↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
최근 MLLM은 이미지 이해와 생성에서 놀라운 성과를 보여주지만 통합 모델은 복잡한 설계와 훈련 파이프라인으로 인해 어려움을 겪습니다. 이는 모델 훈련 및 확장의 어려움을 증가시킵니다.
SynerGen-VL은 토큰 폴딩 및 비전 전문가 기반의 점진적 정렬 사전 훈련이라는 두 가지 주요 기술을 도입하여 이러한 문제를 해결합니다. 토큰 폴딩은 고해상도 이미지를 효율적으로 처리하고 비전 전문가는 시각적 기능을 통합하는 데 도움이 됩니다. 단일 다음 토큰 예측 목표로 훈련된 SynerGen-VL은 더 작은 매개변수 크기로 기존의 인코더가 없는 통합 MLLM의 성능을 능가하며 작업별 최첨단 모델과의 격차를 줄입니다.
Key Takeaways#
Why does it matter?#
SynerGen-VL은 통합 MLLM 설계 및 훈련에 대한 새로운 경로를 제시하며, 특히 고해상도 이미지 처리 및 비전 기능 통합에 어려움을 겪는 연구자들에게 유용합니다. 토큰 폴딩 및 MMOE와의 점진적 정렬 사전 훈련과 같은 혁신적인 기술은 모델 효율성과 성능을 향상시켜 추가 연구 및 개발을 위한 강력한 기반을 제공합니다.
Visual Insights#

🔼 이 그림은 이미지 이해 및 생성 작업을 위한 다양한 통합 MLLM(다중 모달 대형 언어 모델)의 구조를 비교하여 보여줍니다. (a)~(d)와 같이 복잡한 모델 구조, 훈련 방법, 외부 사전 훈련된 확산 모델을 사용하는 방법과 달리, (e)의 인코더가 없는 통합 MLLM은 이미지 이해 및 생성 작업 모두에 간단한 다음 토큰 예측 프레임워크를 사용하는 단순한 설계를 채택하여 더 넓은 데이터 분포와 확장성을 제공합니다.
read the caption
Figure 1: Comparison among exemplary unified MLLMs for synergizing image understanding and generation tasks. Compared with methods (a)∼similar-to\sim∼(d) that incorporate complicated designs of model architectures, training methods, and the use of external pretrained diffusion models, (e) encoder-free unified MLLMs adopt a simple design that uses the simple next token prediction framework for both images understanding and generation tasks, allowing for broader data distribution and better scalability.
| Task | #Sam. | Datasets | |
|---|---|---|---|
| Gen. | 667M | LAION-Aesthetics [67], Megalith [52], SAM [33], Objects365 [69], ImageNet-1k [18], | |
| S.1 | Und. | 667M | Laion-En [67], COYO [6], SAM [33] |
| Gen. | 170M | LAION-Aesthetics [67], Megalith [52], Objects365 [69], Unsplash [85], Dalle-3-HQ [3], JourneyDB [74], Internal Dataset | |
| 170M | Captioning: Laion-En [67], Laion-Zh [67], COYO [6], GRIT [60], COCO [40], TextCaps [71] | ||
| Detection: Objects365 [69], GRIT [60], All-Seeing [90] | |||
| OCR (large): Wukong-OCR [26], LaionCOCO-OCR [68], Common Crawl PDF | |||
| OCR (small): MMC-Inst [41], LSVT [79], ST-VQA [5], RCTW-17 [70], ReCTs [106], ArT [13], SynthDoG [32], ChartQA [53], CTW [104], DocVQA [15], TextOCR [73], | |||
| S.2 | Und. | 170M | COCO-Text [87], PlotQA [55], InfoVQA [54] |
🔼 이 표는 SynerGen-VL의 시각적 정렬 사전 훈련에 사용된 데이터셋을 요약한 것입니다. ‘S.1’과 ‘S.2’는 각각 첫 번째와 두 번째 단계를 나타냅니다. ‘Gen.‘은 이미지 생성 작업을, ‘Und.‘는 이미지 이해 작업을 나타냅니다. ‘#Sam.‘은 각 단계의 각 작업 훈련 중에 표시된 총 샘플 수를 나타냅니다. 두 번째 단계의 이미지 이해에 사용된 모든 데이터는 InternVL-1.5 [11]에도 사용됩니다.
read the caption
Table 1: Summary of datasets used in Visual Alignment Pretraining. “S.1” and “S.2” denote the first and second stage. “Gen.” and “Und.” denote the image generation and understanding task. “#Sam.” denotes the number of total samples seen during training of each task at each stage. Note that all data used for image understanding in the second stage is also used in InternVL-1.5 [11].
In-depth insights#
Encoder-Free MLLMs#
인코더 없는 MLLM은 이미지 인코더를 사용하지 않고 텍스트 토큰과 함께 이미지 토큰을 직접 입력하는 방식입니다. 이는 MLLM 아키텍처를 단순화하고 확장성을 높이는 데 기여합니다. 기존 MLLM처럼 외부 모델이나 작업별 모델에 의존하지 않고 통합된 단일 모델로 이미지 이해와 생성을 모두 수행할 수 있는 것이 장점입니다. 또한, 사전 훈련된 지식을 활용하여 효율적인 학습이 가능하며, 텍스트와 이미지 모두에 대해 다음 토큰 예측이라는 통일된 프레임워크를 사용합니다. 그러나 고해상도 이미지를 처리할 때 계산 비용이 높아질 수 있고, 이미지와 텍스트 간의 의미적 정렬 문제, 생성된 이미지의 품질 및 다양성 부족 등의 과제가 남아 있습니다. 향후 연구에서는 이러한 문제점을 해결하고 더욱 발전된 인코더 없는 MLLM을 개발할 것으로 기대됩니다.
Token Folding#
토큰 폴딩은 SynerGen-VL의 핵심 메커니즘으로, 고해상도 이미지 이해 및 생성을 효율적으로 처리합니다. 이 기법은 입력 이미지 토큰 시퀀스를 더 작은 크기로 압축하여 MLLM의 처리 부담을 줄입니다. 압축된 표현은 이미지 생성 중에 디코더를 사용하여 원래의 고해상도 이미지로 다시 펼쳐집니다. 이러한 접근 방식을 통해 SynerGen-VL은 더 긴 시퀀스로 인한 계산 병목 현상 없이 고해상도 이미지의 풍부한 시각적 정보를 활용할 수 있습니다. 토큰 폴딩은 MLLM 입력의 길이를 줄여 메모리 사용량과 계산 비용을 줄이는 데 기여합니다. 또한, 폴딩된 토큰은 시각적 장면의 더 넓은 맥락을 표현하여 이미지 이해 능력 향상에 도움을 줄 수 있습니다.
Vision Experts#
SynerGen-VL은 비전 전문가를 활용하여 이미지 이해 및 생성 능력을 향상시킵니다. 이러한 전문가는 이미지 표현 전용 매개변수를 포함하는 이미지별 FFN(피드포워드 네트워크)입니다. 사전 훈련된 LLM(대규모 언어 모델)의 전체 튜닝을 방지하기 위해 이러한 추가 매개변수가 도입되었습니다. 2단계 정렬 사전 훈련 전략을 통해 비전 전문가를 LLM의 표현 공간에 맞춰 시각적 기능을 통합하고 LLM의 사전 훈련된 지식에 대한 영향을 최소화합니다. 즉, 시각적 표현을 사전 훈련된 LLM에 맞춰 일반적인 지각 및 일반화 기능을 보장합니다. 첫 번째 단계에서는 노이즈가 있는 웹 데이터로 이미지별 FFN을 훈련하여 기본적인 의미 이해 및 이미지 생성 능력을 확보합니다. 두 번째 단계에서는 고품질 이미지 이해 및 생성 데이터를 사용하여 이미지별 FFN과 자체 주의 레이어를 훈련하여 다중 모드 기능을 사전 훈련된 LLM에 통합합니다. 이러한 접근 방식을 통해 SynerGen-VL은 단일 LLM 아키텍처 내에서 이미지 이해 및 생성 작업을 효과적으로 처리할 수 있습니다.
Two-Stage Alignmt#
2단계 정렬 사전 훈련은 SynerGen-VL의 핵심이며, 사전 훈련된 LLM의 지식을 보존하면서 시각적 기능을 통합합니다. 첫 번째 단계는 노이즈가 있는 웹 데이터를 사용하여 이미지별 FFN을 훈련하여 기본적인 시맨틱 이해 및 이미지 생성 기능을 획득하고 LLM의 표현 공간과 정렬합니다. 두 번째 단계에서는 고품질의 이미지 이해 및 생성 데이터를 사용하여 이미지별 FFN과 자기 주의 레이어를 훈련하여 사전 훈련된 LLM에 다중 모드 기능을 더욱 통합합니다. 이 점진적인 접근 방식은 시각적 전문가가 LLM의 사전 훈련된 지식을 방해하지 않고 시각적 기능을 효과적으로 학습할 수 있도록 합니다. 고품질 데이터를 사용한 두 번째 단계는 이미지-텍스트 정렬을 개선하고 이미지 미학을 향상시켜 이해와 생성 모두에 도움이 됩니다.
Synergistic Und&Gen#
SynerGen-VL은 이미지 이해 및 생성을 통합된 단일 MLLM에서 처리하는 것을 목표로 합니다. 이는 기존 방식과 달리 외부 확산 모델이나 특정 작업 모델에 의존하지 않고, 단일 토큰 예측 프레임워크를 사용합니다. 이러한 접근 방식은 모델 아키텍처를 단순화하고 확장성을 향상시킵니다. SynerGen-VL은 비전 전문가를 활용하여 이미지 표현을 학습하고, 토큰 폴딩 메커니즘을 통해 고해상도 이미지를 효율적으로 처리합니다. 또한, 사전 훈련된 LLM의 지식을 보존하기 위해 점진적 정렬 사전 훈련 전략을 사용합니다. 이러한 혁신적인 디자인을 통해 SynerGen-VL은 작업별 최첨단 모델과의 격차를 줄이고, 더 나아가 차세대 통합 MLLM 개발의 가능성을 보여줍니다.
More visual insights#
More on figures
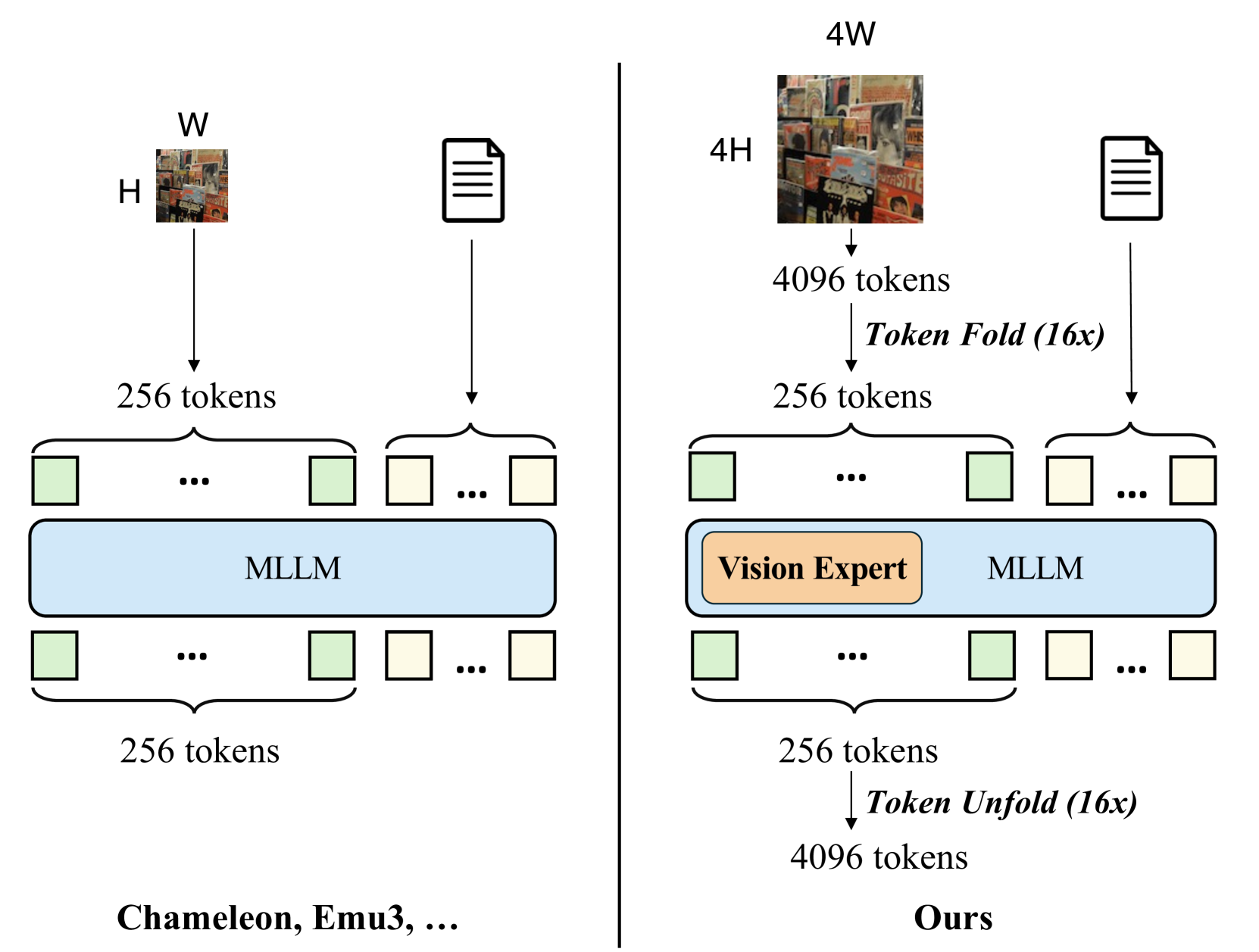
🔼 SynerGen-VL은 토큰 접기 및 펼치기 메커니즘과 비전 전문가를 활용하여 강력하고 단순한 통합 MLLM을 구축합니다. 동일한 이미지 컨텍스트 길이로 SynerGen-VL은 훨씬 더 높은 해상도의 이미지를 지원하여 고해상도 이미지 이해 및 생성 성능을 보장합니다. 기존의 인코더 없는 통합 MLLM은 고해상도 이미지를 처리하는 데 어려움을 겪었지만 SynerGen-VL은 토큰 접기를 통해 입력 이미지 토큰 시퀀스를 압축하고, 비전 전문가를 통해 이미지 표현 능력을 향상시켜 이러한 문제를 해결합니다. 따라서 SynerGen-VL은 더 작은 모델 크기로도 고해상도 이미지 이해 및 생성 작업에서 우수한 성능을 달성할 수 있습니다. 그림은 SynerGen-VL과 기존 MLLM의 차이점을 시각적으로 보여줍니다.
read the caption
Figure 2: Comparision between SynerGen-VL and previous encoder-free unified MLLMs. SynerGen-VL adopts a token folding and unfolding mechanism and vision experts to build a strong and simple unified MLLM. With the same image context length, SynerGen-VL can support images of much higher resolutions, ensuring the performance of both high-resolution image understanding and generation.

🔼 SynerGen-VL은 이미지와 텍스트를 이산 토큰으로 표현하고 단일 LLM과 통합된 다음 토큰 예측 패러다임을 사용하는 통합 멀티모달 대형 언어 모델(MLLM)입니다. 사전 훈련된 LLM에 시각적 기능을 통합하기 위해 텍스트 및 비전 전문가 FFN이 도입되었습니다. 고해상도 이미지 처리를 지원하기 위해 입력 이미지 토큰 시퀀스는 길이를 줄이기 위해 접히고(token folding), 이미지를 생성하기 위해 얕은 자기 회귀 변환기 헤드에 의해 펼쳐집니다(token unfolding).
read the caption
Figure 3: Overview of the proposed SynerGen-VL. The image and text are represented as discrete tokens, and modeled with a single LLM and unified next-token prediction paradigm. Text and vision expert FFNs are introduced to incorporate visual capabilities into the pretrained LLM. To support processing high-resolution images, the input image token sequence is folded to reduce its length, and unfolded by a shallow autoregressive Transformer head to generate images.

🔼 이 그림은 이미지 생성과 이해 작업에서 추출된 시각적 특징 간의 코사인 유사도를 각 레이어별로 보여줍니다. 생성 및 이해 작업에 대한 표현은 얕은 레이어에서는 유사하지만 깊은 레이어로 갈수록 차이가 발생합니다. 즉, 두 작업 모두 초기 단계에서는 기본적인 시각적 표현을 공유하지만, 레이어가 깊어짐에 따라 이미지 생성은 국부적 세부 사항에, 이미지 이해는 전체적인 맥락에 집중하면서 작업별로 특화된 표현을 개발합니다.
read the caption
Figure 4: Cosine similarity of visual features between generation and understanding tasks across different layers. The representations of the image understanding and generation tasks are similar in shallow layers but disentagle in deeper layers.

🔼 이 그림은 이해 및 생성 작업에 대한 어텐션 맵 시각화를 보여줍니다. 두 번째 및 네 번째 행에서 쿼리 토큰(빨간색)과 입력 이미지에서 주목하는 토큰(파란색)을 시각화합니다. 각 토큰은 2x4 토큰 폴딩으로 인해 원본 이미지에서 가로 직사각형 영역에 해당합니다. 진한 파란색은 더 큰 어텐션 가중치를 나타냅니다. 이해 작업의 경우, 모델은 이미지의 전역 컨텍스트에 주목하는 반면 생성 작업의 경우 로컬 세부 정보에 더 집중합니다. 이는 생성된 이미지의 공간적 일관성과 의미적 일관성을 보장하기 위해 로컬 세부 정보가 필요하기 때문입니다. 또한 텍스트 토큰과 이미지 간의 상호 작용은 얕은 레이어보다 깊은 레이어에서 더 자주 발생하는데, 이는 텍스트가 이미지 생성에 미치는 영향을 보여줍니다.
read the caption
Figure 5: Attention map visualization of understanding and generation tasks. In the second and fourth rows, we visualize a query token (red) and its attended tokens (blue) in the input image. Each token corresponds to a horizontal rectangular area in the original image due to the 2×4242\times 42 × 4 token folding. Darker blue indicates larger attention weights.

🔼 이 그림은 SynerGen-VL 모델의 이미지 생성 능력을 정성적으로 평가한 결과를 보여줍니다. 다양한 텍스트 프롬프트를 입력으로 사용하여 생성된 512x512 크기의 이미지들을 보여주고 있으며, 생성된 이미지들이 프롬프트의 내용을 얼마나 잘 반영하는지, 그리고 이미지의 품질이 어떤지를 시각적으로 확인할 수 있습니다. 예시로 생성된 이미지들은 도시 풍경, 자연 경관, 인물, 추상적인 그림 등 다양한 주제를 다루고 있습니다.
read the caption
Figure 6: Qualitative results of image generation. The images are of size 512×512512512512\times 512512 × 512.
More on tables
| Model | #A-Param | POPE | MMB | MMVet | MMMU | MME | MME-P | MathVista | SEED-I | OCRBench |
|---|---|---|---|---|---|---|---|---|---|---|
| Understanding Only | ||||||||||
| Encoder-based | ||||||||||
| LLaVA-1.5 [43] | 7B | 85.9 | 64.3 | 31.1 | 35.4 | - | 1512 | - | 58.6 | - |
| Mini-Gemini-2B [38] | 3.5B | - | 59.8 | 31.1 | 31.7 | 1653 | - | 29.4 | - | - |
| DeepSeek-VL-1.3B [48] | 2B | 87.6 | 64.6 | 34.8 | 32.2 | 1532 | - | 31.1 | 66.7 | 409 |
| PaliGemma-3B [4] | 2.9B | 87.0 | 71.0 | 33.1 | 34.9 | 1686 | - | 28.7 | 69.6 | 614 |
| MiniCPM-V2 [100] | 2.8B | - | 69.1 | 41.0 | 38.2 | 1809 | - | 38.7 | 67.1 | 605 |
| InternVL-1.5 [11] | 2B | - | 70.9 | 39.3 | 34.6 | 1902 | - | 41.1 | 69.8 | 654 |
| Qwen2-VL [88] | 2B | - | 74.9 | 49.5 | 41.1 | 1872 | - | 43.0 | - | 809 |
| Encoder-free | ||||||||||
| Fuyu-8B (HD) [2] | 8B | - | 10.7 | 21.4 | - | - | - | - | - | - |
| EVE-7B [19] | 7B | 83.6 | 49.5 | 25.6 | 32.3 | 1483 | - | 25.2 | 61.3 | 327 |
| Mono-InternVL [51] | 1.8B | - | 65.5 | 40.1 | 33.7 | 1875 | - | 45.7 | 67.4 | 767 |
| Understanding & Generation | ||||||||||
| Encoder-based | ||||||||||
| Emu [78] | 14B | - | - | 36.3 | - | - | - | - | - | - |
| Emu2 [76] | 37B | - | 63.6 | 48.5 | 34.1 | - | 1345 | - | 62.8 | - |
| SEED-X [24] | 17B | 84.2 | 75.4 | - | 35.6 | - | 1436 | - | - | - |
| LWM [45] | 7B | 75.2 | - | 9.6 | - | - | - | - | - | - |
| DreamLLM [20] | 7B | - | 58.2 | 36.6 | - | - | - | - | - | - |
| Janus [92] | 1.3B | 87.0 | 69.4 | 34.3 | 30.5 | - | 1338 | - | 63.7 | - |
| Encoder-free | ||||||||||
| Chameleon [8] | 7B | - | - | 8.3 | 22.4 | - | - | - | - | - |
| Show-o [96] | 1.3B | 84.5 | - | - | 27.4 | - | 1233 | - | - | - |
| VILA-U [94] | 7B | 85.8 | - | 33.5 | - | - | 1402 | - | 59.0 | - |
| Emu3-Chat [91] | 8B | 85.2 | 58.5 | 37.2 | 31.6 | - | - | - | 68.2 | 687 |
| SynerGen-VL (Ours) | 2.4B | 85.3 | 53.7 | 34.5 | 34.2 | 1837 | 1381 | 42.7 | 62.0 | 721 |
🔼 이 표는 일반적인 MLLM 벤치마크에서 SynerGen-VL의 성능을 다른 모델과 비교하여 보여줍니다. SynerGen-VL은 2.4B 매개변수로, Emu3-Chat-8B와 같은 훨씬 더 큰 매개변수를 가진 기존의 인코더 없는 통합 MLLM보다 이미지 이해 성능이 우수합니다. 특히, SynerGen-VL은 OCRBench와 같이 고해상도 이미지 이해가 필요한 벤치마크에서 훨씬 더 큰 인코더 없는 통합 MLLM보다 뛰어난 결과를 달성합니다. 또한 SynerGen-VL은 외부 확산 모델 없이도 경쟁력 있는 이미지 생성 성능을 달성합니다.
read the caption
Table 2: Results on general MLLM benchmarks. Our model with 2.4B parameters achieves competitive image understanding performance compared with significantly larger encoder-free unified MLLMs such as Emu3-Chat-8B [91].
| Method | #A-Param | TextVQA | SQA-I | GQA | DocVQA | AI2D | ChartQA | InfoVQA |
|---|---|---|---|---|---|---|---|---|
| Understanding Only | ||||||||
| Encoder-based | ||||||||
| MobileVLM-V2 [14] | 1.7B | 52.1 | 66.7 | 59.3 | - | - | - | - |
| Mini-Gemini-2B [39] | 3.5B | 56.2 | - | - | 34.2 | - | - | - |
| PaliGemma-3B [4] | 2.9B | 68.1 | - | - | - | 68.3 | - | |
| MiniCPM-V2 [100] | 2.8B | 74.1 | - | - | 71.9 | - | - | - |
| InternVL-1.5 [11] | 2B | 70.5 | 84.9 | 61.6 | 85.0 | 69.8 | 74.8 | 55.4 |
| Encoder-free | ||||||||
| EVE-7B [19] | 7B | 51.9 | 63.0 | 60.8 | - | - | - | - |
| Mono-InternVL [51] | 1.8B | 72.6 | 93.6 | 59.5 | 80.0 | 68.6 | 73.7 | 43.0 |
| Understanding & Generation | ||||||||
| Encoder-based | ||||||||
| Emu2 [76] | 37B | 66.6 | - | 65.1 | - | - | - | - |
| LWM [45] | 7B | 18.8 | 47.7 | 44.8 | - | - | - | - |
| DreamLLM [20] | 7B | 41.8 | - | - | - | - | - | - |
| MM-Interleaved [82] | 13B | 61.0 | - | 60.5 | - | - | - | - |
| Janus [92] | 1.3B | - | - | 59.1 | - | - | - | - |
| Encoder-free | ||||||||
| Chameleon* [8] | 7B | 4.8 | 47.2 | - | 1.5 | 46.0 | 2.9 | 5.0 |
| Show-o [96] | 1.3B | - | - | 61.0 | - | - | - | - |
| VILA-U [94] | 7B | 60.8 | - | 60.8 | - | - | - | - |
| Emu3-Chat [91] | 8B | 64.7 | 89.2 | 60.3 | 76.3 | 70.0 | 68.6 | 43.8 |
| SynerGen-VL (Ours) | 2.4B | 67.5 | 92.6 | 59.7 | 76.6 | 60.8 | 73.4 | 37.5 |
🔼 이 표는 다양한 시각적 질문 답변 벤치마크에서 기존 MLLM과 SynerGen-VL의 성능을 비교하여 보여줍니다. #A-Params는 추론 중 활성화된 매개변수의 수를 나타냅니다. SynerGen-VL은 활성화된 매개변수 2.4B개만으로 Emu3-Chat-8B와 같은 훨씬 더 큰 인코더 프리 통합 MLLM보다 우수한 성능을 달성하고 있습니다. 특히 고해상도 이미지 이해 능력이 필요한 OCRBench, TextVQA, DocVQA, ChartQA와 같은 벤치마크에서 SynerGen-VL은 훨씬 더 큰 인코더 프리 MLLM보다 우수한 결과를 달성하여 고해상도 이미지 처리 능력의 장점을 보여줍니다. 또한 SynerGen-VL은 LLaVA-1.5와 같은 인코더 기반 이해 전용 MLLM과 비슷한 이미지 이해 성능을 보여주는 동시에 EVE-7B 및 Fuyu-8B(HD)와 같은 더 큰 인코더 프리 작업별 MLLM보다 뛰어난 성능을 보입니다. 이는 이미지 이해와 생성을 통합하는 데 큰 잠재력이 있음을 시사합니다. Chameleon의 일부 결과는 [51]에서 가져왔습니다.
read the caption
Table 3: Comparison with existing MLLMs on visual question answering benchmarks. #A-Params denotes the number of activated parameters during inference. ⋄Some results of Chameleon are sourced from [51].
| Method | # A-Param | Single Obj. | Two Obj. | Counting | Colors | Position | Color Attri. | Overall ↑ |
|---|---|---|---|---|---|---|---|---|
| Generation Only | ||||||||
| LlamaGen [75] | 0.8B | 0.71 | 0.34 | 0.21 | 0.58 | 0.07 | 0.04 | 0.32 |
| LDM [65] | 1.4B | 0.92 | 0.29 | 0.23 | 0.70 | 0.02 | 0.05 | 0.37 |
| SDv1.5 [65] | 0.9B | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 | 0.43 |
| SDXL [61] | 2.6B | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | 0.55 |
| PixArt-α [9] | 0.6B | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 | 0.48 |
| DALL-E 2 [64] | 6.5B | 0.94 | 0.66 | 0.49 | 0.77 | 0.10 | 0.19 | 0.52 |
| Understanding & Generation | ||||||||
| SEED-X† [24] | 17B | 0.97 | 0.58 | 0.26 | 0.80 | 0.19 | 0.14 | 0.49 |
| Show-o [96] | 1.3B | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | 0.53 |
| LWM [45] | 7B | 0.93 | 0.41 | 0.46 | 0.79 | 0.09 | 0.15 | 0.47 |
| Chameleon [8] | 34B | - | - | - | - | - | - | 0.39 |
| Emu3-Gen [91] | 8B | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | 0.54 |
| Janus [92] | 1.3B | 0.97 | 0.68 | 0.30 | 0.84 | 0.46 | 0.42 | 0.61 |
| SynerGen-VL (Ours) | 2.4B | 0.99 | 0.71 | 0.34 | 0.87 | 0.37 | 0.37 | 0.61 |
🔼 이 표는 GenEval 벤치마크에서 텍스트-이미지 생성 평가 결과를 보여줍니다. #A-Params는 추론 중 활성화된 매개변수의 수를 나타냅니다. ††는 외부에서 미리 학습된 확산 모델을 사용하는 모델을 나타냅니다. Obj.는 Object를, Attri.는 Attribution을 나타냅니다. 다양한 객체, 객체 수, 색상, 위치, 색상 속성과 같은 객체 수준 이미지-텍스트 정렬 기준에 따라 모델 성능을 비교합니다.
read the caption
Table 4: Evaluation of text-to-image generation on GenEval [25] benchmark. #A-Params denotes the number of activated parameters during inference. ††{\dagger}† indicates models with external pretrained diffusion model. Obj.: Object. Attri.: Attribution.
| Model | #A-Param | MS-COCO↓ | MJHQ↓ |
|---|---|---|---|
| Generation Only | |||
| DALL-E [63] | 12B | 27.50 | - |
| LDM [65] | 1.4B | 12.64 | - |
| GLIDE [58] | 5B | 12.24 | - |
| DALL-E 2 [64] | 6.5B | 10.39 | - |
| RAPHAEL [97] | 3B | 6.61 | - |
| Imagen [66] | 34B | 7.27 | - |
| SDv1.5 [65] | 0.9B | 9.62 | - |
| SDXL [61] | 0.9B | 7.38 | 8.76 |
| PixArt-α [9] | 0.6B | 7.32 | 6.14 |
| Understanding & Generation | |||
| NExT-GPT [93] | 13B | 11.18 | - |
| SEED-X [24] | 17B | 14.99 | - |
| Show-o [96] | 1.3B | 9.24 | 15.18 |
| LWM [45] | 7B | 12.68 | 17.77 |
| VILA-U [94] | 7B | - | 7.69 |
| Emu3-Gen [91] | 8B | 19.3 | - |
| Janus [92] | 1.3B | 8.53 | 10.10 |
| SynerGen-VL (Ours) | 2.4B | 7.65 | 6.10 |
🔼 이 표는 MSCOCO-30K와 MJHQ-30K 데이터셋에서 이미지 생성 모델의 성능을 FID 점수로 비교합니다. #A-Param은 추론 중 활성화된 매개변수의 수를 나타냅니다. 표에는 이미지 생성 전용 모델과 이해 및 생성 기능을 모두 갖춘 통합 멀티모달 대규모 언어 모델(MLLM)의 결과가 포함되어 있습니다. 각 모델에 대해 활성화된 매개변수 수와 함께 두 데이터셋에 대한 FID 점수가 표시됩니다.
read the caption
Table 5: Image generation results on MSCOCO-30K [40] and MJHQ-30K [35] datasets. FID [27] is reported. #A-Param denotes the number of activated parameters during inference.
| Model | TextVQA | GQA | DocVQA | AI2D | ChartQA | InfoVQA |
|---|---|---|---|---|---|---|
| w/o token folding | 18.7 | 45.3 | 14.7 | 42.0 | 20.9 | 18.7 |
| w/ token folding | 35.0 | 45.1 | 36.7 | 42.1 | 49.7 | 21.1 |
🔼 토큰 접기 유무에 따른 VQA 벤치마크 성능 비교표입니다. 동일한 이미지 토큰 시퀀스 길이에서 토큰 접기를 사용한 모델이 성능이 크게 향상됨을 보여줍니다. 이 표는 고해상도 이미지 이해에 대한 토큰 접기의 효과를 검증하기 위해 SynerGen-VL이 토큰 접기 없이, 그리고 동적 해상도 전략 없이 기준 버전과 비교한 결과를 보여줍니다. 기준 모델은 토큰 접기 없이 토큰화된 시퀀스를 입력 이미지 시퀀스로 직접 사용하며, 입력 이미지 크기는 256x256이고 토큰화된 시퀀스 길이는 1024입니다. 토큰 접기를 사용하는 모델의 경우, 고해상도 입력 이미지를 제공하기 위해 동적 해상도 전략을 구현합니다. 공정한 비교를 위해 토큰 접기 비율을 2x4로 사용하고 토큰 접기 후 이미지 토큰 시퀀스의 평균 길이가 1024가 되도록 동적 이미지 패치의 최대 개수를 제어합니다. 2단계(S.2) 이해 데이터의 하위 집합으로 모델을 학습시키고, VQA 벤치마크에서 사전 학습된 모델을 평가합니다. TextVQA, DocVQA, ChartVQA, InfoVQA와 같은 상세한 이미지 정보에 대한 정확한 이해가 필요한 데이터 세트에서 토큰 접기를 사용한 모델이 훨씬 더 나은 결과를 달성하여 고해상도 이미지 이해의 이점을 보여줍니다.
read the caption
Table 6: Comparison between models with and without token-folding on VQA benchmarks. The model with token folding demonstrates significant performance improvements with the same image token sequence length.
| Stage | Strategy | TextVQA | GQA | DocVQA | AI2D | ChartQA | InfoVQA | MMLU | CMMLU | AGIEVAL | MATH | MSCOCO |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline (Qwen2-0.5B) | - | - | - | - | - | - | 42.3 | 51.4 | 29.3 | 12.1 | - | |
| S.1 + S.2 | Full | 14.3 | 42.9 | 11.3 | 24.7 | 12.4 | 12.6 | 23.1 | 23.0 | 8.1 | 0.9 | 30.7 |
| S.1 only | Progressive | 0.1 | 13.0 | 0.2 | 0.3 | 0.0 | 0.0 | 42.3 | 51.4 | 29.3 | 12.1 | 28.3 |
| S.2 only | Progressive | 8.7 | 36.9 | 8.6 | 40.9 | 11.7 | 16.2 | 37.6 | 45.3 | 28.9 | 7.2 | 34.9 |
| S.1 + S.2 | Progressive | 13.2 | 41.2 | 11.4 | 41.9 | 12.8 | 17.0 | 39.3 | 48.2 | 26.2 | 8.9 | 20.2 |
🔼 이 표는 다양한 사전 훈련 전략의 제로샷 성능을 비교합니다. ‘S.1’과 ‘S.2’는 각각 첫 번째 및 두 번째 사전 훈련 단계를 나타냅니다. ‘전체’는 전체 매개변수 조정을 나타내고, ‘점진적’은 MMoE를 사용한 점진적 조정 전략을 나타냅니다. MSCOCO에서 텍스트-이미지 생성(T2I)에 대해 FID가 보고됩니다.
read the caption
Table 7: Zero-shot performance of different pre-training strategies. “S.1” and “S.2” denote the first and second pre-training stage. “Full” and “Progressive” denote the full parameter tuning and our progressive tuning strategy with MMoEs, respectively. FID [27] is reported for text-to-image generation (T2I) on MSCOCO [40].
| Configuration | Alignment Pre-training | Instruction |
|---|---|---|
| S.1 | S.2 | |
| Maximum number of image tiles | 1 | 6 |
| LLM sequence length | 4,096 | 8,192 |
| Use thumbnail | ✗ | ✓ |
| Global batch size (per-task) | 6,988 | 5,090 |
| Peak learning rate | 1e^{-4} | 5e^{-5} |
| Learning rate schedule | constant with warm-up | cosine decay |
| Weight decay | 0.05 | 0.05 |
| Training steps | 95k | 35k |
| Warm-up steps | 200 | 200 |
| Optimizer | AdamW | AdamW |
| Optimizer hyperparameters | \beta_{1}=0.9,\beta_{2}=0.95,eps=1e^{-8} | \beta_{1}=0.9,\beta_{2}=0.95,eps=1e^{-8} |
| Gradient accumulation | 1 | 1 |
| Numerical precision | bfloat16 | bfloat16 |
🔼 이 표는 SynerGen-VL 모델의 사전 훈련 및 명령어 미세 조정 단계에서 사용된 하이퍼파라미터들을 보여줍니다. 사전 훈련 단계는 두 단계로 나뉘며, 각 단계마다 이미지 타일 최대 개수, LLM 시퀀스 길이, 썸네일 사용 여부, 글로벌 배치 크기, 최대 학습률, 학습률 스케줄, 가중치 감쇠, 훈련 단계, 웜업 단계, 옵티마이저 종류 및 하이퍼파라미터, 그래디언트 누적, 그리고 수치 정밀도 등의 설정값들을 보여주고, 명령어 미세 조정 단계의 하이퍼파라미터 설정값들도 함께 비교하여 제시합니다.
read the caption
Table 8: Hyper-parameters used in the alignment pre-training and instruction tuning stages.
Full paper#



















