↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
"""
LLM은 텍스트 생성에 탁월하지만 실제 작업 수행 능력에는 한계가 있습니다. 실제 환경에서 작업을 완료하려면
사용자의 의도 이해, 계획 수립, 필요한 작업 수행과 같은 복잡한 단계가 필요합니다. 이러한 한계를 해결하기 위해
실제 작업을 수행할 수 있는 지능형 에이전트에 대한 요구가 증가하고 있습니다.
"""
"""
본 연구에서는 **LAM(Large Action Model)**이라는 새로운 모델을 제안합니다. LAM은 LLM을 기반으로 하지만
행동 생성 및 실행에 최적화되어 있습니다. Windows OS 기반 에이전트를 사례 연구로 사용하여 데이터 수집,
모델 학습, 환경 통합, 접지 및 평가를 포함한 LAM 개발의 주요 단계에 대한 단계별 지침을 제공합니다. 또한 4단계 학습 전략(작업 계획 사전 학습, 전문가 학습, 자체 부스팅 탐색, 보상 모델 학습)을 사용하여 LAM을 효과적으로 학습하고, 오프라인 및 온라인 평가를 통해 LAM의 성능을 검증했습니다. 이를 통해 LAM이 복잡한 작업을 자동화하고 다양한 환경과 상호 작용하는 데 LLM보다 효과적임을 보여주었습니다.
"""
Key Takeaways#
Why does it matter?#
""" LAM은 실제 애플리케이션에 중요한 영향을 미치며, 대규모 언어 모델을 넘어 액션 생성으로 패러다임 전환을 나타냅니다. 본 연구는 새로운 연구 방향을 제시하고, 실제 환경에서 복잡한 작업을 자동화할 수 있는 에이전트 개발을 위한 실질적인 프레임워크를 제공하며, AGI를 향한 중요한 진전을 보여줍니다. 이는 AI 연구에 있어서 중요한 이정표를 세우며, 다양한 분야에서 LAM의 잠재력과 실용적인 활용을 탐구할 수 있는 새로운 길을 열어줍니다. 또한 Windows OS 기반 에이전트와 같은 구체적인 사례 연구를 통해 실제 적용 가능성을 보여줍니다. """
Visual Insights#

🔼 이 그림은 기존의 대규모 언어 모델(LLM)에서 대규모 행동 모델(LAM)으로의 전환 과정을 보여줍니다. LLM은 사용자 쿼리에 대한 텍스트 응답을 생성하는 데 중점을 두는 반면, LAM은 작업 요청을 받아 에이전트를 통해 환경과 상호 작용하여 텍스트 및 에이전트 작업 출력을 생성합니다. LLM에서 LAM으로 전환하려면 미세 조정과 계획 궤적이 필요합니다.
read the caption
Figure 1. The transition from LLMs to LAMs.
| Model | Data Type | Data Source | Input → Output Format | Data Size |
|---|---|---|---|---|
| LAM¹ | Task-Plan Pairs | Application documentation, WikiHow, historical search queries, evolved data | tᵢ → Pᵢ | 76,672 tasks |
| LAM² | Task-Action Trajectories | GPT-4o | sₜ → aₜ | 2,192 trajectories |
| LAM³ | Task-Action Trajectories | LAM² + GPT-4o | sₜ → aₜ | 2,688 trajectories |
| LAM⁴ | Task-Action-Reward Trajectories | RM + LAM³ | (sₜ,rₜ) → aₜ | 1,788 trajectories |
| Reward Model | Task-Action-Reward Trajectories | GPT-4o + LAM³ | (sₜ,aₜ) → rₜ | 4,476 trajectories |
🔼 이 표는 LAM 교육의 각 단계에 대한 교육 데이터 요약을 제공합니다. LAM¹은 작업 계획 쌍을 사용하여 교육되고, LAM² 및 LAM³는 작업-행동 궤적을 사용하여 교육되며, LAM⁴와 보상 모델은 작업-행동-보상 궤적을 사용하여 교육됩니다.
read the caption
Table 1. Training data summary for each phase of LAM training.
In-depth insights#
LAM Framework#
LAM (Large Action Model) 프레임워크는 전통적인 LLM의 한계를 극복하기 위해 실제 환경에서의 행동 생성 및 실행에 중점을 둡니다. 핵심은 행동이며, 사용자 의도를 파악하여 작업 계획을 수립하고 이를 실행 가능한 행동 시퀀스로 변환하는 과정이 중요합니다. 이 프레임워크는 데이터 수집, 모델 훈련, 환경 통합, 그라운딩 및 평가의 5단계로 구성됩니다. 특히 Windows OS 기반 에이전트를 통해 실제 애플리케이션에서의 구현 및 평가 방법을 제시하며, 단계별 접근 방식은 다른 환경에도 일반화될 수 있는 청사진을 제공합니다. LAM은 실세계 애플리케이션에서 자동화 및 인간 능력 증강을 위한 잠재력을 가지고 있지만, 안전, 윤리, 확장성, 일반화 및 적응성 측면에서 해결해야 할 과제가 남아 있습니다.
Action-Oriented Data#
행동 지향 데이터는 AI 모델, 특히 대규모 언어 모델(LLM)을 실제 환경에서 작업을 수행할 수 있도록 훈련하는 데 중점을 둡니다. 이 데이터는 사용자 요청, 환경 상태 및 해당 작업을 캡처하는 구체적인 작업 및 계획으로 구성됩니다. 단순히 텍스트를 생성하는 대신, 행동 지향 데이터는 모델이 실제 애플리케이션에서 실질적인 결과를 가져오는 데 필요한 단계별 지침을 제공합니다. 이러한 데이터의 품질, 정확성 및 관련성은 LLM의 효율성과 효과에 매우 중요합니다. 행동 지향 데이터는 작업 완료율을 높이고 보다 강력하고 적응력 있는 AI 시스템으로 이어집니다.
Phased LAM Training#
단계별 LAM 훈련은 복잡한 작업 완료를 위한 효율적인 LAM 개발을 목표로 합니다. 이 전략은 구조화된 작업 계획 학습, 전문가 데모 모방, 자체 성공으로부터의 자체 부스팅, 보상 기반 최적화를 포함한 네 가지 주요 단계를 포함합니다. 1단계에서는 작업 계획 사전 훈련을 통해 모델에 작업을 논리적 단계로 분해하는 방법을 교육하여 기본 계획 능력을 제공합니다. 2단계에서는 GPT-40에서 레이블이 지정된 작업-행동 궤적을 도입하여 LAM이 계획 생성을 실행 가능한 단계에 맞춰 조정합니다. 3단계에서는 자체 부스팅 탐색을 통해 모델이 GPT-40조차 해결하지 못한 작업을 처리하도록 장려하여 새로운 성공 사례를 자율적으로 생성하고 적응성을 향상시킵니다. 마지막으로 4단계에서는 보상 기반 미세 조정을 통합하여 LAM이 성공과 실패 모두에서 학습하여 복잡하고 이전에 볼 수 없었던 시나리오에서 의사 결정을 개선합니다. 각 단계는 이전 단계를 기반으로 하여 정적 지식과 전문가 데모, 자체 안내 탐색 및 보상 기반 개선을 결합하여 다양하고 복잡한 작업을 처리할 수 있는 강력하고 적응력 있는 모델을 보장합니다.
GUI Agent Integration#
GUI 에이전트 통합은 언어 모델을 실제 애플리케이션과 연결하는 중요한 단계입니다. 이 통합을 통해 사용자는 자연어를 사용하여 복잡한 작업을 수행할 수 있습니다. GUI 에이전트는 사용자 요청을 해석하고, 애플리케이션의 GUI 요소와 상호 작용하며, 실시간 피드백을 기반으로 작업을 조정합니다. 이 과정에는 몇 가지 중요한 측면이 있습니다. 첫째, 사용자 의도 파악: 에이전트는 사용자의 자연어 요청을 정확하게 이해하고 작업 목표를 추출해야 합니다. 둘째, GUI 요소 인식: 에이전트는 애플리케이션의 GUI 요소를 식별하고 분류하여 상호 작용할 대상을 결정해야 합니다. 셋째, 작업 계획 및 실행: 에이전트는 작업을 완료하기 위한 일련의 단계를 계획하고 실행해야 합니다. 넷째, 피드백 및 적응: 에이전트는 환경의 변화와 사용자 피드백을 기반으로 작업을 조정하고 개선해야 합니다. 마지막으로, 다양한 애플리케이션 지원: 에이전트는 다양한 애플리케이션 및 플랫폼과 호환되어야 하며 새로운 애플리케이션에 대한 적응성이 높아야 합니다. 이러한 측면을 고려하여 GUI 에이전트를 효과적으로 통합하면 사용자 경험을 향상시키고 다양한 작업을 자동화할 수 있습니다.
Safety and Ethics#
안전 및 윤리적 문제는 LAM 개발 및 배포에서 핵심 고려 사항입니다. LAM이 실제 환경과 상호 작용하고 작업을 수행하는 능력은 잠재적인 이점을 제공하지만, 오류 또는 악의적인 사용으로 인해 예상치 못한 결과가 발생할 수 있습니다. 안전 위험 완화에는 엄격한 테스트, 검증 및 안전 메커니즘이 포함됩니다. 윤리적 고려 사항에는 공정성, 투명성, 책임성 확보, 데이터 편향 방지 및 잠재적 오용 방지가 포함됩니다. 규제 프레임워크와 윤리적 지침을 개발하면 LAM이 책임감 있게 사용되도록 보장하는 데 도움이 될 수 있습니다. 이러한 문제를 해결하면 LAM을 광범위하게 채택하고 실제 애플리케이션에서 잠재력을 최대한 발휘할 수 있습니다.
More visual insights#
More on figures

🔼 이 그림은 LLM과 LAM의 주요 차이점을 보여줍니다. LLM은 사용자의 ‘남성용 재킷 구매’ 요청에 대해 온라인 쇼핑 웹사이트를 열고, ‘남성용 재킷’을 검색하고, 모든 재킷을 살펴보는 단계별 계획을 생성할 수 있습니다. 그러나 LLM은 실제로 웹사이트와 상호 작용하여 구매를 완료할 수는 없습니다. 반면, LAM은 계획의 각 단계를 작업 가능한 단계로 변환하여 웹사이트를 탐색하고, 항목을 선택하고, 구매를 완료하는 등의 작업을 수행합니다.
read the caption
Figure 2. The objective difference between LLMs and LAMs.

🔼 이 그림은 LAM 개발 및 구현을 위한 프로세스 파이프라인을 보여줍니다. 5단계로 구성되어 있습니다. 1단계: 데이터 수집 및 준비, 2단계: 모델 학습, 3단계: 오프라인 평가, 4단계: 통합 및 접지, 5단계: 온라인 평가. 각 단계는 LAM을 개발하고 실제 환경에 배포하는 데 필요한 구체적인 활동과 절차를 나타냅니다.
read the caption
Figure 3. The process pipeline for LAM development and implementation.
🔼 이 그림은 두 단계로 구성된 데이터 수집 및 준비 과정을 보여줍니다. 1단계는 작업-계획 데이터 수집 단계이고, 2단계는 작업-행동 데이터 수집 단계입니다. 1단계에서는 작업과 그에 대응하는 계획을 수집하고, 2단계에서는 1단계에서 수집된 작업-계획 데이터를 기반으로 실제 환경에서 실행 가능한 작업-행동 데이터를 생성합니다. 그림에서 각 단계의 입력과 출력, 그리고 사용되는 도구 및 환경이 시각적으로 표현되어 있습니다.
read the caption
Figure 4. The two-phrase data collection and preparation process.

🔼 이 그림은 작업 계획 데이터를 구성하기 위한 파이프라인을 보여줍니다. 애플리케이션 문서, WikiHow, 과거 검색 쿼리와 같은 다양한 소스에서 원시 데이터를 수집하는 것으로 시작합니다. 그런 다음 데이터 추출 및 전처리 단계를 거쳐 관련 없는 정보를 필터링하고 데이터를 표준화합니다. 마지막으로 GPT를 사용하여 작업 계획 데이터를 구조화된 JSON 형식으로 구성합니다.
read the caption
Figure 5. The pipeline to construct the task plan data.

🔼 작업-계획 데이터를 작업-액션 데이터로 변환하고 수집하는 파이프라인을 보여줍니다. 초기 단계에서는 작업-계획 데이터를 사용하여 작업을 구체화하고 실행 가능한 궤적을 생성합니다. 그런 다음 이 궤적을 실제 애플리케이션 환경에서 실행하고, 스크린샷과 환경 변화를 기록합니다. LLM을 사용하여 실행된 궤적을 평가하고, 성공적인 작업-액션 궤적을 처리하여 LAM 교육을 위한 데이터를 생성합니다.
read the caption
Figure 6. The pipeline of task-action data conversion and collection.

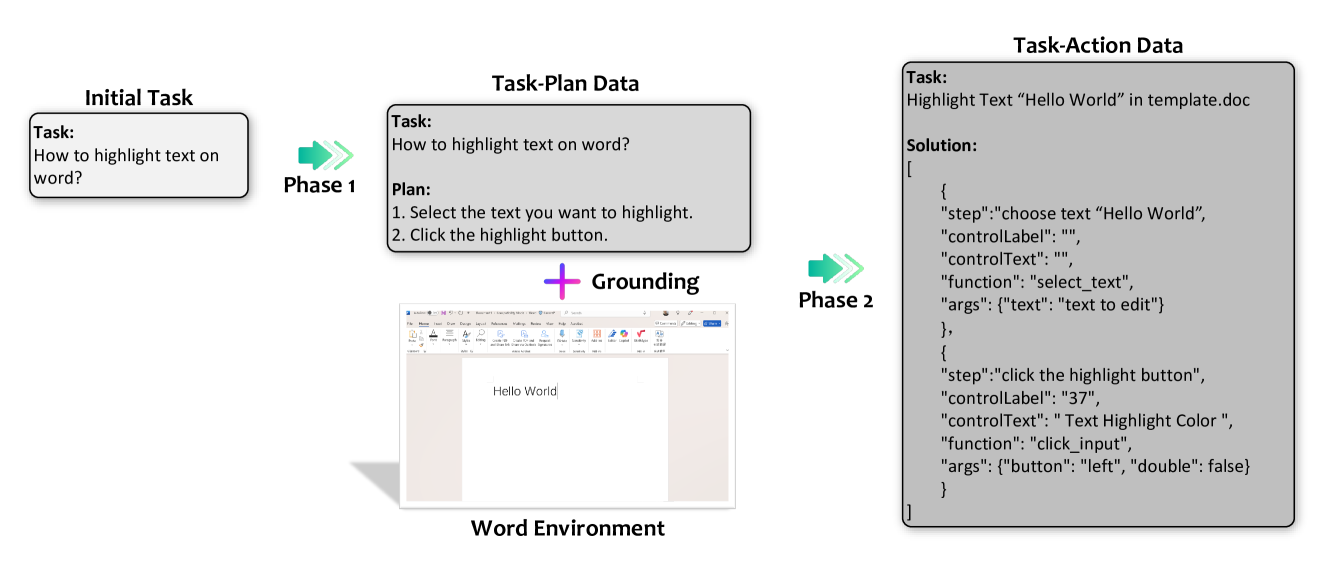
🔼 이 그림은 작업 인스턴스화의 예시를 보여줍니다. 작업-계획 데이터를 작업-행동 데이터로 변환하는 과정에서 작업 설명이 구체적인 대상과 관련 함수로 인스턴스화되는 방법을 자세히 보여줍니다. 예를 들어, ‘문서에서 텍스트 강조 표시’와 같은 작업은 ‘템플릿.doc에서 ‘Hello World’ 텍스트 강조 표시’로 인스턴스화될 수 있습니다. 이 인스턴스화는 작업을 더 구체적이고, 행동 가능하며, 애플리케이션 환경에 맞춰줍니다. 그림에는 작업 설명, 워드 템플릿, 함수 풀 및 결과 작업-행동 데이터가 포함되어 있습니다. 이것은 작업 인스턴스화의 중요한 단계를 보여주는 것으로, 계획에서 실행으로의 전환을 가능하게 합니다.
read the caption
Figure 7. An example of task instantiation.

🔼 LAM 교육 파이프라인은 네 단계로 구성됩니다. 1단계(작업 계획 사전 훈련)에서는 모델이 작업에 대한 일관된 단계별 계획을 생성하도록 합니다. 2단계(전문가 학습)에서는 GPT-40으로 레이블이 지정된 작업-행동 궤적을 도입하여 LAM이 실행 가능한 단계로 계획 생성을 조정하도록 합니다. 3단계(자가 부스팅 탐색)에서는 모델이 GPT-40이 해결하지 못한 작업을 자율적으로 처리하고 새로운 성공 사례를 생성하여 적응력을 개선합니다. 마지막으로 4단계(보상 모델 학습)에서는 강화 학습(RL) 원칙을 통합하여 LAM이 성공과 실패 모두에서 학습하고 복잡하고 이전에 보지 못했던 시나리오에서 의사 결정을 개선합니다.
read the caption
Figure 8. The overview of LAM training pipeline.

🔼 UFO는 Windows OS와의 상호 작용을 위해 설계된 UI 중심 에이전트입니다. AppAgent는 사용자 요청을 하위 작업으로 분해하는 HostAgent와 개별 애플리케이션 내에서 이러한 하위 작업을 실행하는 AppAgent라는 두 가지 주요 구성 요소로 구성되어 있습니다. 이 아키텍처는 다양한 소프트웨어 환경에서 강력한 작업 자동화를 제공하는 UFO의 기능을 향상시킵니다. 그림은 AppAgent의 전체 아키텍처를 보여줍니다. 각 추론 단계에서 에이전트는 애플리케이션 환경에서 중요한 상황 정보를 수집하여 의사 결정을 위해 LAM에 전달합니다. LAM은 계획을 수행하고 작업을 조정하며 사용자 요청을 이행하는 데 필요한 단계를 추론합니다. 추론된 이러한 작업은 마우스 클릭, 키보드 입력 또는 API 호출과 같은 에이전트가 사용하는 사전 정의된 도구 및 함수 호출에 매핑하여 환경에 기반합니다.
read the caption
Figure 9. The overall architecture of the AppAgent employed in UFO.

🔼 이 그림은 직사각형 모양이 삽입된 워드 문서 템플릿 파일을 보여줍니다. 이 템플릿 파일은 작업 계획 데이터를 작업 실행 데이터로 변환하는 인스턴스화 단계에서 사용됩니다. 템플릿 파일은 단락, 표, 그림과 같이 다양한 Word 구성 요소를 포함하며, 각 템플릿 파일에는 작업 접지에 대한 컨텍스트를 제공하는 설명이 첨부되어 있습니다.
read the caption
Figure 10. A word template file with the description “A doc with a rectangle shape.”

🔼 이 그림은 검토자와 댓글이 포함된 Word 템플릿 파일을 보여줍니다. 템플릿에는 1부터 6까지 번호가 매겨진 댓글 상자가 있으며, ‘검토자’라는 레이블이 지정된 텍스트 상자가 있습니다.
read the caption
Figure 11. A word template file with the description “A doc with comments and reviewer.”

🔼 차트가 삽입된 워드 문서 템플릿 파일입니다. 이 파일은 작업 계획 데이터를 작업 실행 데이터로 변환하는 인스턴스화 단계에서 사용됩니다. 차트는 ‘Series 1’, ‘Series 2’, ‘Series 3’ 세 가지 계열로 ‘Category 1’, ‘Category 2’, ‘Category 3’, ‘Category 4’ 네 가지 범주에 대한 데이터를 표시하고 있습니다. 차트의 제목은 ‘Chart Title’입니다.
read the caption
Figure 12. A word template file with the description “A doc with a chart.”
More on tables
| Model | TSR (%) | Step Precision (%) | Step Recall (%) |
|---|---|---|---|
| LAM¹ | 82.2 | 54.7 | 55.7 |
| GPT-4o | 84.5 | 28.2 | 66.1 |
| Mistral-7B | 0.0 | 0.1 | 0.5 |
🔼 이 표는 계획 수립에 대한 다양한 모델의 성능(%) 비교를 보여줍니다. LAM¹은 작업 계획 사전 훈련을 통해 작업에 대한 구조화된 계획을 생성하는 방법을 학습합니다. GPT-40은 텍스트 기반의 응답을 생성하지만 작업을 수행할 수 없습니다. Mistral-7B는 작업 계획 사전 훈련 없이 기본 언어 모델입니다. 평가에는 작업 성공률(TSR), 단계 정밀도, 단계 재현율과 같은 지표가 사용됩니다.
read the caption
Table 2. Performance (%) comparison of different models on planning.
| Metric | LAM¹ | LAM² | LAM³ | LAM⁴ | GPT-4o (Text-only) | GPT-4o Mini (Text-only) |
|---|---|---|---|---|---|---|
| Object Acc (%) | 39.4 | 85.6 | 87.4 | 87.8 | 73.2 | 74.6 |
| Operation Acc (%) | 59.9 | 97.3 | 97.7 | 97.7 | 94.2 | 91.5 |
| Status Acc (%) | 32.7 | 97.8 | 98.2 | 99.0 | 52.1 | 67.4 |
| Step Success Rate (SSR) (%) | 33.0 | 83.6 | 85.9 | 86.2 | 68.8 | 73.4 |
| Task Success Rate (TSR) (%) | 35.6 | 76.8 | 79.3 | 81.2 | 67.2 | 62.3 |
🔼 다양한 모델과 메트릭에 대한 오프라인 성능 비교를 제공하며, 객체 정확도, 작업 정확도, 상태 정확도, 단계 성공률, 작업 성공률 등의 메트릭을 사용하여 의사 결정에 대한 LAM¹에서 LAM⁴, 텍스트 기반 GPT-40 및 GPT-40 미니의 성능을 비교합니다. LAM 프레임워크가 GPT-40보다 더 나은 성능을 보이며, 특히 텍스트 전용 모델로서 높은 작업 성공률을 유지하면서 효율성이 뛰어남을 보여줍니다.
read the caption
Table 3. Offline performance comparison across different models and metrics on decision making.
| Metric | Text-only | Text + Visual | |||
|---|---|---|---|---|---|
| LAM | GPT-4o | GPT-4o Mini | GPT-4o | GPT-4o Mini | |
| Task Success Rate (%) | 71.0 | 63.0 | 57.8 | 75.5 | 66.7 |
| Task Completion Time (s) | 30.42 | 86.42 | 35.24 | 96.48 | 46.21 |
| Task Completion Steps | 5.62 | 6.73 | 5.99 | 4.98 | 6.34 |
| Average Step Latency (s) | 5.41 | 12.84 | 5.88 | 19.36 | 7.29 |
🔼 이 표는 LAM과 기준 모델(GPT-40, GPT-40 Mini)의 성능을 작업 성공률, 작업 완료 시간, 작업 완료 단계, 평균 단계 지연 시간 측면에서 비교하여 보여줍니다. 텍스트 전용 입력과 텍스트 및 시각 입력 모두에 대한 결과를 표시하고, LAM이 텍스트 전용 모델로서 정확도와 효율성 측면에서 경쟁력 있는 성능을 보여주는 것을 강조합니다.
read the caption
Table 4. Performance comparison of LAM and baseline models across metrics.
Full paper#



















