↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Key Takeaways#
Why does it matter?#
BiMediX2는 의료 AI 분야의 중요한 발전을 나타냅니다. 이중 언어 및 다중 모드 기능은 의료 정보에 대한 접근성과 형평성을 향상시킬 수 있는 잠재력을 가지고 있습니다. 연구자들은 이 모델을 사용하여 다양한 의료 영상 양식을 분석하고, 복잡한 의료 대화를 수행하고, 의료 보고서를 요약 및 생성할 수 있습니다. 이러한 기능은 진단, 치료 계획 및 환자 교육을 포함한 다양한 의료 응용 분야에 유용할 수 있습니다. 또한 BiMed-V 데이터 세트와 BiMed-MBench 벤치마크의 공개는 의료 AI 연구 커뮤니티에 귀중한 리소스를 제공하여 추가 연구 및 개발을 촉진합니다.
Visual Insights#
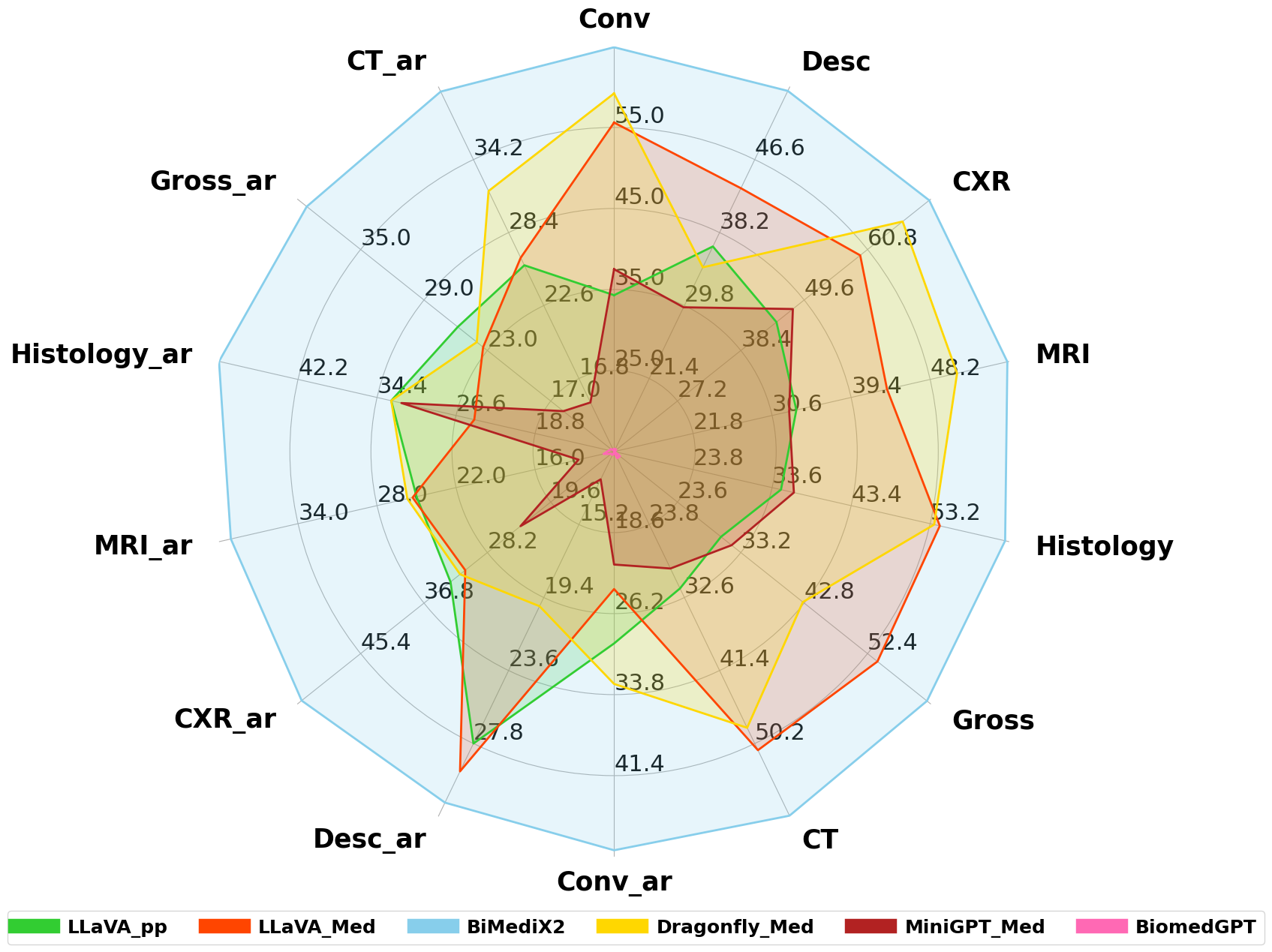
🔼 이 그림은 BiMed-MBench에서 여러 의료 LMM의 성능을 비교한 레이더 차트입니다. CT, MRI, CXR, 조직학, 그로스 이미지와 같은 다양한 의료 영상 범주와 각각의 아랍어 범주에서 LLaVA-pp, LLaVA-Med, BiMediX2, Dragonfly-Med, MiniGPT-Med, BiomedGPT 등의 모델 성능을 비교합니다. 각 축은 특정 범주에서의 성능 점수를 나타내며, 각 모델이 이중 언어 의료 환경에서 얼마나 잘 수행되는지 시각적으로 비교할 수 있도록 합니다.
read the caption
Figure 1: Model Performance Comparison on BiMed-MBench: These comparisons are made across different categories, including CT, MRI, CXR, Histology, Gross, and their Arabic counterparts (CT_ar, MRI_ar, CXR_ar, Histology_ar, Gross_ar). The models compared are LLaVA-pp, LLaVA-Med, BiMediX2, Dragonfly-Med, MiniGPT-Med, and BiomedGPT. Each axis represents the performance score in a specific category, allowing for a visual comparison of how each model performs in bilingual medical contexts.
| Model | MTC | RS | RG | Rad | Oph | Path | Micro | LLM+VLM | Bil (Ar) |
|---|---|---|---|---|---|---|---|---|---|
| Meditron (Chen et al. (2023)) | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 |
| Med42 (Christophe et al. (2024)) | \usym2713 | \usym2713 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 |
| OpenBioLLM (Ankit Pal (2024)) | \usym2713 | \usym2713 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 |
| Llama3.1 (Meta (2024)) | \usym2713 | \usym2713 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 |
| BiMediXv1 (Pieri et al. (2024)) | \usym2713 | \usym2713 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 | \usym2717 |
🔼 이 표는 최신 의료 LLM 및 VLM을 비교하고 있습니다. MTC(다중 대화), RS(보고서 요약), RG(보고서 생성), Rad(방사선학), Oph(안과학), Path(병리학), Micro(현미경), UM(통합 모델: 모든 다운스트림 작업에 대한 단일 모델 체크포인트), LLM+VLM(통합 LLM + VLM), Bil(Ar)(아랍어 이중 언어 기능)과 같은 다양한 기능과 아랍어 지원 여부를 포함하여 각 모델의 기능을 요약합니다.
read the caption
Table 1: Comparison of Recent Medical LLMs and VLMs. Abbreviations: MTC (Multi-turn conversation), RS (Report Summarization), RG (Report Generation), Rad (Radiology), Oph (Ophthalmology), Path (Pathology), Micro (Microscopic), UM (Unified Model: Single model checkpoint for all downstream tasks), LLM+VLM (Unified LLM + VLM), Bil (Ar) (Bilingual Arabic capabilities).
In-depth insights#
Bilingual Medical LMM#
이중 언어 의료 LMM은 의료 분야에서 혁신적인 발전을 의미합니다. 영어와 아랍어 모두에서 작동하도록 설계된 BiMediX2와 같은 모델은 의료 서비스의 접근성과 형평성을 향상시킬 수 있는 잠재력을 가지고 있습니다. 이러한 모델은 의료 영상 분석과 복잡한 의료 대화를 포함한 다양한 작업을 위해 텍스트 및 시각적 양식을 통합합니다. 이중 언어 기능은 언어 장벽을 허물고 의료 전문가와 환자에게 더 많은 포용적인 경험을 제공합니다. 그러나 환각, 독성 및 고정 관념과 같은 과제는 이러한 모델의 개발 및 배포에서 해결해야 하는 중요한 문제입니다. 또한 의료 진단 및 권장 사항의 정확성을 보장하기 위해 엄격한 검증 및 품질 관리 조치가 필수적입니다. 환자의 개인 정보 보호 및 의료 데이터의 기밀성과 같은 윤리적 고려 사항도 이중 언어 의료 LMM의 개발 및 적용에서 우선적으로 고려되어야 합니다. 의료 전문가, 환자 및 윤리 전문가와 협력하여 윤리적 감독을 보장하고 임상 환경에서의 안전과 정확성을 개선하기 위한 추가 연구가 필요합니다.
BiMediX2 Architecture#
BiMediX2는 의료 이미지 분석 및 이중 언어 다중 대화를 위한 통합 아키텍처를 사용합니다. 이미지 인코더(Vision Encoder)는 다양한 의료 영상 양식을 처리하고, 프로젝터(Projector)는 텍스트 입력값과 정확하게 정렬하여 풍부한 의료 이미지-텍스트 매핑을 보장합니다. 텍스트 입력값은 표준 토크나이저를 사용하여 처리되어 Llama 3.1의 언어 임베딩 공간으로 변환됩니다. 이 디자인 덕분에 BiMediX2는 사용자 프롬프트에 따라 영어 또는 아랍어로 정확하고 맥락에 맞는 응답을 생성할 수 있습니다. BiMediX2의 성능의 핵심은 모듈식 및 효율적인 교육 접근 방식입니다. LoRA 어댑터는 언어 모델을 미세 조정하는 데 사용되며, 프로젝터는 의료 맥락에서 이미지-텍스트 정렬을 최적화하기 위해 미세 조정됩니다. 또한 이 시스템은 강력한 데이터 생성 프레임워크의 지원을 받습니다. 여기서 포괄적인 영어 데이터 코퍼스가 GPT-40을 사용하여 아랍어로 번역됩니다. 이중 언어 의료 전문가가 이 번역의 무작위 하위 집합을 꼼꼼하게 검증하여 임상적 관련성과 언어적 정확성을 보장합니다. 이 파이프라인을 통해 BiMediX2는 보고서 생성, 방사선 분석, 병리학적 통찰력, 안과 평가를 포함한 광범위한 의료 작업에서 탁월한 성능을 발휘하며, 이 모든 것이 통합된 이중 언어 및 다중 양식 프레임워크 내에서 이루어집니다.
Dataset Creation#
BiMediX2는 아랍어-영어 의료 LMM으로, 광범위한 의료 작업을 처리하기 위해 160만 개 샘플의 대규모 이중 언어 다중 모드 의료 교육 데이터 세트인 BiMed-V에서 교육되었습니다. 이 데이터 세트에는 PMC-OA, Rad-VQA, Path-VQA, SLAKE와 같은 공개적으로 사용 가능한 데이터 세트와 맞춤형 큐레이션된 데이터가 통합되어 의료 이미지-텍스트 정렬 및 다중 모드 이해가 향상되었습니다. LLaVA-Med의 60K-IM 데이터 세트를 용도 변경하여 163k VQA 샘플을 선별하여 실제 의료 질의에 맞췄습니다. 또한 LLaVA-Med 사전 교육 데이터 세트의 10k 이상 샘플을 Llama 3.1 70B 모델을 사용하여 대화형 대화로 다시 포맷했습니다. 짧은 질문-답변 쌍과 여러 선택 질문이 있는 PMC-OA 데이터 세트의 하위 집합이 데이터 세트의 다양성을 향상시키기 위해 추가되었습니다. 일반적으로 간결한 답변이 특징인 Rad-VQA, Path-VQA 및 SLAKE의 교육 분할은 동일한 Llama 3.1 70B 모델을 사용하여 더 자세한 응답으로 재구성되어 복잡한 작업에 대한 데이터 세트의 깊이와 유용성을 향상시켰습니다. BiMed-V의 고유한 특징은 다양한 의료 영상 양식에 걸쳐 326k 샘플로 구성된 다중 양식 교육 세트를 통해 촉진되는 이중 언어 지원입니다. 여기에는 포괄적인 번역 프레임워크를 통해 생성된 163k 아랍어 샘플이 포함됩니다. 영어 데이터 세트는 GPT-40을 사용하여 아랍어로 번역되었으며, 이중 언어 의료 전문가가 임의 하위 집합을 엄격하게 검증하여 임상적 관련성과 언어적 정확성을 보장했습니다. 이러한 하이브리드 접근 방식은 자동화와 전문가 검증의 균형을 유지하여 인간 의료 도메인 전문가에 대한 의존도를 크게 줄이면서 데이터 품질을 유지합니다. 또한 BiMediXv1의 텍스트 기반 임상 데이터를 포함하면 데이터 세트가 강력한 언어 이해 능력을 유지하면서 다중 양식 의료 숙련도를 확장합니다. 이 광범위한 데이터 세트는 고급 의료 이미지-텍스트 정렬 및 대화형 다중 양식 응용 프로그램의 기반을 형성합니다.
Multimodal Benchmarks#
멀티모달 벤치마크는 의료 LMM의 성능 평가에 매우 중요합니다. 텍스트 기반 작업만으로는 이미지 이해 및 해석 능력을 제대로 평가할 수 없습니다. BiMediX2와 같은 모델은 이미지 기반 의료 질의응답, 보고서 생성, 요약과 같은 작업에서 멀티모달 벤치마크를 통해 평가되어야 합니다. 이러한 벤치마크는 다양한 의료 영상 양식(예: X-레이, CT, MRI, 조직 슬라이드)과 질의 유형을 포함해야 합니다. 또한, 다국어 지원을 평가하기 위해 BiMed-MBench와 같은 이중 언어 벤치마크가 필요합니다. 이러한 포괄적인 벤치마크를 통해 의료 LMM의 실제 성능을 정확하게 측정하고, 임상 환경에서의 안전하고 효과적인 적용을 보장할 수 있습니다.
Arabic/English Evaluations#
BiMediX2는 아랍어와 영어 모두에서 의료 영상 이해 및 텍스트 기반 의료 LLM 평가에서 최첨단 성능을 달성한 최초의 이중 언어 의료 LLM입니다. BiMediX2는 160만 개 이상의 지침으로 구성된 포괄적인 아랍어-영어 다중 모드 이중 언어 명령어 세트인 BiMed-V에서 훈련되었습니다. 이중 언어 기능을 통해 다양한 의료 작업에서 텍스트 및 시각적 양식을 원활하게 통합할 수 있습니다. BiMediX2는 의료 이미지 분석과 이중 언어 다중 턴 대화를 용이하게 하도록 세심하게 설계되었습니다. 이 모델은 다양한 의료 영상 모드를 처리하기 위해 Vision Encoder를 사용하고 텍스트 입력을 Meta Llama 3.1의 언어 임베딩 공간으로 변환하는 표준 토크나이저를 사용합니다. BiMediX2의 성능의 핵심은 모듈식이고 효율적인 교육 접근 방식입니다. 영어 평가에서 9% 이상, 아랍어 평가에서 20% 이상 향상된 BiMediX2 LLM은 BiMed-MBench에서 최첨단 결과를 달성했습니다. 또한 의학적 시각적 질문 답변, 보고서 생성 및 보고서 요약 작업에서 탁월한 성능을 보입니다. 아랍어 지원을 통해 아랍어 사용 지역의 의료 요구 사항을 해결하여 다양하고 다국어 및 다중 모드 의료 애플리케이션을 위한 포괄적이고 포괄적인 솔루션을 제공합니다.
More visual insights#
More on figures

🔼 BiMediX2는 의료 이미지 분석과 이중 언어 다중 대화를 위해 설계된 모델입니다. 의료 이미지는 Vision Encoder를 통해 처리되고 Projector와 정렬되는 반면, 텍스트 입력은 기본 토크나이저를 사용하여 토큰화됩니다. 결과 토큰은 언어 모델(Meta Llama 3.1)로 전달되어 프롬프트된 언어로 응답을 생성합니다. 언어 모델은 LoRA 어댑터를 사용하여 훈련되고 프로젝터는 의료 이미지-텍스트 정렬을 위해 미세 조정됩니다. 강력한 데이터 생성 프레임워크는 영어 데이터 코퍼스를 GPT-40를 사용하여 아랍어로 번역하고 의료 전문가의 검증을 통해 정확하고 문맥적으로 적절한 번역을 보장합니다. 이 접근 방식은 이중 언어 컨텍스트에서 효과적인 훈련 및 벤치마킹을 지원합니다.
read the caption
Figure 2: BiMediX2: Overall Architecture Our model is designed for medical image analysis and bilingual multi-turn conversations. Medical images are processed through a Vision Encoder and aligned with a Projector, while the text inputs are tokenized using the default tokenizer. The resulting tokens are then passed into the language model (Meta Llama 3.1) to generate responses in the prompted language. We only train the language model using LoRA adapters, while the projector is finetuned for medical image-text alignment. A robust data generation framework translates an English data corpus into Arabic using GPT-4o, with verification by a medical expert to ensure accurate and contextually appropriate translations. This approach supports effective training and benchmarking in a bilingual context.

🔼 이 그림은 다양한 임상 LLM 벤치마크에서 여러 의료 LLM 모델의 성능을 비교하여 보여줍니다. BiMediX2 70B는 PubMedQA, MedQA, MedMCQA, USMLE, Medical MMLU를 포함한 대부분의 벤치마크에서 최고 점수를 달성했습니다. 이는 BiMediX2가 의료 분야에서 다른 모델보다 우수한 성능을 보인다는 것을 나타냅니다.
read the caption
Figure 3: State of the art comparison of models in Clinical LLM Benchmarks

🔼 이 그림은 다양한 의료 LLM의 UPHILL OpenQA 벤치마크에서의 성능 비교를 보여줍니다. UPHILL OpenQA는 다양한 단계의 전제를 포함하는 건강 관련 질문을 처리할 때 LLM의 사실적 정확성을 평가합니다. BiMediX2 70B는 60.6%의 최고 전체 사실적 정확도를 달성했으며, BiMediX2 8B(56.1%)가 그 뒤를 이었습니다. GPT-4(51.5%), Meditron 70B(49.6%), Med42(53.5%)와 같은 다른 모델보다 성능이 뛰어났습니다. 이는 의료 관련 허위 주장을 구별하고 수정하는 BiMediX2의 효과를 보여줍니다.
read the caption
Figure 4: Performance comparison on UPHILL OpenQA (Kaur et al. (2023)), assessing the model’s ability to address false medical claims at different presupposition levels.

🔼 이 그림은 대화형 상황에서 BiMediX2의 의료 이미지 이해 능력을 보여주는 정성적 예시입니다. 상단 부분은 요추의 시상 CT 스캔과 관련된 대화를 보여줍니다. 모델은 스캔 유형을 식별하고 척추의 아랫부분에 초점을 맞춘 신체의 수직 단면이라고 설명합니다. 이상 여부를 묻자 모델은 L4 척추의 골절을 정확하게 식별하고 외상이나 스트레스와 같은 잠재적인 원인에 대한 설명을 제공합니다. 하단 부분은 왼쪽 난소의 컬러 도플러 초음파 스캔을 보여주고, 왼쪽 난소 낭종이라는 잠재적 이상을 식별합니다. 모델은 영상 기술을 설명하고, 장기를 명명하고, 검출된 이상을 논의하면서 추가 평가의 필요성을 강조합니다. 이러한 예시는 BiMediX2가 복잡한 의료 영상을 해석하고 임상 의사 결정을 지원하는 유득한 답변을 제공하는 능력을 보여줍니다.
read the caption
Figure 5: Qualitative Examples of our BiMediX2 for Medical Image Understanding in a Conversational Context.
More on tables
| Model | MTC | RS | RG | Rad | Oph | Path | Micro | UM | LLM+VLM | Bil (Ar) |
|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA-pp (Rasheed et al. (2024)) | 2713 | 2713 | 2717 | 2717 | 2717 | 2717 | 2717 | 2713 | 2717 | 2717 |
| MiniGPT-Med (Alkhaldi et al. (2024)) | 2717 | 2713 | 2713 | 2713 | 2717 | 2717 | 2717 | 2713 | 2717 | 2717 |
| BioMedGPT (Zhang et al. (2024)) | 2717 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2717 | 2717 | 2717 |
| LLaVA-Med (Li et al. (2023)) | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2717 | 2717 |
| Dragonfly VLM (Chen et al. (2024)) | 2717 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2717 | 2717 |
| BiMediX2 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 | 2713 |
🔼 이 표는 다양한 의료 LLM 벤치마크에서 BiMediX2 및 기타 모델의 성능을 보여줍니다. 여기에는 MedMCQA, MedQA, USMLE, PubMedQA 및 Medical MMLU가 포함됩니다. BiMediX2 70B는 84.6%의 최고 평균 점수를 달성하여 GPT-4(82.9%) 및 Llama-3-Med42-70B(83.0%)와 같은 다른 모델보다 성능이 뛰어났습니다. 이 결과는 의료 관련 텍스트 기반 작업에 대한 BiMediX2의 강력한 이해를 강조합니다.
read the caption
Table 2: Clinical LLM Evaluation Benchmark
| Model | Cli-KG | C-Bio | C-Med | Med-Gen | Pro-Med | Ana | MedMCQA | MedQA | USMLE | PubmedQA | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BioMedGPT-LM-7B | 49.4 | 43.1 | 41.4 | 45.0 | 51.0 | 45.2 | 34.8 | 33.2 | 31.7 | 74.0 | 44.9 |
| BiMediX2 4B | 55.1 | 63.9 | 47.4 | 55.0 | 36.0 | 52.6 | 38.1 | 37.9 | 47.1 | 72.2 | 50.5 |
| LLaVA-Med | 59.6 | 59.7 | 50.9 | 59.0 | 51.5 | 51.9 | 44.5 | 35.7 | 36.9 | 74.0 | 52.4 |
| Dragonfly-Med | 65.6 | 69.4 | 56.6 | 69.0 | 58.4 | 57.0 | 49.9 | 42.8 | 46.1 | 75.4 | 59.0 |
| GPT 3.5 | 69.8 | 72.2 | 61.3 | 70.0 | 70.2 | 56.3 | 50.1 | 50.8 | 49.1 | 71.6 | 62.1 |
| Meditron 70B | 68.3 | 77.8 | 63.6 | 75.0 | 74.6 | 56.3 | 48.4 | 53.1 | 55.4 | 76.2 | 64.9 |
| BiMediX2 8B | 77.7 | 79.2 | 68.8 | 82.0 | 74.3 | 65.9 | 58.0 | 57.0 | 68.6 | 72.4 | 70.4 |
| GPT 4 | 86.0 | 95.1 | 76.9 | 91.0 | 93.0 | 80.0 | 69.5 | 78.9 | 83.8 | 75.2 | 82.9 |
| Llama3-Med42-70B | 84.2 | 93.1 | 79.8 | 91.0 | 90.1 | 80.7 | 72.5 | 73.8 | 84.3 | 80.6 | 83.0 |
| OpenBioLLM-70B | 92.5 | 93.8 | 85.6 | 93.0 | 93.4 | 83.7 | 74.1 | 68.9 | 72.0 | 78.0 | 83.5 |
| Llama 3.1 70B | 83.4 | 95.1 | 79.2 | 93.0 | 91.5 | 80.7 | 71.7 | 73.8 | 92.0 | 77.6 | 83.8 |
| BiMediX2 70B | 86.8 | 95.1 | 79.8 | 94.0 | 91.5 | 82.2 | 70.5 | 74.3 | 92.3 | 79.0 | 84.6 |
🔼 BiMediX2 및 기타 의료 LLM의 영어 BiMed-MBench 벤치마크에 대한 평가 결과를 보여줍니다. 이 표는 대화, 설명, CXR, MRI, 조직학, Gross, CT와 같은 다양한 범주에 대한 각 모델의 성능 점수를 보여줍니다. BiMediX2 8B는 전반적으로 62.2점으로 가장 높은 점수를 받았으며, 이는 의료 이미지 이해 및 다양한 영상 양식에서 의료 대화 및 설명을 처리하는 데 있어서의 효과를 보여줍니다.
read the caption
Table 3: BiMed-MBench English Evaluation
| Model | Conversation | Description | CXR | MRI | Histology | Gross | CT | Overall |
|---|---|---|---|---|---|---|---|---|
| BiomedGPT | 15.3 | 13.3 | 16.4 | 13.0 | 14.1 | 14.9 | 15.8 | 14.8 |
| LLaVA-pp | 34.3 | 36.6 | 44.7 | 33.3 | 34.7 | 30.2 | 31.5 | 34.9 |
| MiniGPT-Med | 37.5 | 29.6 | 47.6 | 32.5 | 36.3 | 31.8 | 29.1 | 35.4 |
| LLaVA-Med | 55.6 | 43.3 | 59.5 | 43.4 | 54.4 | 53.9 | 51.0 | 52.4 |
| Dragonfly-Med | 59.2 | 34.2 | 67.0 | 51.2 | 53.7 | 42.6 | 48.3 | 52.7 |
| BiMediX2 8B | 64.9 | 54.5 | 71.7 | 56.8 | 62.5 | 61.4 | 58.9 | 62.2 |
🔼 BiMediX2 및 다른 의료 LMM의 아랍어 BiMed-MBench 벤치마크에 대한 평가 결과를 보여줍니다. BiMediX2 8B는 다른 모델보다 뛰어난 성능을 보여줍니다.
read the caption
Table 4: BiMed-MBench Arabic Evaluation
| Model | Conversation | Description | CXR | MRI | Histology | Gross | CT | Overall |
|---|---|---|---|---|---|---|---|---|
| BiomedGPT | 11.1 | 11.2 | 11.4 | 10.8 | 11.5 | 11.3 | 11.1 | 11.2 |
| MiniGPT-Med | 21.6 | 12.6 | 23.7 | 12.7 | 32.0 | 15.8 | 14.9 | 20.2 |
| LLaVA-Med | 23.9 | 29.4 | 31.2 | 25.3 | 24.8 | 23.4 | 26.4 | 26.2 |
| LLaVA-pp | 29.0 | 27.8 | 33.2 | 25.0 | 33.0 | 25.8 | 25.8 | 28.7 |
| Dragonfly-Med | 32.8 | 19.9 | 31.9 | 25.7 | 33.0 | 24.0 | 31.7 | 29.5 |
| BiMediX2 8B | 54.3 | 36.2 | 61.4 | 44.6 | 51.5 | 43.5 | 50.8 | 50.5 |
🔼 표 5는 여러 의료 VQA 벤치마크에서 BiMediX2 및 다른 모델의 성능을 MultiMedEval 툴킷을 사용하여 비교합니다. BiMediX2 8B는 Rad-VQA, Slake-VQA 및 Path-VQA와 같은 데이터 세트에서 다른 모델보다 높은 평균 점수를 달성했습니다. 이는 BiMediX2가 의료 진단에서 중요한 작업인 시각적 질문 답변 능력이 뛰어나다는 것을 보여줍니다.
read the caption
Table 5: Medical VQA Benchmark (MultiMedEval Royer et al. (2024))
| Dataset | Metric | RadFM | LLaVA Med | BioMedGPT | MiniGPT-Med | Phi-3.5 V | BiMediX2 4B | BiMediX2 8B |
|---|---|---|---|---|---|---|---|---|
| Rad-VQA | BLEU-1↑ | 0.475 | 0.033 | 0.044 | 0.662 | 0.377 | 0.501 | 0.552 |
| closed Q accuracy↑ | 0.577 | 0.545 | 0.203 | 0.829 | 0.618 | 0.685 | 0.725 | |
| open Q recall↑ | 0.407 | 0.246 | 0.199 | 0.546 | 0.295 | 0.292 | 0.363 | |
| recall↑ | 0.438 | 0.372 | 0.199 | 0.703 | 0.475 | 0.511 | 0.565 | |
| open Q accuracy↑ | 0.335 | 0.140 | 0.150 | 0.490 | 0.200 | 0.225 | 0.305 | |
| F1 ↑ | 0.442 | 0.069 | 0.064 | 0.675 | 0.391 | 0.516 | 0.569 | |
| Slake-VQA | BLEU-1↑ | 0.746 | 0.036 | 0.175 | 0.337 | 0.089 | 0.625 | 0.778 |
| closed Q accuracy↑ | 0.752 | 0.512 | 0.248 | 0.572 | 0.535 | 0.744 | 0.831 | |
| open Q recall↑ | 0.758 | 0.429 | 0.293 | 0.308 | 0.377 | 0.624 | 0.763 | |
| recall↑ | 0.695 | 0.443 | 0.260 | 0.396 | 0.404 | 0.664 | 0.786 | |
| open Q accuracy↑ | 0.725 | 0.362 | 0.259 | 0.278 | 0.329 | 0.567 | 0.729 | |
| F1 ↑ | 0.714 | 0.075 | 0.192 | 0.349 | 0.129 | 0.641 | 0.787 | |
| Path-VQA | BLEU-1↑ | 0.257 | 0.021 | 0.145 | 0.296 | 0.283 | 0.469 | 0.587 |
| closed Q accuracy↑ | 0.505 | 0.512 | 0.260 | 0.581 | 0.553 | 0.708 | 0.872 | |
| open Q recall↑ | 0.020 | 0.116 | 0.093 | 0.040 | 0.063 | 0.239 | 0.314 | |
| recall↑ | 0.221 | 0.287 | 0.176 | 0.311 | 0.308 | 0.474 | 0.593 | |
| open Q accuracy↑ | 0.005 | 0.053 | 0.077 | 0.019 | 0.027 | 0.210 | 0.282 | |
| F1 ↑ | 0.232 | 0.052 | 0.154 | 0.299 | 0.287 | 0.475 | 0.595 | |
| Average | 0.461 | 0.239 | 0.177 | 0.427 | 0.319 | 0.509 | 0.611 |
🔼 이 표는 보고서 요약 성능을 평가한 결과를 보여줍니다. MIMIC-III 데이터셋을 사용했으며, BiMediX2 8B 모델이 다른 모델들보다 더 높은 평균 점수를 기록했습니다. 이는 BiMediX2 8B가 의료 보고서를 간결하고 정확하게 요약하는 데 효과적임을 시사합니다.
read the caption
Table 6: Report Summarization (MultiMedEval Royer et al. (2024))
| Dataset | Metric | LLaVA Med | Dragonfly-Med | BiMediX2 4B | BiMediX2 8B |
|---|---|---|---|---|---|
| MIMIC-III | ROUGE-L↑ | 0.185 | 0.072 | 0.209 | 0.205 |
| BLEU-1↑ | 0.192 | 0.062 | 0.153 | 0.178 | |
| BLEU-4↑* | 0.520 | 0.000 | 0.410 | 0.449 | |
| F1-RadGraph↑ | 0.232 | 0.000 | 0.222 | 0.230 | |
| RadCliQ↑* | 0.753 | 0.247 | 0.923 | 0.918 | |
| CheXbert vector↑ | 0.600 | 0.326 | 0.633 | 0.593 | |
| METEOR↑ | 0.303 | 0.060 | 0.264 | 0.339 | |
| Average | 0.398 | 0.110 | 0.402 | 0.416 |
🔼 이 표는 MIMIC-CXR 데이터셋에 대한 보고서 생성 성능을 보여줍니다. BiMediX2 8B는 LLaVA-Med(0.192) 및 BioMedGPT(0.145)와 같은 다른 모델보다 0.235의 가장 높은 평균 점수를 달성했습니다. 평균 점수는 BLUE-4* 및 RadCliQ* 메트릭을 다시 스케일링하여 통합 메트릭으로 도출됩니다. 이는 진단 목적에 중요한 작업인 방사선 이미지에서 자세하고 정확한 의료 보고서를 생성하는 BiMediX2의 기능을 강조합니다.
read the caption
Table 7: Report Generation (MultiMedEval Royer et al. (2024))
Full paper#














