↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
텍스트-투-비디오 생성은 콘텐츠 제작에 혁신을 가져왔지만, 높은 계산 복잡도가 걸림돌입니다. Diffusion Transformer(DiT)는 픽셀 수의 제곱에 비례하는 계산 비용으로 인해 긴 영상 생성에 어려움을 겪고 있어 대부분의 모델은 10~20초 길이의 짧은 비디오만 생성할 수 있습니다. 게다가 Mamba 기반 모델은 인접성 보존 문제로 인해 생성된 비디오의 일관성이 떨어지는 단점이 있었습니다.
이러한 문제를 해결하기 위해 본 논문은 선형 복잡도의 LinGen 프레임워크를 제안합니다. LinGen은 픽셀 수에 비례하는 계산 비용으로 고해상도의 분 단위 길이 비디오 생성을 단일 GPU에서 가능하게 합니다. 핵심은 자기-주의 계층을 MATE 블록으로 대체하는 것으로, MATE는 MA-브랜치와 TE-브랜치로 구성됩니다. MA-브랜치는 양방향 Mamba2 블록과 함께 단거리-장거리 상관관계를 효과적으로 처리하며, TE-브랜치는 새로운 Temporal Swin Attention(TESA) 블록을 통해 인접성 보존 문제를 해결하고 비디오 일관성을 향상시킵니다. 실험 결과, LinGen은 DiT보다 최대 15배 빠른 속도로 비디오를 생성하며, 최신 모델들과 비슷한 수준의 고품질 비디오를 생성합니다.
Key Takeaways#
Why does it matter?#
텍스트-투-비디오 생성 분야에서 계산 복잡도를 획기적으로 줄이는 연구로, 긴 고해상도 비디오 생성을 단일 GPU에서 가능하게 합니다. Mamba 기반 모델의 인접성 보존 문제를 해결하고, 실시간 비디오 생성 및 장시간 영화 제작 가능성을 높여 관련 연구에 큰 영향을 미칩니다.
Visual Insights#

🔼 LinGen은 선형 계산 복잡도를 사용하여 사실적인 고해상도 장시간 비디오를 생성합니다. (a) LinGen 모델을 사용하여 생성된 고품질 비디오입니다. (b) 다양한 비디오 해상도와 길이에 따른 계산 비용 증가 곡선입니다. LinGen은 512p 해상도에서 68초 길이의 비디오를 생성할 때 표준 DiT에 비해 최대 15배의 속도 향상을 달성합니다.
read the caption
Figure 1: LinGen generates photorealistic high-resolution long videos with linear computational complexity. (a) High-quality videos generated using our LinGen model. (b) The computational cost scaling curves across different video resolutions and lengths. LinGen achieves 15×\times× speed-up compared to the standard DiT when generating 68s-length videos at 512p resolution.
| Model | Subject Consist. | BG. Consis. | Temp. Flick. | Motion Smooth. | Aesthe. Quality | Imag. Quality | Dyna. Degree | Quality Score | Total Score | Max. Raw Frames |
|---|---|---|---|---|---|---|---|---|---|---|
| Runway Gen-3 [47] | 97.10% | 96.62% | 98.61% | 99.23% | 60.14% | 63.34% | 66.82% | 84.11% | 82.32% | 256 |
| Kling [24] | 98.33% | 97.60% | 99.30% | 99.40% | 46.94% | 61.21% | 65.62% | 83.39% | 81.85% | 313 |
| OpenSora V1.2 [75] | 96.75% | 97.61% | 99.53% | 98.50% | 42.39% | 56.85% | 63.34% | 81.35% | 79.76% | 408 |
| LinGen | 98.30% | 97.60% | 99.26% | 98.58% | 63.67% | 60.55% | 63.36% | 83.77% | 81.76% | 1088 |
🔼 VBench-Long 벤치마크에서 LinGen, Runway Gen-3, Kling, OpenSora V1.2 모델의 비디오 생성 품질(Quality Score), 텍스트-비디오 정합성(Semantic Score), 종합 점수(Total Score), 그리고 최대 생성 가능한 원시 프레임 수를 비교한 표입니다. LinGen은 상용 SOTA 모델과 비슷한 품질을 보여주면서, 오픈소스 모델보다 훨씬 뛰어난 성능을 달성했고, 특히 단일 GPU에서 더 많은 원시 프레임을 생성할 수 있다는 점에서 효율성이 돋보입니다.
read the caption
Table 1: Automatic evaluation of LinGen on VBench-Long. Quality Score measures the quality of generated videos and Semantic Score measures text-video alignment. Total Score is their weighted sum. Higher values indicate better performance for all these metrics. LinGen is comparable to state-of-the-art commercial models (i.e., Gen-3 and Kling) and outperforms the typical open-source model (i.e., OpenSora) significantly. LinGen not only achieves a much higher maximum number of raw frames but also does so on a single GPU.
In-depth insights#
LinGen: Linear Video#
LinGen: Linear Video는 긴 영상 생성의 계산 복잡도 문제를 해결하는 혁신적인 프레임워크입니다. 기존 DiT 모델의 2차 복잡도를 선형 복잡도로 줄여 고해상도의 긴 영상 생성을 가능하게 합니다. 핵심은 MATE 블록으로, MA-브랜치는 단거리 및 장거리 상관관계를, TE-브랜치는 인접 토큰 간의 상관관계를 효율적으로 처리합니다. 이를 통해 Mamba 모델의 한계점인 인접성 보존 문제를 해결하고 영상의 일관성을 크게 향상시킵니다. 실험 결과, LinGen은 DiT보다 최대 15배 빠른 속도로 분 단위 길이의 고품질 영상을 생성합니다. 이는 실시간 상호작용 영상 생성과 영화 제작 등 다양한 분야에 혁신을 가져올 잠재력을 가지고 있습니다.
Mamba2 & Adjacency#
Mamba2는 선형 복잡도를 제공하지만 인접성 보존 문제가 있습니다. 2D 또는 3D 토큰을 1D 시퀀스로 재정렬하면 공간적, 시간적으로 인접한 토큰이 멀리 떨어져 있습니다. 이는 Mamba2의 장거리 상관관계 계산의 고유한 감쇠로 인해 생성된 비디오의 품질에 영향을 미칩니다. 인접 토큰 간의 상관관계가 제대로 캡처되지 않아 일관성이 떨어지고 왜곡이 발생할 수 있습니다. 이 문제를 해결하기 위해 LinGen은 회전-주요 스캔(RMS) 및 검토 토큰과 같은 추가 메커니즘을 사용합니다. RMS는 다양한 차원에서 인접성을 유지하기 위해 서로 다른 레이어에서 다양한 스캔 일정을 적용합니다. 검토 토큰은 시퀀스 처리가 시작되기 전에 Mamba2 블록에 시퀀스 개요를 제공하여 장거리 상관관계를 보정합니다. 이러한 기술을 통해 LinGen은 Mamba2의 효율성을 활용하면서 인접성 보존 문제를 완화하여 고품질의 일관된 비디오를 생성합니다.
MATE: Attn Block#
MATE는 DiT의 self-attention을 대체하는 선형 복잡도 어텐션 블록입니다. MA-branch는 Mamba2, RMS, review 토큰으로 단-중-장거리 상관관계를 처리합니다. TE-branch는 TESA 블록으로 인접 토큰 및 중거리 토큰 간의 시간적 상관관계에 집중하여 영상 일관성을 향상시킵니다. MATE는 Mamba의 인접성 보존 문제를 해결하고 선형 복잡도를 유지하며 상관관계를 종합적으로 개선합니다.
Minute-Long Hi-Res#
분 단위 길이의 고해상도 비디오 생성은 엄청난 계산 복잡성으로 인해 어려운 과제입니다. 기존 모델은 짧은 비디오나 저해상도 출력으로 제한됩니다. LinGen은 이러한 한계를 해결하기 위해 선형 계산 복잡도를 제공하는 프레임워크를 제안하며, 픽셀 수에 따라 선형적으로 확장됩니다. LinGen은 품질 저하 없이 단일 GPU에서 분 단위 길이의 고해상도 비디오 생성을 가능하게 합니다. MATE 블록을 통해 이러한 효율성을 달성하는데, 이 블록은 단거리 및 장거리 상관관계를 모두 처리하는 MA 브랜치와 인접성 보존 문제를 해결하여 비디오 일관성을 향상시키는 TE 브랜치로 구성됩니다. 실험 결과, LinGen은 DiT보다 최대 15배 빠른 속도 향상을 보이면서 최첨단 모델과 비슷한 비디오 품질을 생성함을 보여줍니다. 이는 향후 시간 단위 영화 생성과 실시간 대화형 비디오 생성의 길을 열어줍니다.
Efficiency vs DiT#
LinGen은 DiT 대비 효율성이 크게 향상된 텍스트-투-비디오 생성 프레임워크입니다. DiT의 계산 복잡도는 픽셀 수의 제곱에 비례하여 증가하는 반면, LinGen은 선형적으로 증가합니다. 즉, 고해상도 및 장시간 비디오 생성에 훨씬 더 효율적입니다. 실험 결과, LinGen은 DiT에 비해 최대 15배의 FLOPs 감소와 11.5배의 지연 시간 단축을 달성했습니다. 이러한 효율성 향상은 분 단위 길이의 비디오 생성을 가능하게 하고 실시간 대화형 비디오 생성 가능성을 열어줍니다. LinGen은 MATE 블록이라는 새로운 구성 요소를 통해 이러한 효율성 향상을 달성했습니다. 품질 저하 없이 효율성을 크게 향상시켜, 고품질 비디오 생성의 새로운 지평을 열었습니다.
More visual insights#
More on figures

🔼 LinGen denoising 모듈은 self-attention 레이어를 MATE 블록으로 대체하여 선형 계산 복잡도를 달성합니다. MATE 블록은 MA-branch(양방향 Mamba2 블록, RMS, review 토큰)와 TE-branch(Temporal Swin Attention 블록)로 구성됩니다. MA-branch는 단-중-장거리 상관관계를 처리하고, TE-branch는 인접성 보존 문제를 해결하여 생성된 비디오의 일관성을 향상시킵니다.
read the caption
Figure 2: Overview of the LinGen denoising module. LinGen replaces self-attention layers with a MATE block, which inherits linear complexity from its two branches: MA-branch and TE-branch. The MA-branch consists of a bidirectional Mamba2 block, RMS, and review tokens to cover short-to-long-range correlations. The TE-branch is a TEmporal Swin Attention block that addresses the adjacency preservation issue and improves the consistency of generated videos significantly.

🔼 이 그림은 양방향 Mamba2 모듈을 보여줍니다. 기존 Mamba2는 인과적 특성으로 인해 주의 맵의 아래쪽 삼각형 부분만 생성합니다. 따라서, 비전 작업을 위해 완전한 주의 맵을 얻기 위해 양방향 Mamba2를 사용합니다. 즉, Mamba2는 SSM(State Space Model)의 변형으로, SSM과 마스크 효율적 주의를 통합하는 특수한 SSM입니다. Mamba2는 Mamba에서 사용되는 순차적 선형 투영을 제거하고 SSM 매개변수 A, B, C를 병렬로 생성합니다. 또한 Mamba2의 정규화 계층은 [51]과 동일하며, 안정성을 향상시킵니다.
read the caption
Figure 3: The bidirectional Mamba2 module. Native Mamba2 only generates the lower triangular part of the attention map due to its causal characteristic. Thus, we deploy bidirectional Mamba2 to obtain the complete attention map for vision tasks.

🔼 이 그림은 LinGen 모델에서 사용되는 Rotary-Major Scan(RMS) 기법을 보여줍니다. RMS는 3차원 비디오 토큰 텐서를 4가지 다른 방식(공간 행 우선, 공간 열 우선, 시간 행 우선, 시간 열 우선)으로 재배열하여 인접한 토큰 간의 상관관계를 효과적으로 모델링합니다. 각 레이어마다 다른 스캔 방식을 번갈아 사용하며, 실제로는 양방향 스캔을 하지만 그림에서는 각 스캔 방향을 명확히 보여주기 위해 한 방향만 표시했습니다. 이 기법을 통해 Mamba2 블록의 인접성 보존 문제를 해결하고, 추가적인 지연 시간 없이 비디오 생성 성능을 향상시킵니다.
read the caption
Figure 4: Rotary-Major Scan (RMS). We apply different scan schedules across layers to preserve adjacency along various dimensions. Note that scan is bidirectional in practice, but for clarity, only one direction is illustrated for each scan schedule.

🔼 TESA(Temporal Swin Attention)는 토큰 텐서를 작은 윈도우로 나누고 각 윈도우 내에서 자기 주의(self-attention)를 계산합니다. 이러한 윈도우는 레이어마다 번갈아 가며 이동하여 로컬 윈도우의 경계를 넘어 연결을 형성합니다. 윈도우 크기는 다양한 해상도에서 고정되어 선형 복잡도를 유지합니다. 이는 윈도우 크기가 고정되어 있기 때문에 토큰 수에 따라 계산 복잡도가 선형적으로 증가한다는 것을 의미합니다. 따라서 고해상도, 긴 영상 생성에 효율적입니다. 또한, 윈도우를 이동시키는 방식은 Swin Transformer에서 영감을 받았습니다. 각 레이어마다 윈도우를 이동시켜 이전 레이어의 윈도우 경계를 넘어 상호 작용할 수 있도록 합니다. 이는 인접한 토큰 간의 상관관계를 잘 포착하고 영상의 일관성을 향상시키는 데 도움이 됩니다.
read the caption
Figure 5: TEmporal Swin Attention (TESA). We divide the token tensor into small windows and calculate self-attention within each window. The windows are alternately shifted across layers to cross the boundaries of local windows. The window size remains fixed across different resolutions, hence maintaining linear complexity.
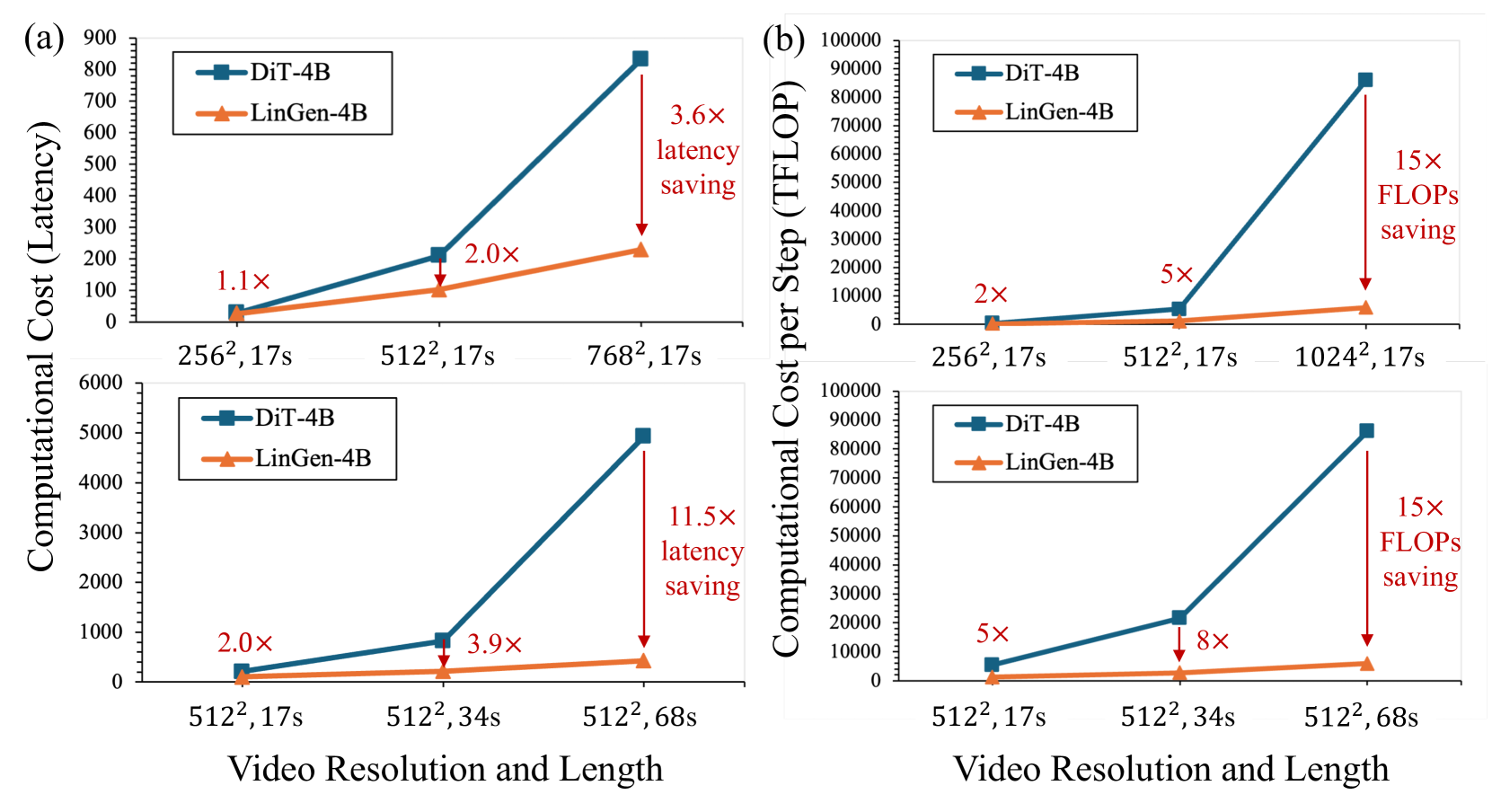
🔼 이 그림은 DiT-4B와 LinGen-4B의 계산 비용을 비교합니다. LinGen의 비용은 비디오 길이와 해상도 모두에서 DiT보다 훨씬 느리게 증가합니다. 68초 길이의 512p 비디오를 생성할 때 LinGen은 DiT에 비해 최대 15배의 FLOPs 감소 및 11.5배의 지연 시간 단축을 달성합니다. 지연 시간은 단일 H100 GPU에서 측정됩니다.
read the caption
Figure 6: Computational cost comparison between DiT-4B and LinGen-4B. (a) Latency. (b) FLOPs. The cost of LinGen scales significantly slower with both video length and video resolution than DiT. Latency is measured on a single H100 GPU.

🔼 이 그림은 LinGen-4B, Gen-3, LumaLabs, Kling을 포함한 다양한 모델에서 생성된 비디오의 시각적 예시를 보여줍니다. LinGen-4B는 표준 DiT 아키텍처에 비해 선형 복잡도와 상당한 속도 향상을 달성하면서 Gen-3, LumaLabs, Kling을 포함한 최첨단 상용 비디오 생성 모델과 유사한 품질의 비디오를 생성합니다. ‘A fish swimming into a coffee shop and trying to order’라는 프롬프트를 기반으로 각 모델은 물고기가 커피숍에 들어가 주문을 시도하는 독특한 해석을 생성합니다. LinGen-4B가 생성한 비디오는 최첨단 모델과 비교할 만한 품질을 보여줍니다.
read the caption
Figure 7: Visual examples of videos generated from different models. LinGen-4B generates videos that have similar quality to state-of-the-art commercial video generative models, including Gen-3, LumaLabs, and Kling, while achieving linear complexity and significant speed-up relative to the standard DiT architecture.

🔼 LinGen-4B와 DiT-4B가 생성한 비디오의 품질 및 텍스트-비디오 정렬에 대한 인간 평가 결과입니다. LinGen은 더 긴 토큰 시퀀스에 더 빠르게 적응하기 때문에 DiT보다 성능이 뛰어납니다. 이 그림은 품질, 프레임 일관성, 모션 자연스러움, 모션 일치, 주제 일치, 전반적인 정렬 등 다양한 측면에서 두 모델의 승률을 보여줍니다.
read the caption
Figure 8: Human evaluation on the quality and text-video alignment of videos generated by DiT-4B and LinGen-4B. LinGen outperforms DiT due to it faster adapation to longer token sequences.

🔼 이 그림은 LinGen과 최신 비디오 생성 모델들(Gen-3, LumaLabs, Kling)이 생성한 비디오의 품질 및 텍스트-비디오 정렬에 대한 인간 평가 결과를 보여줍니다. LinGen은 인간 평가의 분산이 3%라는 점을 고려했을 때, 최신 상용 모델들과 비슷한 성능을 보입니다.
read the caption
Figure 9: Win rates of human evaluation on the quality and text-video alignment of videos generated by LinGen and state-of-the-art video generative models. LinGen has comparable performance to them, given that the variance of human evaluation is 3%.

🔼 이 그림은 LinGen이 DiT보다 새로운 작업에 더 빨리 적응한다는 것을 보여줍니다. (a)는 256p 비디오 생성에서 훈련된 모델을 512p 생성으로 전환할 때의 손실 곡선을, (b)는 LinGen-4B와 DiT-4B 간의 품질 및 텍스트-비디오 충실도 비교에 대한 인간 평가 승률을 보여줍니다. 1K 사전 훈련 단계 후 체크포인트를 선택합니다. LinGen의 손실이 DiT보다 훨씬 빠르게 감소하고, 훈련 초기에 더 높은 품질과 텍스트 정렬 점수를 달성하는 것을 확인할 수 있습니다. 이는 LinGen이 더 긴 토큰 시퀀스와 더 높은 해상도에 더 빨리 적응하여 확장성이 뛰어나다는 것을 보여줍니다.
read the caption
Figure 10: LinGen adapts much faster to the new task than DiT. (a) Loss curves when transferring the model trained on 256p video generation to 512p. (b) Win rates of human evaluation on quality and text-video faithfulness comparison between LinGen-4B and DiT-4B. Checkpoints are selected after 1K pre-training steps.

🔼 이 그림은 LinGen 모델의 256p 해상도 텍스트-비디오 사전 훈련 중 손실 곡선을 보여줍니다. (a)는 TESA 블록과 RMS에 대한 절제 연구 결과를, (b)는 다양한 스캔 방법에 대한 절제 연구 결과를 나타냅니다. TESA 블록과 RMS를 모두 제거하면 손실이 가장 높으며, 이는 두 요소가 모두 비디오 생성 품질에 중요한 역할을 한다는 것을 의미합니다. RMS는 지그재그 스캔과 유사한 성능을 보이지만 추가 지연 시간이 훨씬 적습니다.
read the caption
Figure 11: Loss curves of 256p text-to-video pre-training under different settings. (a) Ablation on the TESA block and RMS. (b) Ablation on different scan methods.

🔼 이 그림은 LinGen의 기본 설정과 여러 변형 설정 간의 품질 비교에 대한 인간 평가의 승률을 보여줍니다. 변형 설정에는 TESA 블록 제거, RMS 제거, 검토 토큰 제거, 하이브리드 학습 제거, 품질 조정 제거 등이 포함됩니다. LinGen의 기본 설정은 대부분의 변형 설정보다 훨씬 더 나은 품질의 비디오를 생성합니다. 이는 TESA 블록, RMS, 검토 토큰, 하이브리드 학습 및 품질 조정이 생성된 비디오의 품질을 향상시키는 데 효과적임을 나타냅니다.
read the caption
Figure 12: Win rates of human evaluation on quality comparison between the LinGen default setting and corresponding variants.

🔼 이 그림은 LinGen 모델로 생성된 17초 및 68초 길이의 비디오 예시를 보여줍니다. 17초 비디오의 프롬프트는 ‘컵에 우유를 조심스럽게 붓는’, ‘게가 굴 주위를 돌아다니는’, ‘딸기와 블루베리가 물에 떨어지는’입니다. 68초 비디오의 프롬프트는 ‘난파선 근처에서 헤엄치는 바다거북’입니다. LinGen은 긴 영상에서도 일관성과 사실적인 디테일을 유지하면서 고품질 영상을 생성할 수 있음을 보여줍니다.
read the caption
Figure 13: Examples of 17-second and 68-second videos generated by LinGen.

🔼 이 그림은 일반적인 오픈 소스 텍스트-비디오 생성 모델과 LinGen을 비교한 결과를 보여줍니다. LinGen이 생성한 비디오의 품질이 다른 오픈 소스 모델보다 우수함을 보여줍니다. 각 비디오에는 프롬프트가 표시되어 있으며 LinGen은 프롬프트를 더 잘 따르는 것으로 나타났습니다.
read the caption
Figure 14: Comparisons with typical open-source video generative models.

🔼 이 그림은 LinGen-4B 모델과 다른 최첨단 상용 텍스트-비디오 생성 모델(Gen-3, LumaLabs, Kling)에서 생성된 비디오를 시각적으로 비교하여 보여줍니다. LinGen-4B는 다른 모델과 비슷한 품질의 비디오를 생성하면서 선형 계산 복잡성과 표준 DiT 아키텍처에 비해 상당한 속도 향상을 달성합니다.
read the caption
Figure 15: Comparisons with state-of-the-art accessible commercial models.

🔼 이 그림은 1분 길이의 비디오 생성에 대한 기존 연구 결과와의 비교를 보여줍니다. 즉, Loong과 PA-VDM입니다. PA-VDM은 프롬프트를 제공하지 않으므로 LinGen에서 생성된 유사한 비디오를 찾았습니다. LinGen의 결과는 최첨단 상업용 모델과 비슷한 품질을 보여주는 반면 Loong의 결과는 품질이 낮습니다.
read the caption
Figure 16: Comparisons with existing trials on generating minute-length videos.

🔼 이 그림은 LinGen 모델에서 TESA 블록, RMS, 리뷰 토큰의 효과를 검증하기 위한 ablation study 결과를 보여줍니다. 첫 번째 행은 256p 해상도, 17초 길이의 비디오에 대한 ablation study 결과이고 두 번째 행은 512p 해상도, 68초 길이의 비디오에 대한 ablation study 결과입니다. 각 행에서 왼쪽은 TESA 블록과 RMS를 제거한 결과, 중간은 리뷰 토큰을 제거한 결과, 오른쪽은 LinGen의 최종 결과입니다. 이 ablation study를 통해 TESA 블록, RMS, 리뷰 토큰이 생성되는 비디오의 품질과 일관성에 긍정적인 영향을 미친다는 것을 확인할 수 있습니다.
read the caption
Figure 17: Visual examples of ablation experiments on the TESA block, RMS, and review tokens.

🔼 이 그림은 하이브리드 학습과 품질 튜닝에 대한 절제 실험의 시각적 예시를 보여줍니다. 256p 해상도에서 일관성이 비정상적으로 나쁜 실패 사례와 512p 해상도에서 품질이 비정상적으로 나쁜 실패 사례를 각각 보여줍니다. 하이브리드 학습은 텍스트-이미지 데이터와 텍스트-비디오 데이터를 모두 사용하여 학습하는 것을 말하며, 품질 튜닝은 고품질 비디오 데이터셋으로 모델을 미세 조정하는 것을 말합니다.
read the caption
Figure 18: Visual examples of ablation experiments on hybrid training and quality-tuning.

🔼 이 그림은 LinGen과 다른 오픈 소스 텍스트-비디오 생성 모델이 생성한 비디오의 품질 및 텍스트-비디오 정렬에 대한 인간 평가 결과를 막대 그래프로 보여줍니다. LinGen은 다른 모델보다 품질 및 정렬 측면에서 더 높은 점수를 받았습니다.
read the caption
Figure 19: Win rates of human evaluation of quality and text-video alignment of videos generated by LinGen and typical open-source video generative models.

🔼 이 그림은 서로 다른 모델 디자인으로 512p 해상도, 17초 길이의 비디오를 생성하는 데 걸리는 지연 시간을 비교합니다. LinGen 모델의 지연 시간은 모델 크기에 따라 self-attention 기반의 표준 DiT 모델보다 더 느리게 증가합니다. 평균 지연 시간을 측정하기 위해 100회의 추론 단계를 수행했으며, 이는 본 논문에서 사용된 기본 설정인 50단계와 다릅니다.
read the caption
Figure 20: Latency of generating 512p 17s videos with different model designs. The latency of LinGen models scales more slowly with model size than self-attention-based standard DiT models. Note that we perform 100 inference steps to measure average latency. This is different from the default setting of 50 steps employed in our main paper.
More on tables
| Score | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Runway Gen-3 [47] | 87.81% | 53.64% | 96.40% | 80.90% | 65.09% | 54.57% | 24.31% | 24.71% | 26.69% | 75.17% |
| Kling [24] | 87.24% | 68.05% | 93.40% | 89.90% | 73.03% | 50.86% | 19.62% | 24.17% | 26.42% | 75.68% |
| OpenSora V1.2 [75] | 82.22% | 51.83% | 91.20% | 90.08% | 68.56% | 42.44% | 23.95% | 24.54% | 26.85% | 73.39% |
| LinGen | 90.98% | 55.15% | 97.50% | 83.95% | 58.15% | 53.51% | 21.08% | 24.29% | 26.32% | 73.73% |
🔼 LinGen의 기본 설정과 다양한 변형 설정에서 512p 해상도, 17초 길이의 비디오를 생성할 때의 지연 시간을 비교한 표입니다. TESA 블록, RMS, Zigzag 스캔, Mamba, MA-branch, 리뷰 토큰의 유무에 따른 LinGen의 지연 시간 변화를 보여줍니다. 각 설정 변화에 따른 지연 시간의 차이(초)도 함께 표시되어 있습니다.
read the caption
Table 2: Latency of the LinGen default setting and variant settings when generating 512p 17s videos.
| Model | Latency/s |
|---|---|
| LinGen (default setting) | 102 |
| LinGen w/o TESA | 94 (-8) |
| LinGen w/o RMS | 99 (-3) |
| LinGen w/ Zigzag | 144 (+42) |
| LinGen w/ Mamba | 127 (+25) |
| LinGen w/o MA-branch | 65 (-37) |
| LinGen w/o review tokens | 98 (-4) |
🔼 VBench-Long 리더보드는 생성된 비디오의 품질(Quality Score)과 텍스트-비디오 정렬(Semantic Score)을 측정하여 종합 점수(Total Score)를 계산합니다. LinGen은 Gen-3, Kling과 같은 최첨단 상용 모델과 비슷한 성능을 보이며, 일반적인 오픈 소스 모델보다 훨씬 뛰어난 성능을 보입니다.
read the caption
Table 3: A more complete VBench-Long leaderboard. Quality Score measures the quality of generated videos and Semantic Score measures text-video alignment. Total Score represents their weighted sum. Higher values indicate better performance for all these metrics. LinGen can be seen to be comparable to state-of-the-art commercial models (i.e., Gen-3 and Kling) and significantly outperform typical open-source models.
| Model | Subject Consist. | BG. Consis. | Temp. Flick. | Motion Smooth. | Aesthe. Quality | Imag. Quality | Dyna. Degree | Quality Score | Total Score | Max. Raw Frames |
|---|---|---|---|---|---|---|---|---|---|---|
| Runway Gen-3 [47] | 97.10% | 96.62% | 98.61% | 99.23% | 60.14% | 63.34% | 66.82% | 84.11% | 82.32% | 256 |
| Kling [24] | 98.33% | 97.60% | 99.30% | 99.40% | 46.94% | 61.21% | 65.62% | 83.39% | 81.85% | 313 |
| CogVideoX-5B [71] | 96.23% | 96.52% | 98.66% | 96.92% | 70.97% | 61.98% | 62.90% | 82.75% | 81.61% | 48 |
| Mochi-1 [57] | 96.99% | 97.28% | 99.40% | 99.02% | 61.85% | 56.94% | 60.64% | 82.64% | 80.13% | 163 |
| OpenSora V1.2 [75] | 96.75% | 97.61% | 99.53% | 98.50% | 42.39% | 56.85% | 63.34% | 81.35% | 79.76% | 408 |
| Mira [21] | 96.23% | 96.92% | 98.29% | 97.54% | 60.33% | 42.51% | 60.16% | 78.78% | 71.87% | 60 |
| LinGen | 98.30% | 97.60% | 99.26% | 98.58% | 63.67% | 60.55% | 63.36% | 83.77% | 81.76% | 1088 |
🔼 VBench-standard 벤치마크에서 LinGen과 다른 모델의 성능을 비교한 표입니다. 품질 점수, 의미 점수, 총점수를 사용하여 생성된 비디오의 품질과 텍스트-비디오 정렬을 평가합니다. 점수가 높을수록 성능이 좋다는 것을 의미하며, LinGen은 대부분의 지표에서 다른 오픈 소스 모델보다 우수한 성능을 보입니다.
read the caption
Table 4: Automatic evaluation of LinGen on VBench-standard. Quality Score measures the quality of generated videos and Semantic Score measures text-video alignment. Total Score represents their weighted sum. Higher values indicate better performance for all these metrics.
| Model | Object Class | Multiple Objects | Human Action | Color | Spatial Relatio. | Scene | Appear. Style | Temp. Style | Overall Consist. | Semantic Score |
|---|---|---|---|---|---|---|---|---|---|---|
| Runway Gen-3 [47] | 87.81% | 53.64% | 96.40% | 80.90% | 65.09% | 54.57% | 24.31% | 24.71% | 26.69% | 75.17% |
| Kling [24] | 87.24% | 68.05% | 93.40% | 89.90% | 73.03% | 50.86% | 19.62% | 24.17% | 26.42% | 75.68% |
| CogVideoX-5B [71] | 85.23% | 62.11% | 99.40% | 82.81% | 66.35% | 53.20% | 24.91% | 25.38% | 27.59% | 77.04% |
| Mochi-1 [57] | 86.51% | 50.47% | 94.60% | 79.73% | 69.24% | 36.99% | 20.33% | 23.65% | 25.15% | 70.08% |
| OpenSora V1.2 [75] | 82.22% | 51.83% | 91.20% | 90.08% | 68.56% | 42.44% | 23.95% | 24.54% | 26.85% | 73.39% |
| Mira [21] | 52.06% | 12.52% | 63.80% | 42.24% | 27.83% | 16.34% | 21.89% | 18.77% | 18.72% | 44.21% |
| LinGen | 90.98% | 55.15% | 97.50% | 83.95% | 58.15% | 53.51% | 21.08% | 24.29% | 26.32% | 73.73% |
🔼 VBench-Custom 벤치마크 결과는 맞춤형 프롬프트를 사용하여 텍스트-비디오 생성 모델을 평가합니다. 표에서 Quality Score는 지원되는 메트릭의 가중 합계를 나타냅니다. 이 표는 4.3절에 나와 있습니다.
read the caption
Table 5: VBench-Custom results based on customized prompts. Quality Score represents the weighted sum of these supported metrics.
| Model | Subject Consist. | BG. Consis. | Temp. Flick. | Motion Smooth. | Aesthe. Quality | Imag. Quality | Dyna. Degree | Quality Score | Total Score | Max. Raw Frames |
|---|---|---|---|---|---|---|---|---|---|---|
| T2V-Turbo-v2 [29] | 95.50% | 96.71% | 97.35% | 97.07% | 90.00% | 62.61% | 71.78% | 85.13% | 83.52% | 16 |
| Runway Gen-3 [47] | 97.10% | 96.62% | 98.61% | 99.23% | 60.14% | 63.34% | 66.82% | 84.11% | 82.32% | 256 |
| LaVie-2 [64] | 97.90% | 98.45% | 98.76% | 98.42% | 31.11% | 67.62% | 70.39% | 83.24% | 81.75% | 61 |
| Pika-1.0 [26] | 96.94% | 97.36% | 99.74% | 99.50% | 47.50% | 62.04% | 61.87% | 82.92% | 80.69% | 72 |
| VideoCrafter-2.0 [3] | 96.85% | 98.22% | 98.41% | 97.73% | 42.50% | 63.13% | 67.22% | 82.20% | 80.44% | 16 |
| OpenSora V1.2 [75] | 96.75% | 97.61% | 99.53% | 98.50% | 42.39% | 56.85% | 63.34% | 81.35% | 79.76% | 408 |
| LinGen | 98.30% | 97.60% | 99.26% | 98.58% | 63.67% | 60.55% | 63.36% | 83.77% | 81.76% | 1088 |
🔼 이 표는 VBench-Custom 벤치마크에서 LinGen 모델을 서로 다른 해상도로 평가한 결과를 보여줍니다. 높은 해상도의 비디오는 사람의 평가에서 더 높은 선호도를 얻었지만, VBench 점수는 약간 더 높았습니다. 이는 VBench 점수가 사람의 선호도와 완벽하게 일치하지 않음을 시사합니다.
read the caption
Table 6: VBench-Custom results of LinGen at different resolutions. Higher-resolution videos obtain a much higher win rate in human evaluation but only obtain a slightly higher VBench quality score. This indicates that VBench does not perfectly align with human preference.
| Model | Object Class | Multiple Objects | Human Action | Color | Spatial Relatio. | Scene | Appear. Style | Temp. Style | Overall Consist. | Semantic Score |
|---|---|---|---|---|---|---|---|---|---|---|
| T2V-Turbo-v2 [29] | 95.33% | 61.49% | 96.20% | 92.53% | 43.32% | 56.40% | 24.17% | 27.06% | 28.26% | 77.12% |
| Runway Gen-3 [47] | 87.81% | 53.64% | 96.40% | 80.90% | 65.09% | 54.57% | 24.31% | 24.71% | 26.69% | 75.17% |
| LaVie-2 [64] | 97.52% | 64.88% | 96.40% | 91.65% | 38.68% | 49.59% | 25.09% | 25.24% | 27.39% | 75.76% |
| Pika-1.0 [26] | 88.72% | 43.08% | 86.20% | 90.57% | 61.03% | 49.83% | 22.26% | 24.22% | 25.94% | 71.77% |
| VideoCrafter-2.0 [3] | 92.55% | 40.66% | 95.00% | 92.92% | 35.86% | 55.29% | 25.13% | 25.84% | 28.23% | 73.42% |
| OpenSora V1.2 [75] | 82.22% | 51.83% | 91.20% | 90.08% | 68.56% | 42.44% | 23.95% | 24.54% | 26.85% | 73.39% |
| LinGen | 90.98% | 55.15% | 97.50% | 83.95% | 58.15% | 53.51% | 21.08% | 24.29% | 26.32% | 73.73% |
🔼 LinGen 모델의 사전 훈련 레시피를 보여주는 표입니다. 각 단계별로 해상도, 비디오 길이, 훈련 단계 수, 배치 크기, 그리고 Nvidia H100 GPU를 사용한 훈련 기간(일)을 나타냅니다. 256p 해상도의 텍스트-이미지 사전 훈련부터 시작하여 512p 해상도의 다양한 길이의 텍스트-비디오 사전 훈련까지 점진적으로 진행됩니다.
read the caption
Table 7: The pre-training recipe of LVGen. The model was trained on Nvidia H100 GPUs.
Full paper#



















