 보였습니다. 이는 NVS에서 사실적이고 일관된 새로운 시점의 이미지 생성에 중요한 의미를 갖습니다.
Timestep Sampling#
시간 단계 샘플링은 확산 모델에서 학습 과정을 제어하는 중요한 요소입니다. 이 연구에서는 다중 객체 NVS 작업의 복잡성을 고려하여 구조 유도 시간 단계 샘플링 스케줄러를 제안합니다. 초기 단계에서는 더 큰 시간 단계를 우선시하여 전역 객체 배치 학습에 중점을 두고, 이후 단계에서는 점차 시간 단계를 줄여 세밀한 객체 형상 및 외관 복구에 집중합니다. 이 설계는 전역 구조와 국소 세부 사항 간의 균형을 맞춰 일관된 객체 배치, 형상 및 외관을 가진 사실적인 이미지를 생성하는 데 중요한 역할을 합니다. 즉, 샘플링 스케줄러를 조정함으로써 확산 모델이 다중 객체 장면의 계층적 구조를 효과적으로 학습할 수 있도록 합니다.
NVS Limitations#
다중 객체 NVS의 한계점: 첫째, 입력 뷰 이미지와 교차 뷰 일관성이 향상되었지만 합성된 이미지 간의 다중 뷰 일관성은 보장되지 않습니다. 모호한 영역에서는 어떤 결과든 합성될 수 있으므로 다중 뷰 불일치가 발생할 수 있습니다. 다중 뷰 인식 기술을 통합하면 이 문제를 완화할 수 있습니다. 둘째, 실제 배경 텍스처를 현실적으로 모방하기 어려워 프레임워크에서 배경 텍스처를 모델링하지 않습니다. 따라서 실제 이미지에 이 방법을 직접 적용하는 것이 덜 편리합니다. 배경이 있는 더 사실적인 데이터에 대한 교육을 통해 모델을 더욱 편리하게 사용할 수 있습니다.
More visual insights#
More on figures

🔼 MOVIS는 입력 이미지와 상대적인 카메라 변화를 기반으로 새로운 시점 합성(NVS)을 수행합니다. 깊이 및 객체 마스크와 같은 구조 인식 기능이 추가 입력으로 활용되며, 객체 배치 학습을 보조하기 위해 보조 작업으로 마스크 예측을 사용합니다. 구조 기반 타임스텝 샘플링 스케줄러를 통해 전역 객체 배치와 국부적 세부 사항 복구 간의 학습 균형을 맞춥니다. 그림은 입력 이미지, 뷰, 깊이, 마스크, VAE, 노이즈 추가, UNet 디노이저, 투영, 예측된 뷰, 예측된 마스크 및 확산 훈련 목표를 포함한 MOVIS의 전체 아키텍처를 보여줍니다.
read the caption
Figure 2: Overview of MOVIS. Our model performs NVS from the input image and relative camera change. We introduce structure-aware features as additional inputs and employ mask prediction as an auxiliary task (Sec. 3.2). The model is trained with a structure-guided timestep sampling scheduler (Fig. 3) to balance the learning of global object placement and local detail recovery.

🔼 이 그림은 노이즈 제거 과정 중 다양한 timestep에서 예측된 이미지와 마스크 이미지를 시각화하여 timestep t가 전역 배치 정보와 국부적 세부 정보 학습의 균형을 맞추는 데 중요한 역할을 한다는 것을 보여줍니다. w/ shift로 훈련된 모델은 마스크 예측 성능이 더 뛰어나므로 더 자세하고 선명한 객체 경계를 가진 이미지를 복구합니다. 이는 노이즈 제거의 초기 단계에서는 전역 객체 배치 복원에 초점을 맞추고, 후기 단계에서는 객체 마스크 예측 및 세부적인 기하학적 구조와 외관 복구에 초점을 맞추는, 균형 잡힌 timestep 샘플링 스케줄러를 사용해야 할 필요성을 강조합니다. w/o shift는 μ 값을 이동하지 않는다는 의미입니다.
read the caption
Figure 3: Visualization of inference. The early stage of the denoising process focuses on restoring global object placements, while the prediction of object masks requires a relatively noiseless image to recover fine-grained geometry. This motivates us to seek a balanced timestep sampling scheduler during training. The model trained w/ shift yields better mask prediction and thus recovers an image with more details and sharp object boundary. The w/o shift here refers to not shifting the μ𝜇\muitalic_μ value.

🔼 이 그림은 MOVIS가 다양한 데이터셋에서 새로운 시점의 이미지를 생성하고, 입력 시점 이미지와 비교하여 정확한 객체 배치, 형태, 외관을 보여주는 것을 나타냅니다. 또한, 교차 시점 매칭에서 정확한 위치를 가진 더 많은 매칭 포인트를 달성하는 것을 보여줍니다.
read the caption
Figure 4: Qualitative results of NVS and cross-view matching. Our method generates plausible novel-view images across various datasets, surpassing baselines regarding object placement, shape, and appearance. In cross-view matching, points of the same color indicate correspondences between the input and target views. We achieve a higher number of matched points with more precise locations.

🔼 이 그림은 MOVIS 모델의 ablation study 결과를 보여줍니다. mask 예측이나 timestep scheduler를 제거하면 모델이 물체의 위치를 학습하는 능력이 저하되는 것을 갈색 캐비닛을 통해 확인할 수 있습니다. scheduler가 없으면 물체의 위치가 부정확해지고, 깊이 또는 마스크 입력을 제거하면 공간 관계와 물체 존재에 대한 모델의 이해도가 떨어집니다. 특히, 마스크 예측을 제외하거나 scheduler 없이 학습하면 갈색 캐비닛의 방향이 잘못 표현되는 것을 확인할 수 있는데, 이는 scheduler 없이는 모델이 초기 timestep의 denoising에 집중하여 마스크 이미지 복구와 세밀한 기하학적 형태 및 외관 개선에 대한 학습이 부족하기 때문입니다. 따라서 마스크 예측과 timestep scheduler는 객체 배치, 모양, 외관과 같은 구성적 구조 정보를 학습하는 데 중요한 역할을 합니다.
read the caption
Figure 5: Qualitative comparison for ablation study. Excluding mask predictions or the scheduler reduces the model’s ability to learn object placement, as shown by the brown cabinet example.

🔼 이 그림은 서로 다른 세 가지 타임스텝 샘플링 전략을 보여줍니다. KMS는 평균값을 상수로 유지하고, LIND는 급격히 감소한 후 선형적으로 증가하며, LDC는 선형적으로 감소합니다. x축은 학습 단계를, y축은 평균값을 나타냅니다.
read the caption
Figure S.6: Illustration of different timestep sampling strategies.
🔼 이 그림은 노이즈 타임스텝 샘플링 스케줄러 전략(KMS, LIND, LDC)을 변경하면서 예측된 이미지와 마스크 이미지를 시각적으로 비교하여 보여줍니다. KMS 전략으로 예측된 이미지는 이상하고 흐릿한 색상을 나타내는 반면 LDC 전략이 LIND보다 약간 더 나은 결과를 보여줍니다. 각 전략에 대한 정량적 평가 결과는 표 S.3에 제시되어 있으며, 이 그림은 그 결과를 보완하는 시각적 비교를 제공합니다.
read the caption
Figure S.7: Comparison of different strategies. The predicted images and mask images under novel views using different strategies are visualized. We can observe that images predicted by the KMS strategy possess weird and blurry color while LDC strategy seems to be slightly better than LIND.

🔼 이 그림은 MOVIS 모델과 기준 모델(Zero-1-to-3, Zero-1-to-3+, ZeroNVS)의 새로운 시점 합성(NVS) 결과를 Room-Texture, SUNRGB-D, 3D-FRONT 데이터셋에서 시각적으로 비교하여 보여줍니다. 각 데이터셋에서 입력 이미지, 타겟 이미지, 각 모델이 예측한 이미지, 그리고 예측된 마스크 이미지가 함께 제시됩니다. 그림에서 ‘N/A’로 표시된 부분은 해당 데이터셋에 마스크 정보가 없어서 마스크 이미지를 생성하지 못했음을 나타냅니다. 이 그림은 MOVIS 모델이 다양한 데이터셋에서 기준 모델보다 더 사실적이고 일관된 새로운 시점 이미지를 생성할 수 있음을 보여주는 데 사용됩니다.
read the caption
Figure S.8: Visualized comparison on Room-Texture [35], SUNRGB-D [49], and 3D-FRONT [14].

🔼 이 그림은 SUNRGB-D와 3D-FRONT 데이터셋에서 여러 객체로 구성된 장면에 대한 연속적인 회전으로 생성된 새로운 시점 이미지들을 보여줍니다. 카메라의 위치와 각도를 다양하게 바꾸면서 사실적인 이미지들을 생성할 수 있음을 보여주고, 상위 5개의 예시는 SUNRGB-D, 하위 3개의 예시는 3D-FRONT 데이터셋을 사용했습니다.
read the caption
Figure S.9: Continuous rotation examples on SUNRGB-D and 3D-FRONT. We rotate the camera around the multi-object composites, successfully synthesizing plausible novel-view images across a wide range of camera pose variations. This first five examples are from SUNRGB-D, and the last three examples are from 3D-FRONT.

🔼 이 그림은 3D-FRONT 및 SUNRGB-D 데이터셋에 대한 교차 뷰 매칭 결과를 시각화하여 보여줍니다. 실제 이미지와 예측된 이미지 간의 매칭 포인트를 시각화했으며, 정확한 매칭 결과를 통해 강력한 교차 뷰 일관성을 확인할 수 있습니다. 3D-FRONT와 SUNRGB-D의 경우 정답 이미지가 없기 때문에 예측된 이미지만 사용하여 교차 뷰 매칭 결과를 시각화했습니다.
read the caption
Figure S.10: Visualized cross-view matching results. Since we do not have ground truth image for 3D-FRONT and SUNRGB-D, we only visualize cross-view matching results using our predicted images. But we can still observe a strong cross-view consistency from the accurate matching results.

🔼 이 그림은 MOVIS 모델이 섬세한 구조나 질감을 가진 물체에 대해서는 세밀한 일관성을 학습하는 데 어려움을 겪는 실패 사례를 보여줍니다. 예를 들어 소파의 화려한 쿠션이나 의자의 가느다란 다리와 같은 부분은 모델이 학습하기 어려워합니다. 물체 배치는 대략적으로 정확하지만, 이러한 경우 세밀한 부분의 일관성은 이상적이지 않습니다. 고해상도 학습과 에피폴라 제약 조건을 통합하면 이 문제가 완화될 것으로 예상됩니다.
read the caption
Figure S.11: Failure Cases. It is hard for our model to learn extremely fine-grained consistency on objects with delicate structure and texture.

🔼 이 그림은 MOVIS 모델의 폐색 합성 기능을 보여줍니다. (a)에서는 소파와 캐비닛의 강조된 영역에서 볼 수 있듯이 새로운 시점에서 가려진 부분을 합성할 수 있습니다. 즉, 입력 시점에서는 가려져 보이지 않던 부분이 새로운 시점에서는 보이도록 합성할 수 있습니다. (b)에서는 의자의 강조된 영역에서 볼 수 있듯이 새로운 시점에서 가려진 물체의 부분을 복원할 수 있습니다. 즉, 입력 시점에서는 완전히 보이던 물체가 새로운 시점에서는 일부분이 가려지는 경우, 가려진 부분을 추론하여 합성할 수 있다는 것을 의미합니다. 이는 모델이 다중 객체의 배치 및 상호 작용을 어느 정도 이해하고 있음을 시사합니다.
read the caption
Figure S.12: Occlusion Synthesis Capability. Our proposed method can synthesize new occlusion relationship under novel views as shown in the highlighted area of sofa or cabinet in (a). Our method can also hallucinate occluded parts as shown in the highlighted area of chairs in (b).

🔼 이 그림은 객체 제거 기능을 보여줍니다. 예측된 마스크 이미지에 임계값을 설정하여 특정 객체를 제거할 수 있습니다. 입력 이미지와 예측된 이미지, 그리고 객체가 제거된 이미지를 비교하여 제거 기능이 어떻게 작동하는지 시각적으로 확인할 수 있습니다. 침대와 탁자를 각각 제거하는 두 가지 예시가 제시되어 있습니다.
read the caption
Figure S.13: Object Removal Example. We can remove an object under novel views by setting a threshold to the predicted mask image and delete corresponding pixels.

🔼 이 그림은 DUSt3R을 사용한 3D 재구성 결과를 보여줍니다. 여러 각도에서 예측된 이미지와 입력 뷰 이미지를 함께 사용하여 여러 개체로 구성된 장면을 재구성합니다. 주어진 입력 뷰 이미지와 여러 예측된 뷰 이미지를 사용하여 DUSt3R을 통해 장면의 3D 모델을 재구성합니다. 그림은 다양한 각도에서 렌더링된 재구성된 장면을 보여주며, 모델이 장면의 3D 구조를 이해하고 일관된 여러 뷰를 생성할 수 있음을 나타냅니다.
read the caption
Figure S.14: Reconstruction results using DUSt3R. We rotate our camera around the multi-object composite and use the predicted images along with the input-view image for reconstruction.

🔼 이 그림은 C3DFS 데이터셋에 대한 추가적인 시각화 결과를 보여줍니다. 입력 이미지, 예측된 이미지, 목표 이미지, 마스크 이미지가 순서대로 제시되어 있습니다. 이 그림은 모델이 다양한 입력 이미지에 대해 새로운 시점의 이미지와 마스크를 얼마나 잘 예측하는지 보여주는 데 사용됩니다.
read the caption
Figure S.15: More visualized results on C3DFS dataset.
More on tables
| Method | Novel View Synthesis | Placement |
|---|---|---|
| PSNR(↑) | SSIM(↑) | |
| w/o depth | 17.080 | 0.819 |
| w/o mask | 16.914 | 0.818 |
| w/o sch. | 16.166 | 0.808 |
| Ours | 17.432 | 0.825 |
🔼 C3DFS 데이터셋에서 다양한 ablation study에 대한 정량적 평가 결과를 표시합니다. 각 ablation study는 깊이 입력 제거 (w/o depth), 마스크 예측 보조 작업 제거 (w/o mask), 스케줄러 제거 (w/o sch.) 등 주요 구성 요소의 효과를 평가합니다. 각 설정에 대해 PSNR, SSIM, LPIPS 및 IoU를 포함한 새로운 뷰 합성 및 배치 품질 메트릭이 보고됩니다. 이 표는 각 구성 요소의 영향을 강조하여 모델 성능에 대한 기여도를 보여줍니다.
read the caption
Table 2: Ablation results on C3DFS.
| Dataset | Method | Novel View Synthesis | ||
|---|---|---|---|---|
| PSNR(↑) | SSIM(↑) | LPIPS(↓) | ||
| C3DFS | w/o sch. | 16.166 | 0.808 | 0.212 |
| KMS | 17.148 | 0.823 | 0.175 | |
| LIND | 17.279 | 0.824 | 0.172 | |
| LDC | 17.432 | 0.825 | 0.171 |
🔼 이 표는 노이즈 타임스텝 샘플링 스케줄러 전략에 대한 ablation study 결과를 보여줍니다. 균일 샘플러(w/o sch.), KMS, LIND, LDC 네 가지 전략을 비교합니다. 노이즈 타임스텝 샘플링 전략을 통합하면 모델 성능이 크게 향상되며, 그 중 선형 감소(LDC) 전략이 가장 좋은 성능을 보입니다.
read the caption
Table S.3: Ablation on different strategies. Incorporating sampling strategies significantly improves the model performance, while the linear decline (LDC) achieves the best.
| C3DFS | Room-Texture | Objaverse | SUNRGB-D | 3D-FRONT | |
|---|---|---|---|---|---|
| depth | ✓ | × | ✓ | × | × |
| mask | ✓ | ✓ | ✓ | × | × |
🔼 이 표는 다양한 데이터셋에서 깊이 맵과 마스크 조건의 사용 가능 여부를 보여줍니다. C3DFS, 3D-FRONT, Objaverse는 깊이 맵과 마스크 정보를 모두 제공하지만 Room-Texture와 SUNRGB-D는 제공하지 않습니다. 따라서 Room-Texture와 SUNRGB-D의 경우, 저자들은 DepthFM[15]과 SAM[23]을 사용하여 깊이 맵과 객체 마스크를 추출합니다. MOVIS는 입력 보기의 깊이 맵과 마스크 이미지를 추가 조건으로 사용합니다. 깊이 맵은 객체의 대략적인 상대적 위치와 모양을 인코딩하고, 마스크는 객체 배치 및 모양의 대략적인 개념을 제공할 뿐만 아니라 고유한 객체 인스턴스를 구별하는 데 사용됩니다.
read the caption
Table S.4: Availability of conditions in different datasets.
| Dataset | Method | Novel View Synthesis | Placement | Cross-view Consistency |
|---|---|---|---|---|
| PSNR(↑) | SSIM(↑) | LPIPS(↓) | ||
| C3DFS | w/o depth | 17.080 | 0.819 | 0.178 |
| w/o mask | 16.914 | 0.818 | 0.187 | |
| w/o sch. | 16.166 | 0.808 | 0.212 | |
| Ours | 17.432 | 0.825 | 0.171 | |
| Room-Texture | w/o depth | 9.829 | 0.705 | 0.365 |
| w/o mask | 9.576 | 0.699 | 0.384 | |
| w/o sch. | 9.173 | 0.689 | 0.392 | |
| Ours | 10.014 | 0.718 | 0.366 | |
| Objaverse | w/o depth | 17.457 | 0.835 | 0.178 |
| w/o mask | 17.176 | 0.834 | 0.187 | |
| w/o sch. | 16.642 | 0.825 | 0.210 | |
| Ours | 17.749 | 0.840 | 0.169 |
🔼 이 표는 다양한 데이터셋(C3DFS, Room-Texture, Objaverse)에서 저자들이 제안한 다중 객체 신규 시점 합성(NVS) 모델 MOVIS의 성능을 평가하고, 모델의 주요 구성 요소인 깊이 입력, 마스크 예측 보조 작업, 스케줄러의 효과를 검증하기 위해 수행한 절제 연구(ablation study) 결과를 보여줍니다. 각 데이터셋에 대해 원본 모델과 각 구성 요소를 제거한 변형 모델의 성능을 PSNR, SSIM, LPIPS, IoU, Hit Rate, Dist. 지표를 사용하여 비교합니다. 이를 통해 MOVIS 모델의 각 구성 요소가 성능에 미치는 영향을 분석하고, 다양한 데이터셋에 대한 일반화 능력을 평가합니다.
read the caption
Table S.5: Ablation study on various datasets.
| Method | Visible | Occluded | Heavily Occluded | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR(↑) | SSIM(↑) | LPIPS(↓) | PSNR(↑) | SSIM(↑) | LPIPS(↓) | PSNR(↑) | SSIM(↑) | LPIPS(↓) | ||
| — | — | — | — | — | — | — | — | — | — | — |
| Ours | 11.45 | 0.56 | 0.13 | 11.33 | 0.55 | 0.14 | 10.57 | 0.55 | 0.14 | |
| Zero-1-to-3 | 9.46 | 0.54 | 0.16 | 9.33 | 0.52 | 0.17 | 9.00 | 0.53 | 0.16 | |
| Zero-1-to-3† | 9.68 | 0.55 | 0.14 | 9.54 | 0.52 | 0.15 | 9.26 | 0.53 | 0.15 |
🔼 이 표는 가려짐 정도가 다른 물체에 대한 평가 결과를 보여줍니다. 물체는 완전히 보이는 물체, 가려진 물체, 심하게 가려진 물체 세 가지로 분류됩니다. 각 카테고리에 대해 PSNR, SSIM, LPIPS 지표를 사용하여 Zero-1-to-3, Zero-1-to-3+, 그리고 제안된 방법(Ours)의 성능을 비교합니다.
read the caption
Table S.6: Evaluation on objects with varying extents of occlusion.
Full paper#



















